Posts
-
OpenAI Finals
CommentsOpenAI just beat OG, champions of The International 8, in a 2-0 series. They also announced that in private, they had won three other pro series: 2-0 over Team Lithium, 2-0 over SG e-sports, and 2-0 over Alliance. Pretty cool! I don’t have a lot to add this time, but here are my thoughts.
OG Isn’t the Top Team and That Doesn’t Matter
After pulling off an incredible Cinderella story and winning TI8, OG went through some troubles. My understanding is that they’ve started to recover, but are no longer the consensus best team.
To show this, we can check the GosuGamers DotA 2 rankings. This assigns an lo rating to the top DotA 2 teams, based on their match history in tournaments. At the time of this post, OG is estimated as the 11th best team.
I don’t think this really matters, because as we’ve seen with the 1v1 bot, the previous OpenAI Five match, and with AlphaStar, once your at the level of semi=pro, reaching pro is more a matter of training time and steady incremental training improvements than anything else. Going into the match, I thought the only way OG would have a chance was if the restrictions were radically different from the ones used at TI8. They weren’t. Given that OpenAI Five beat a few other pro teams, I believe this match wasn’t a fluke and there’s no reason they couldn’t beat Secret or VP or VG with enough training time.
Reaction Times Looked More Believable
I’m not sure if OpenAI added extra delay or not, but the bot play we saw felt more fair and looked more like a player with really good mechanics, rather than superhuman mechanics. There were definitely some crazy outplays but it didn’t look impossible for a human to do it - it just looked very, very difficult.
If I had to guess, it would be that the agent still processes input at the same speed, but has some fixed built-in delay between deciding an action and actually executing it. That would let you get more believable reactions without compromising your ability to observe environment changes that are only visible for fractions of a second.
Limited Hero Pool is a Bit Disappointing
I think it’s pretty awesome that OpenAI Five won, but one thing I’m interested by is the potential for AI to explore the hero pool and identify strategies that pro players have overlooked. We saw this in Go with the 3-3 invasion followup. We saw this in AlphaStar, with the strength of well microed Stalkers, although the micro requirements seem very high. With OpenAI Five, we saw that perhaps early buybacks have value, although again, it’s questionable whether this makes sense or whether the bot is just playing weird. (And the bot does play weird, even if it does win anyways.)
When you have a limited hero pool, you can’t learn about unimplemented heroes, and therefore the learned strategies may not generalize to full DotA 2, which limits the insights humans can take away from the bot’s play. And that’s a real shame.
It seems unlikely that we’ll see an expansion of the hero pool, given that this is the last planned public event. It’s a lot more compute for what is already a compute heavy project. It would also require learning how to draft, assuming draft works the same as the TI8 version. In the TI8 version, the win rate of every possible combination of heroes is evaluated, and the draft is done by picking the least exploitable next hero. Given a pool of 17 heroes, there are \(\binom{17}{5}\binom{12}{5}\cdot 2 = 9801792\) different hero combinations, which is small enough to be brute-forced. A full hero pool breaks this quick hack and requires using a learned approach instead. I’m sure it’s doable (there’s existing work for this), but it’s another hurdle that makes it look even more unlikely.
A Million 3k MMR Teams at Five Million Keyboards Have to Win Eventually
At the end of the match, OpenAI announced that they were opening sign-ups to allow everyone to play against or with OpenAI Five. It’s only going to be up for a few days, but it’s still exciting nonetheless. I have no idea how much the inference will cost in cloud credit (which is presumably why it’s only running for a few days).
I fully expect somebody to figure out a cheese strategy that the bot has trouble handling. I also expect every pro team to try beating it for kicks, because if they can beat it consistently, can you imagine how much free PR they’d get? If they don’t beat it, they don’t have to say anything, so it seems like a win-win.
There is a chance that the bot is genuinely too good, in an “AlphaGo Master goes 60-0 against pros” kind of way, but that was 60 games, and way more than 60 people are going to try to beat OpenAI Five. They’re not all going to be pros, but scale is going to matter more than skill here.
When OpenAI let TI attendees play their 1v1 bot that beat several pros, people were able to find all sorts of cheese strategies that worked. It was an older version of the bot, so perhaps history doesn’t have precedence, but I’m going to guess somebody is going to figure out something sufficiently out-of-distribution.
We Still Take Pride in Few Shot Learning
In the interview with Purge after the match, OG N0tail had an interesting comment
Purge: If you guys got to play 5 matches right now against them, do you think you could take at least 1 win?
N0tail: Yeah, for sure. For sure 1 win. If we played 10, we’d start winning more, and if we could play 50 games against them, I believe we’d start winning very very reliably.
He later elaborated that he felt the bot had exploitable flaws in how it played around vision, but I think the more important note is that we take pride in our ability to actively try new things based on very few examples. The debate over how to do this is endless, but it makes me think that if somebody manages to demo impressive few-shot learning, we’ll start running out of excuses about AI.
-
An Overdue Post on AlphaStar, Part 2
CommentsThis is part 2 of my post about AlphaStar, which is focused on the machine learning implications. Click here for part 1.
A Quick Overview of AlphaStar’s Training Setup
It’s impossible to talk about AlphaStar without briefly covering how it works. Most of the details are vague right now, but more have been promised in an upcoming journal article. This summary is based off of what’s public so far.
AlphaStar is made of 3 sequence models that likely share some weights. Each sequence model receives the same observations: the raw game state. There are then three sets of outputs: where to click, what to build/train, and an reward predictor.
This model is trained in a two stage process. First, it is trained using imitation learning on human games provided by Blizzard. My notes from the match say it takes 3 days to train the imitation learning baseline.
The models are then further trained using IMPALA and population-based training, plus some other tricks I’ll get to later. This is called the AlphaStar League. Within the population, each agent is given a slightly different reward function, some of which include rewards for exploiting other specific agents in the league. Each agent in the population is trained with 16 TPUv3s, which are estimated to be equivalent to about 50 GPUs each. The population-based training was run for 14 days.
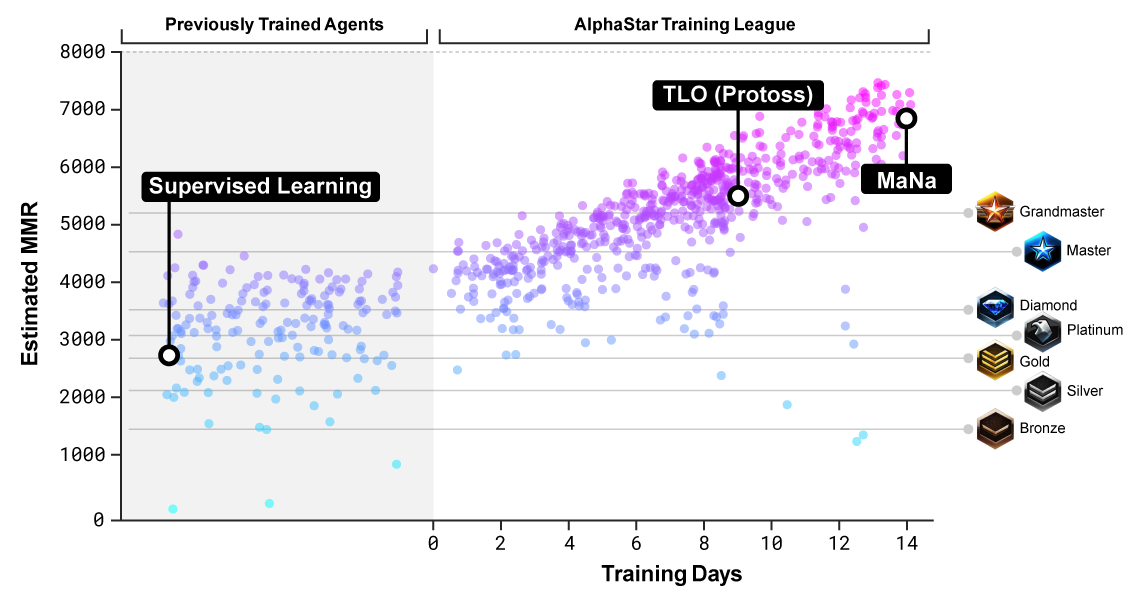
(From original post)
I couldn’t find any references for the population size, or how many agents are trained simultaneously. I would guess “big” and “a lot”, respectively. Now multiply that by 16 TPUs each and you get a sense of the scale involved.
After 14 days, they computed the Nash equilibrium of the population, and for the showmatch, selected the top 5 least exploitable agents, using a different one in every game.
All agents were trained in Protoss vs Protoss mirrors on a fixed map, Catalyst LE.
Takeaways
1. Imitation Learning Did Better Than I Thought
I have always assumed that when comparing imitation learning to reinforcement learning, imitation learning performs better when given fewer samples, but reinforcement learning wins in the long run. We saw that play out here.
One of the problems with imitation learning is the way errors can compound over time. I’m not sure if there’s a formal name for this. I’ve always called it the DAgger problem, because that’s the paper that everyone cites when talking about this problem (Ross et al, AISTATS 2011).
Intuitively, the argument goes like this: suppose you train an agent by doing supervised learning on the actions a human does. This is called behavioral cloning, and is a common baseline in the literature. At \(t=0\), your model acts with small error \(\epsilon_0\). That’s fine. This carries it to state that’s modelled less well, since the expert visited it less often. Now at \(t=1\), it acts with slightly larger error \(\epsilon_1\). This is more troubling, as we’re in a state with even less expert supervision. At \(t=2\), we get a larger error \(\epsilon_2\), at \(t=3\) an even larger \(\epsilon_3\), and so on. As the errors compound over time, the agent goes through states very far from expert behavior, and because we don’t have labels for these states, the agent is soon doing nonsense.
This problem means mistakes in imitation learning often aren’t recoverable, and the temporal nature of the problem means that the longer your episode is, the more likely it is that you enter this negative feedback loop, and the worse you’ll be if you do. You can prove that if the expected loss each timestep is \(\epsilon\), then the worst-case bound over the episode is \(O(T^2\epsilon)\), and for certain loss functions this worst-case bound is tight.
Due to growing quadratically in \(T\), we expect long-horizon tasks to be harder for imitation learning. A StarCraft game is long enough that I didn’t expect imitation learning to work at all. And yet, imitation learning was good enough to reach the level of a Gold player.
The first version of AlphaGo was bootstrapped by doing behavioral cloning on human games, and that version was competitive against top open-source Go engines of the time. But Go is a game with at most 200-250 moves, whereas StarCraft has thousands of decisions points. I assumed that you would need a massive dataset of human games to get past this, more than Blizzard could provide. I’m surprised this wasn’t the case.
My guess is that this is tied into another trend: despite the problems with behavioral cloning, it’s actually a pretty strong baseline. I don’t do imitation learning myself, but that’s what I’ve been hearing. I suspect that’s because many of behavioral cloning’s problems can be covered up with better data collection. Here’s the pseudocode for DAgger’s resolution to the DAgger problem.

Given expert policy \(\pi^*\) and current policy \(\hat{\pi}_i\), we iteratively build a dataset \(\mathcal{D}\) by collecting data from a mixture of the expert \(\pi^*\) and current policy \(\hat{\pi}_i\). We iteratively alternate training policies and collecting data, and by always collecting with a mixture of expert data and on-policy data, we can ensure that our dataset will always include both expert states and states close to ones our current policy would visit.
But importantly, the core optimization loop (the “train classifier” line) is still based on maximizing the likelihood of actions in your dataset. The only change is on how the data is generated. If you have a very large dataset, from a wide variety of experts of varying skill levels (like, say, a corpus of StarCraft games from anyone who’s ever played the game), then it’s possible that your data already has enough variation to let your agent learn how to recover from several of the incorrect decisions it could make.
This is something I’ve anecdotally noticed in my own work. When collecting robot grasping data, we found that datasets collected with small amounts of exploration noise led to significantly stronger policies than datasets without it.
The fact that imitation learning gives a good baseline seems important for bootstrapping learning. It’s true that AlphaZero was able to avoid this, but AlphaGo with imitation learning bootstrapping was developed first. There usually aren’t reasons to discard warm-starting from a good base policy, unless you’re deliberately doing it as a research challenge.
2. Population Based Training is Worth Watching
StarCraft II is inherently a game based around strategies and counter-strategies. My feeling is that in DoTA 2, a heavy portion of your strategy is decided in the drafting phase. Certain hero compositions will only work best for certain styles of play. Because of this, once the draft is done, each team has an idea of what to expect.
However, StarCraft II starts out completely unobserved. Builds can go from heavy early aggression to greedy expansions for long-term payoff. It seems more likely that StarCraft could devolve into unstable equilibria if you try to represent the space of strategies within a single agent.
Population-based training does a lot to avoid this problem. A simple self-play agent “gets stuck”, but a population-based approach reaches Grandmaster level. One of the intuitive traps in self-play is that if you only play against the most recent version of yourself, then you could endlessly walk around a rock-paper-scissors loop, instead of discovering the trick that beats rock, paper, and scissors.
I haven’t tried population based training myself, but from what I heard, it tends to give more gains in unstable learning settings, and it seems likely that StarCraft is one of those games with several viable strategies. If you expect the game’s Nash equilibrium to turn into an ensemble of strategies, it seems way easier to maintain an ensemble of agents, since you get a free inductive prior.
3. Once RL Does Okay, Making It Great Is Easier
In general, big RL projects seem to fall into two buckets.
- They don’t work at all.
- They work and become very good with sufficient compute, which may be very large due to diminishing returns.
I haven’t seen many in-betweens where things start to work, and then hit a disappointingly low plateau.
One model that would explain this is that algorithmic and training tricks are all about adding constant multipliers to how quickly your RL agent can learn new strategies. Early in a project, everything fails, because the learning signal is so weak that nothing happens. With enough tuning, the multipliers become large enough for agents to show signs of life. From there, it’s not like the agent ever forgets how to learn. It’s always capable of learning. It’s just a question of whether the things needed for the next level of play are hard to learn or not.
Humans tend to pick up games easily, then spend forever mastering them. RL seems to have the opposite problem - they pick up games slowly, but then master them with relative ease. This means the gap between blank-slate and pretty-good is actually much larger than the gap between pretty-good and pro-level. The first requires finding what makes learning work. The second just needs more data and training time.
The agent that beat TLO on his offrace was trained for about 7 days. Giving it another 7 days was enough to beat MaNa on his main race. Sure, double the compute is a lot of compute, but the first success took almost three years of research time and the second success took seven days. Similarly, although OpenAI’s DotA 2 agent lost against a pro team, they were able to beat their old agent 80% of the time with 10 dats of training. Wonder where it’s at now…
4. We Should Be Tossing Techniques Together More Often
One thing I found surprising about the AlphaStar architecture is how much stuff goes into it. Here’s a list of papers referenced for the model architecture. I’ve added links to everything that’s non-standard.
- A transformer is used to do self-attention (Vaswani et al, NeurIPS 2017).
- This self-attention is used to add inductive biases to the architecture for learning relations between objects (Zambaldi et al, to be presented at ICLR 2019).
- The self-attention layers are combined with an LSTM.
- The policy is auto-regressive, meaning it predicts each action dimension conditionally on each previous action dimension.
-
This also uses a pointer network (Vinyals et al, NeurIPS 2015), which more easily supports variable length outputs for variable length inputs.

Diagram of PointerNet from original paper. A conventional RNN-based seq2seq model condtionally predicts output from the latent code. A PointerNet outputs attention vectors over its inputs.
My guess for why a pointer net helps is that StarCraft involves controlling many units in concert, and the number of units changes over the game. Given that you need to output an action for each unit, a pointer network is a natural choice.
-
The model then uses a centralized value baseline, linking a counterfactual policy gradient algorithm for multi-agent learning (Foerster et al, AAAI 2018).
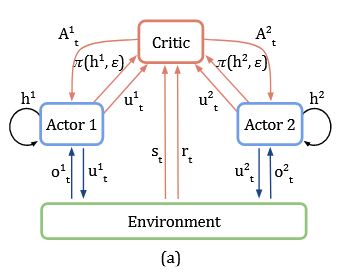
Diagram of counterfactual multi-agent (COMA) architecture, from original paper. Instead of having a separate actor-critic pair for each agent, all agents share the same critic and get per-agent advantage estimates by marginalizing over the appropriate action.
This is just for the model architecture. There are a few more references for the training itself.
- It’s trained with IMPALA (Espeholt et al, 2018).
- It also uses experience replay.
- And self-imitation learning (Oh et al, ICML 2018).
- And policy distillation in some way (Rusu et al, ICLR 2016).
- Which is trained with population-based training (Jaderberg et al, 2018).
- And a reference to Game-Theoretic Approaches to Multiagent RL (Lanctot et al, NeurIPS 2017). I’m not sure where this is used. Possibly for adding new agents to the AlphaStar league that are tuned to learn the best response to existing agents?
Many of these techniques were developed just in the last year. Based on the number of self-DeepMind citations, and how often those papers report results on the StarCraft II Learning Environment, it’s possible much of this was developed specifically for the StarCraft project.
When developing ML research for a paper, there are heavy incentives to change as little as possible, and concentrate all risk on your proposed improvement. There are many good reasons for this. It’s good science to change just one variable at a time. By sticking closer to existing work, it’s easier to find previously run baselines. It’s also easier for other to validate your work. However, this means that there are good reasons not to incorporate prior state-of-the-art techniques into your research project. The risk added makes the cost-benefit analysis unfavorable.
This is a shame, because ML is a very prolific field, and yet there isn’t a lot of cross-paper pollination. I’ve always liked the Rainbow DQN paper (Hessel et al, AAAI 2018), just because it asked what would happen if you tossed everything together. AlphaStar feels like something similar: several promising ideas that combine into a significantly stronger state-of-the-art.
These sorts of papers are really useful for verifying what techniques are worth using and which ones aren’t, because distributed evaluation across tasks and settings is really the only way we get confidence that a paper is actually useful. But if the incentives discourage adding more risk to research projects, then very few techniques get this distributed evaluation. Where does that leave us? It is incredibly certain that the existing pieces of machine learning can do something we think it can’t, and the only blocker is that no one’s tried the right combination of techniques.
I wonder if the endgame is that research will turn into a two-class structure. One class of research will be bottom-up, studying well-known baselines, without a lot of crossover with other papers, proposing many ideas of which 90% will be useless. The other class will be top-down, done for the sake of achieving something new on an unsolved problem, finding the 10% of useful ideas with trial-and-error and using scale to punch through any barriers that only need scale to solve.
Maybe we’re already in that endgame. If so, I don’t know how I feel about that.
Predictions
In 2016, shortly after the AlphaGo vs Lee Sedol match, I got into a conversation with someone about AGI timelines. (Because, of course, whenever ML does something new, some people will immediately debate what it means for AGI.) They thought AGI was happening very soon. I thought it wasn’t, and as an exercise they asked what would change my mind.
I told them that given that DeepMind was working on StarCraft II, if they beat a pro player within a year, I’d have to seriously revise my assumptions on the pace of ML progress. I thought it would take five to ten years.
The first win in the AlphaGo vs Lee Sedol match was on March 9, 2016, and the MaNa match was announced January 24, 2019. It took DeepMind just shy of three years to do it.
The last time I took an AI predictions questionnaire, it only asked about moonshot AI projects. Accordingly, almost all of my guesses were at least 10 years in the future. None of what they asked has happened yet, so it’s unclear to me if I’m poorly calibrated on moonshots or not - I won’t be able to know for sure until 10 years have passed!
This is probably why people don’t like debating with futurists who only make long-term predictions. Luckily, I don’t deal with people like that very often.
To try to avoid this problem with AlphaStar, let me make some one-year predictions.
If no restrictions are added besides no global camera, I think within a year AlphaStar will be able to beat any pro, in any matchup, on any set of maps in a best-of-five series.
So far, AlphaStar only uses a single map and a single PvP match. I see no reason why a similar technique wouldn’t generalize to other maps or races if given more time. The Reddit AMA says that AlphaStar already does okay on maps it wasn’t trained on, suggesting the model can learn core, generalizable features of StarCraft.
Other races are also definitively on DeepMind’s roadmap. I’ve read some theories that claimed DeepMind started at Terran, but moved to Protoss because their agents would keep lifting up their buildings early on in training. That could be tricky, but doesn’t sound impossible.
The final showmatch against MaNa did expose a weakness where AlphaStar didn’t know how to deal with drops, wasting time moving its army back and forth across the map. Now that this problem is a known quantity, I expect it to get resolved by the next showmatch.
If restrictions are added to make AlphaStar’s gameplay look more human, I’m less certain what will happen. It would depend on what the added restrictions were. The most likely restriction is one on burst APM. Let’s say a cap of 700 burst APM, as that seems roughly in line with MaNa’s numbers. If a 700 burst APM restriction is added, it’s less likely AlphaStar will be that good in a year, but it’s still at least over 50%. My suspicion is that existing strategies will falter with tighter APM limits. I also suspect that with enough time, population-based training will find strategies that are still effective.
One thing a few friends have mentioned is that they’d like to see extended games of a single AlphaStar agent against a pro, rather than picking a different agent every game. This would test whether a pro can quickly learn to exploit that agent, and whether the agent adapts its strategy based on its opponent’s strategy. I’d like to see this too, but it seems like a strictly harder problem than using a different agent from the ensemble for each game, and I don’t see reasons for DeepMind to switch off the ensemble. I predict we won’t see any changes on this front.
Overall, nothing I saw made me believe we’ve seen the limit of what AlphaStar can do.
Thanks to the following people for reading drafts of this post: Tom Brown, Jared Quincy Davis, Peter Gao, David Krueger, Bai Li, Sherjil Ozair, Rohin Shah, Mimee Xu, and everyone else who preferred staying anonymous.
-
An Overdue Post on AlphaStar, Part 1
CommentsIn late January, DeepMind broadcasted a demonstration of their StarCraft II agent AlphaStar. In Protoss v Protoss mirrors on a map used in pro play (Catalyst LE), it successfully beat two pro players from TeamLiquid, TLO (a Zerg player) and MaNa (a Protoss player).
This made waves in both the StarCraft and machine learning communities. I’m mostly an ML person, but I played a lot of casual Brood War growing up and used to follow the Brood War and SC2 pro scene.
As such, this is a two-part post. The first is a high-level overview of my reactions to the AlphaStar match and other people’s reactions to the match. The second part, linked here, is a more detailed discussion of what AlphaStar means for machine learning.
In other words, if you’re interested in deep dives into AlphaStar’s StarCraft strategy, you may want to read something else. I recommend this analysis video by Artosis and this VOD of MaNa’s livestream about AlphaStar.
The DeepMind blog post for AlphaStar is pretty extensive, and I’ll be assuming you’ve read that already, since I’ll be referring to sections of it throughout the post.
The Initial Impact
It was never a secret that DeepMind was working on StarCraft II. One of the first things mentioned after the AlphaGo vs Lee Sedol match was that DeepMind was planning to look at StarCraft. They’ve given talks at BlizzCon, helped develop the SC2 learning environment, and published a few papers about training agents in StarCraft II minigames. It was always a matter of time.
For this reason, it hasn’t made as big an impact on me as OpenAI’s 1v1 DotA 2 bot. The key difference isn’t how impressive the results were, it was how surprising it was to hear about them. No one knew OpenAI was looking at DotA 2, until they announced they had beaten a top player in 1v1 (with conditions). Even for AlphaGo, DeepMind published a paper on Go evaluation over a year before the AlphaGo Nature paper (Maddison et al, ICLR 2015). It was on the horizon if you saw the right signs (see my post on AlphaGo if curious).
StarCraft II has had a steady stream of progress reports, and that’s lessened the shock of the initial impact. When you know a team has been working on StarCraft for several years, and Demis Hassabis tweets that the SC2 demonstration will be worth watching…well, it’s hard not to expect something to happen.
In his post-match livestream, MaNa relayed a story about his DeepMind visit. In retrospect, given how many hints there were, it’s funny to hear how far they went to conceal how strong AlphaStar was in the days up to the event.
Me [MaNa] and TLO are going to be representing TeamLiquid, right? They wanted to make sure there wasn’t any kind of leak about the event, or what kind of show they were putting on. Around the office, we had to cover ourselves with DeepMind hoodies, because me and TLO are representing TeamLiquid, with the TeamLiquid hoodie and TeamLiquid T-shirt. We walk in day one and the project managers are like, “NOOOO, don’t do that, don’t spoil it, people will see! Here are some DeepMind hoodies, do you have a normal T-shirt?”, and me and TLO are walking in with TeamLiquid gear. We didn’t know they wanted to keep it that spoiler-free.
To be fair, the question was never about whether DeepMind had positive results. It was about how strong their results were. On that front, they successfully hid their progress, and I was surprised at how strong the agent was.
How Did AlphaStar Win?
Here is an incredibly oversimplified explanation of StarCraft II.
- Each player starts with some workers and a home base. Workers can collect resources, and the home base can spend resources to build more workers.
- Workers can spend resources to build other buildings that produce stronger units, upgrade your existing units, or provide static defenses.
- The goal is to destroy all your opponent’s buildings.
Within this is a large pool of potential strategy. For example, one thing workers can do is build new bases. This is called expanding, and it gives you more economy long run, but the earlier you expand, the more open you are to aggression.
AlphaStar’s style, so to speak, seems to trend in these directions.
- Never stop building workers, even when it delays building your first expansion.
- Build lots of Stalkers and micro them to flank and harass the enemy army until it’s weak enough to lose to an all-in engagement. Stalkers are one of the first units you can build, and can hit both ground and air units from range. They also have a Blink ability that lets them quickly jump in and out of battle.
- Support those Stalkers with a few other units.
From the minimal research I’ve done, none of these strategies are entirely new, but AlphaStar pushed the limits of these strategies to new places. Players have massed workers in the past, but they’ll often stop before hitting peak mining capacity, due to marginal returns on workers. Building workers all the way to the mining cap delays your first expansion, but it also provides redundancy against worker harass, so it’s not an unreasonable strategy.
Similarly, Stalkers have always been a core Protoss unit, but they eventually get countered by Immortals. AlphaStar seems to play around this counter by using exceptional Stalker micro to force early wins through a timing push.
It’s a bit early to tell whether humans should be copying these strategies. The heavy Stalker build may only be viable with superhuman micro (more on this later). Still, it’s exciting that it’s debatable in the first place.
Below is a diagram from the blog post, visualizing the number of each unit the learned agents create as a function of training time. We see that Stalkers and Zealots dominate the curve. This isn’t surprising, since Stalkers and Zealots are the first attacking units you can build, and even if you’re planning to use other units, you still need some Stalkers or Zealots for defense.

I believe this is the first StarCraft II agent that learns unit compositions. The previous leading agent was one developed by Tencent (Sun et al, 2018), which followed human-designed unit compositions.
The StarCraft AI Effect
One of the running themes in machine learning is that whenever somebody gets an AI to do something new, others immediately find a reason to say it’s not a big deal. This is done either by claiming that the task solved doesn’t require intelligence, or by homing in on some inhuman aspect of how the AI works. For example, the first chess AIs won thanks to large game tree searches and lots of human-provided knowledge. So you can discount chess AIs by claiming that large tree searches don’t count as intelligence.
The same thing has happened with AlphaStar. Thanks to the wonders of livestreaming and Reddit, I was able to see this live, and boy was that a sight to behold. It reminded me of the routine “Everything is Amazing, and Nobody’s Happy”. (I understand that Louis C.K. has a lot of baggage these days, but I haven’t found another clip that expresses the right sentiment, so I’m using it anyways.)
I do think some of the criticisms are fair. The criticisms revolved around two points: the global camera, and AlphaStar’s APM.
I’m deferring details of AlphaStar’s architecture to part 2, but the short version is that AlphaStar is allowed to observe everything within vision of units it controls. By contrast, humans can only observe the minimap and the units on their screen, and must move the camera around to see other things.
There’s one match where MaNa tried building Dark Templars, and the instant they walked into AlphaStar’s range, it immediately started building Observers to counter them. A human wouldn’t be able to react to Dark Templars that quickly. This is further complicated by AlphaStar receiving raw game state instead of the visual render. Getting raw game state likely makes it easier to precisely focus-fire units without overkill, and also heavily nerfs cloak in general. The way cloaking works in StarCraft is that cloaked units are untargetable, but you can spot faint shimmers wherever there’s a cloaked unit. With proper vigilance, you can spot cloaked units, but it’s easy to miss them with everything else you need to focus on. AlphaStar doesn’t have to spot the on-screen shimmer of cloak, since the raw game state simply says “Dark Templar, cloaked, at position (x,y).”
The raw game state seems like an almost unfixable problem (unless you want to go down the computer vision rabbit hole), but it’s not that bad compared to the global camera. For what it’s worth, DeepMind trained a new agent without the global camera for the final showmatch, and I assume the global camera will not be used in any future pro matches.
The more significant controversy is around AlphaStar’s APM. On average, AlphaStar acts at 280 actions per minute, less than pro play, but this isn’t the full picture. According to the Reddit AMA, the limitation is at most 600 APM every 5 seconds, 400 APM every 15 seconds, and 300 APM every 60 seconds. This was done to model both average pro APM and burst APM, since humans can often reach high peak APM in micro-intensive situations. During the match itself, viewers spotted that AlphaStar’s burst APM sometimes reached 900 or even 1500 APM, far above what we’ve seen from any human.
These stats are backed up by the APM chart: AlphaStar’s average APM is smaller than MaNa’s, but has a longer tail.

Note that TLO’s APM numbers are inflated because the key bindings he uses leads to lots of phantom actions that don’t do anything. MaNa’s numbers are more reflective of pro human APM,
I mentioned earlier that AlphaStar really likes Stalkers. At times, it felt like AlphaStar was building Stalkers in pure defiance of common sense, and it worked anyways because it had such effective blink micro. This was most on display in game 4, where AlphaStar used Stalkers to whittle down MaNa’s Immortals, eventually destroying all of them in a game-ending victory. (Starts at 1:37:46.)
I saw a bunch of people complaining about the superhuman micro of AlphaStar, and how it wasn’t fair. And yes, it isn’t. But it’s worth noting that before AlphaStar, it was still an open question whether bots could beat pro players at all, with no restrictions on APM. What, is the defeat of a pro player in any capacity at all not cool enough? Did Stalker blink micro stop being fun to watch? Are you not entertained? Why is this such a big deal?
What’s Up With APM?
After thinking about the question, I have a few theories for why people care about APM so much.
First, StarCraft is notorious for its high APM at the professional level. This started back in Brood War, where people shared absurd demonstrations of how fast Korean pro players were with their execution.
It’s accepted wisdom that if you’re a StarCraft pro, you have to have high APM. This is to the point where many outsiders are scared by StarCraft because they think you have to have high APM to have any fun playing StarCraft at all. Without the APM to make your units do what you want them to do, you won’t have time to think about any of the strategy that makes StarCraft interesting.
This is wrong, and the best argument against it is the one Day[9] gave on the eve of the release of StarCraft: Brood War Remastered (starts at 4:30).
There is this illusion that in Brood War, you need to be excellent at your mechanics before you get to be able to do the strategy. There is this idea that if you practice for three months, you’ll have your mechanics down and then get to play the strategy portion. This is totally false. […] If you watch any pro play, stuff is going wrong all the time. They’re losing track of drop ships and missing macro back at home and they have a geyser with 1 dude in it and they forget to expand. Stuff’s going wrong all the time, because it’s hard to be a commander.
This execution difficulty is an important human element of gameplay. You can only go so fast, and can’t do everything at once, so you have to choose where to focus your efforts.
But a computer can do everything at once. I assume a lot of pros would find it unsatisfying if supreme micro was the only way computers could compete with pros at StarCraft.
Second, micro is the flashiest and most visible StarCraft skill. Any StarCraft highlight reel will have a moment where one player’s ridiculous micro lets them barely win a fight they should have lost. For many people, micro is what makes StarCraft a good competitive game, because it’s a way for the better player to leverage their skill to win. And from a spectator perspective, these micro fights are the most exciting parts of the game.
The fact that micro is so obvious matters for the third and final theory: DeepMind started by saying their agent acted within human parameters for APM, and then broke the implicit contract.
Everything DeepMind said was true. AlphaStar’s average APM is under pro average APM. They did consult with pros to decide what APM limits to use. When this is all mentioned to the viewer, it comes with a bunch of implications. Among them is the assumption that the fight will be fair, and that AlphaStar will not do things that humans can’t do. AlphaStar will play in ways that look like a very good pro.
Then, AlphaStar does something superhuman with its micro. Now, the fact that this is within APM limits that pros thought were reasonable doesn’t matter. What matters is that the implied contract was broken, and that’s where people got mad. And because micro is so obvious to the viewer, it’s very easy to see why people were mad. I claim that if AlphaStar had used thousands of APM at all times, people wouldn’t have been upset, because DeepMind never would have claimed AlphaStar’s APM was within human limits, and everyone would have accepted AlphaStar’s behavior as the way things were.
We saw a similar thing play out in the OpenAI Five showcase. The DotA team said that OpenAI Five had 250ms reaction times, within human limits. One of the humans picked Axe, aiming for Blink-Call engages. OpenAI Five would insta-Hex Axe every time they blinked into range, completely negating that strategy. We would never expect humans to do this consistently, and questions about reaction time were among the first questions asked in the Q&A section.
I feel people are missing the wider picture: we can now train ML models that can play StarCraft II at Grandmaster level. It is entirely natural to ask for more restrictions, now that we’ve seen what AlphaStar can do, but I’d ask people not to look down on what AlphaStar has already done. StarCraft II is a hard enough problem that any success should be celebrated, even if the end goal is to build an agent more human-like in its behavior.
APM does matter. Assuming all other skills are equal, the player with higher APM is going to win, because they can execute things with more speed and precision. But APM is nothing without a strategy behind it. This should be obvious if you look at existing StarCraft bots, that use thousands of APM and yet are nowhere near pro level. Turns out learning StarCraft strategy is hard!
If anything, I find it very impressive that AlphaStar is actually making good decisions with the APM it has. “Micro” involves a lot of rapid, small-scale decisions about whether to engage or disengage, based off context about what units are around, who has the better position and composition, and guesses on where the rest of your opponent’s army is. It’s hard.
For this reason, I didn’t find AlphaStar’s micro that upsetting. The understanding displayed of when to advance and when to retreat was impressive enough to me, and watching AlphaStar micro three groups of Stalkers to simultaneously do hit-and-runs on MaNa’s army was incredibly entertaining.
At the same time, I could see it getting old. When fighting micro of that caliber, it’s hard to see how MaNa has a chance.
Still, it seems like an easy fix: tighten some of the APM bounds, maybe include limitations at smaller granularity (say 1 second) to limit burst APM, and see what happens. If Stalker micro really is a crutch that prevents it from learning stronger strategies, tighter limits should force AlphaStar to learn something new. (And if AlphaStar doesn’t have to do this, then that would be good to know too.)
What’s Next?
DeepMind is free to do what they want with AlphaStar. I suspect they’ll try to address the concerns people have brought up, and won’t stop until they’ve removed any doubt over ML’s ability to beat pro StarCraft II players with reasonable conditions.
There are times where people in game communities worry that big companies are building game AIs purely as a PR stunt, and that they don’t appreciate the beauty in competitive play. I’ve found this is almost always false, and the same is true here.
Let me put it this way: one of the faces of the project is Oriol Vinyals. Based on a 35 Under 35 segment in the MIT Technology Review, Oriol used to be the best Brood War player in Spain. Then, he worked on a StarCraft AI at UC Berkeley. Eventually, he joined DeepMind and started working on AlphaStar.
So yeah, I don’t think the AlphaStar team is looking at StarCraft as just another game to conquer. I think they genuinely love the game and won’t stop until AlphaStar is both better than everyone and able to teach us something new about StarCraft II.