Posts
-
Solving Crew Battle Strategy With Math
CommentsIn Super Smash Bros tournaments, there’s occasionally an event called a crew battle. (They show up in other fighting games too, but I mostly watch Smash.) Two teams of players compete in a series of 1v1 matches. For the first match, each team picks a player simultaneously. They fight, and the loser is eliminated, while the winner stays in. The losing team then picks a player to go in. Elimination matches repeat until one team is out of players.
These events are always pretty hype. People like team sports! They’re also often structured in a regional way (i.e. US vs Japan, West Coast vs East Coast), which can emphasize and play up regional rivalries. The strategy for deciding who to send in can be complicated, and although it’s usually done by intuition, I’ve always wondered what optimal strategy would be.
The reason it’s complicated is that fighting game character matchups aren’t perfectly balanced. Some characters counter other characters. Sometimes players are unusually good at a specific matchup - a Fox v Fox matchup is theoretically 50-50 but some players have earned a reputation for being really good at Fox dittos. And how about generic player strength? Typical rule of thumb is to keep your strongest player (the anchor) for last, because the last player faces the most psychological pressure. But if we ignored those factors, is that actually correct? When do you send in your 2nd strongest player, or weakest player? What is the optimal crew battle strategy?
Theory
Let’s formalize the problem a bit. For the sake of simplicity, I will ignore that Smash games have stocks, and assume each match is a total win or loss. I expect the conclusions to be similar anyways.
Let’s call the teams \(A\) and \(B\). There are \(n\) players on each team, denoted as \(\{a_1, a_2, \cdots, a_n\}\) and \(\{b_1, b_2, \cdots, b_n\}\). Each player has a certain chance of beating each other player which can be described as an \(n \times n\) matrix of probabilities, where row \(i\) column \(j\) is the probability \(a_i\) beats \(b_j\). We’ll denote that as \(\Pr(a_i > b_j)\). This matrix doesn’t need to be symmetric, or have its rows or columns sum to 1.
\[\begin{bmatrix} \Pr(a_1 > b_1) & \Pr(a_1 > b_2) & \cdots & \Pr(a_1 > b_n) \\ \Pr(a_2 > b_1) & \Pr(a_2 > b_2) & \cdots & \Pr(a_2 > b_n) \\ \vdots & \vdots & \ddots & \vdots \\ \Pr(a_n > b_1) & \Pr(a_n > b_2) & \cdots & \Pr(a_n > b_n) \end{bmatrix}\]We’ll call this the matchup matrix. Each team knows the matchup matrix, and has a goal of maximizing their team’s win probability. To make this concrete, we could take the example of a rock-paper-scissors crew battle. Each team has 3 players: a rock player, a paper player, and a scissors player. That would give the following matchup matrix.
\[\begin{array}{c|ccc} & \textbf{rock} & \textbf{paper} & \textbf{scissors} \\ \hline \textbf{rock} & 0.5 & 0 & 1 \\ \textbf{paper} & 1 & 0.5 & 0 \\ \textbf{scissors} & 0 & 1 & 0.5 \end{array}\]Normally, in RPS you’d play again on a tie. Since there are no ties in crew battles, we’ll instead say that if both players match, we pick a winner randomly. Here’s an example game:
A picks rock, B picks scissors A rock beats B scissors B sends in paper A rock loses to B paper A sends in scissors A scissors beats B paper B sends in rock A scissors loses to B rock A sends in paper A paper beats B rock B is out of players - A wins.
This is a pretty silly crew battle because of the lack of drama, but we’ll come back to this example later.
First off: given a generic matchup matrix, should we expect there to be an efficient algorithm that solves the crew battle?
My suspicion is, probably not. Finding the optimal strategy is at some level similar to picking the optimal order of the \(N\) players on each team, which immediately sets off travelling salesman alarm bells in my head. Solving crew battles seems like a strictly harder version of solving regular matrix payoff games, where you only have 1 round of play, and a quick search I did indicates those are already suspected to be hard to solve generally. (See Daskalakis, Goldberg, Papadimitriou 2009 if curious.)
(July 2024 correction: This isn’t exactly relevant. The Daskalakis result is about general matrix payoffs, but crew battles are zero-sum. The Nash equilibria in zero-sum games are efficiently computable via linear programming in time polynomial in the number of actions. Thanks Jon Schneider for the correction. Both he and I believe crew battles are still hard in general, but more because of the exponentially large action space than matrix payoff hardness.)
Even though there isn’t an efficient algorithm, there definitely is an algorithm. Let’s define a function \(f\), where \(f(p, team, S_A, S_B)\) is the probability team \(A\) wins if
- The player who just won is \(p\).
- The team deciding to who to send in is \(team\) (the team that \(p\) is not on).
- \(S_A\) is the set of players left on team A, ignoring player \(p\).
- \(S_B\) is the set of players left on team B, ignoring player \(p\).
Such an \(f\) can be defined recursively. Here are the base cases.
- If \(team = A\) and \(S_A\) is empty, then \(f(p, team, S_A, S_B) = 0\), since A has lost due to having 0 players left.
- If \(team = B\) and \(S_B\) is empty, then \(f(p, team, S_A, S_B) = 1\), since A has won due to B having 0 players left.
(One clarification: the crew battle is not necessarily over if \(S_A\) or \(S_B\) is empty. When a team is on their last player, they will have 0 players left to send in, but their last player could still beat the entire other team if they play well enough.)
Here are the recursive cases.
\[\begin{align*} f(a_i, B, S_A, S_B) = \min_{j \in S_B} & \Pr(a_i > b_j) f(a_i, B, S_A, S_B - \{b_j\}) \\ & + (1-\Pr(a_i > b_j)) f(b_j, A, S_A, S_B - \{b_j\}) \end{align*}\](It is Team B’s turn. They want to play the player \(b_j\) that minimizes the probability that team A wins. The current player will either stay as \(a_i\) or change to \(b_j\).)
\[\begin{align*} f(b_j, A, S_A, S_B) = \max_{i \in S_A} & \Pr(a_i > b_j) f(a_i, B, S_A - \{a_i\}, S_B) \\ & + (1-\Pr(a_i > b_j)) f(b_j, A, S_A - \{a_i\}, S_B) \end{align*}\](The reverse, where it’s team A’s turn and they want to maximize the probability A wins.)
Computing this \(f\) can be done with dynamic programming, in \(O(n^22^{2n})\) time. That’s not going to work at big scales, but I only want to study teams of like, 3-5 players, so this is totally doable.
One neat thing about crew battles is that after the first match, it turns into a turn-based perfect information game. Sure, the outcome of each match is random, but once it’s your turn, the opposing team is locked into their player. That means we don’t have to consider strategies that randomly pick among the remaining players - there will be exactly one reply that’s best. And that means the probability of winning the crew battle assuming optimal play is locked in as soon as the first match is known.
This means we can reduce all the crew battle outcomes down to a single \(n \times n\) matrix, which I’ll call the crew battle matrix. Let \(C\) be that matrix. Each entry \(C_{ij}\) in the crew battle matrix is the probability that team A wins the crew battle, if in the very first match A sends in \(a_i\) and B send in \(b_j\).
\[\begin{align*} C_{ij} = &\Pr(a_i > b_j) f(a_i, B, S_A - \{a_i\}, S_B - \{b_j\}) \\ &+ (1-\Pr(a_i, b_j)) f(b_j, A, S_A - \{a_i\}, S_B - \{b_j\}) \end{align*}\] \[C = \begin{bmatrix} C_{11} & C_{12} & \cdots & C_{1n} \\ C_{21} & C_{22} & \cdots & C_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ C_{n1} & C_{n2} & \cdots & C_{nn} \end{bmatrix}\]This turns our original more complicated problem into exactly a 1 round matrix game like prisoner’s dilemma or stag hunt…assuming we have \(f\). But computing \(f\) by hand is really annoying, and likely does not have a closed form. There’s no way to get \(f\) computed for arbitrary crew battles unless we use code.
So I Wrote Some Python Code to Compute \(f\) for Arbitrary Crew Battles
Let’s consider the RPS crew battle again. Here’s the matchup matrix:
\[matchup: \begin{array}{c|ccc} & \textbf{rock} & \textbf{paper} & \textbf{scissors} \\ \hline \textbf{rock} & 0.5 & 0 & 1 \\ \textbf{paper} & 1 & 0.5 & 0 \\ \textbf{scissors} & 0 & 1 & 0.5 \end{array}\]and here’s what my code outputs for the crew battle matrix, assuming optimal play.
\[crew battle: \begin{array}{c|ccc} & \textbf{rock} & \textbf{paper} & \textbf{scissors} \\ \hline \textbf{rock} & 0.5 & 0 & 1 \\ \textbf{paper} & 1 & 0.5 & 0 \\ \textbf{scissors} & 0 & 1 & 0.5 \end{array}\]No, that’s not a typo. The two are identical! Let’s consider a crew battle of “noisy RPS”, where rock is only favored to beat scissors, rather than 100% to win, and so on.
\[matchup: \begin{array}{c|ccc} & \textbf{rock} & \textbf{paper} & \textbf{scissors} \\ \hline \textbf{rock} & 0.5 & 0.3 & 0.7 \\ \textbf{paper} & 0.7 & 0.5 & 0.3 \\ \textbf{scissors} & 0.3 & 0.7 & 0.5 \end{array}\] \[crew battle: \begin{array}{c|ccc} & \textbf{rock} & \textbf{paper} & \textbf{scissors} \\ \hline \textbf{rock} & 0.500 & 0.399 & 0.601 \\ \textbf{paper} & 0.601 & 0.500 & 0.399 \\ \textbf{scissors} & 0.399 & 0.601 & 0.500 \\ \end{array}\]Intuitively, I feel it makes sense that this pulls towards the original RPS matrix - in some sense, the crew battle is like playing 3 rounds of RPS instead of 1, just with more complicated restrictions.
Here’s the log of a sample game.
Game start, A = rock B = scissors Win prob for A is 0.601 A = rock beats B = scissors If B sends in paper: A wins 0.729 If B sends in rock: A wins 0.776 B sends in paper A = rock beats B = paper If B sends in rock: A wins 0.895 B sends in rock A = rock beats B = rock B has no more players A wins
Bad beat for team B here, getting entirely swept by rock.
For good measure, here’s a random matchup matrix and the corresponding game matrix.
\[matchup: \begin{array}{c|ccc} & \textbf{b}_1 & \textbf{b}_2 & \textbf{b}_3 \\ \hline \textbf{a}_1 & 0.733 & 0.666 & 0.751 \\ \textbf{a}_2 & 0.946 & 0.325 & 0.076 \\ \textbf{a}_3 & 0.886 & 0.903 & 0.089 \\ \end{array}\] \[crew battle: \begin{array}{c|ccc} & \textbf{b}_1 & \textbf{b}_2 & \textbf{b}_3 \\ \hline \textbf{a}_1 & 0.449 & 0.459 & 0.757 \\ \textbf{a}_2 & 0.748 & 0.631 & 0.722 \\ \textbf{a}_3 & 0.610 & 0.746 & 0.535 \\ \end{array}\]Alright. Let’s try something new. What if all player matchups are transitive? Suppose each player has a certain power level \(p\), and if players of power levels \(p\) and \(q\) fight, the power level \(p\) player wins \(p/(p+q)\) of the time. Below is a random matchup matrix following this rule. I’ve sorted the players such that \(a_1\) and \(b_1\) are weakest, while \(a_3\) and \(b_3\) are strongest. Since the matchup matrix is the win probability of A, the values go down when reading across a row (fighting better B players), and up when going down a column (fighting better A players)
\[matchup: \begin{array}{c|ccc} & \textbf{b}_1 & \textbf{b}_2 & \textbf{b}_3 \\ \hline \textbf{a}_1 & 0.289 & 0.199 & 0.142 \\ \textbf{a}_2 & 0.585 & 0.462 & 0.365 \\ \textbf{a}_3 & 0.683 & 0.568 & 0.468 \\ \end{array}\] \[crew battle: \begin{array}{c|ccc} & \textbf{b}_1 & \textbf{b}_2 & \textbf{b}_3 \\ \hline \textbf{a}_1 & 0.385 & 0.385 & 0.385 \\ \textbf{a}_2 & 0.385 & 0.385 & 0.385 \\ \textbf{a}_3 & 0.385 & 0.385 & 0.385 \\ \end{array}\]…Huh. This suggests it doesn’t matter who each team sends out first. The probability of winning the crew battle is the same. Trying this with several random 3x3s reveals the same pattern.
Maybe this is just because 3-player crew battles are weird? Let’s try this on a 5-player crew battle.
\[matchup: \begin{array}{c|ccccc} & \textbf{b}_1 & \textbf{b}_2 & \textbf{b}_3 & \textbf{b}_4 & \textbf{b}_5 \\ \hline \textbf{a}_1 & 0.715 & 0.706 & 0.564 & 0.491 & 0.340 \\ \textbf{a}_2 & 0.732 & 0.723 & 0.584 & 0.511 & 0.358 \\ \textbf{a}_3 & 0.790 & 0.782 & 0.659 & 0.591 & 0.435 \\ \textbf{a}_4 & 0.801 & 0.794 & 0.675 & 0.608 & 0.453 \\ \textbf{a}_5 & 0.807 & 0.800 & 0.682 & 0.616 & 0.461 \\ \end{array}\] \[crew battle: \begin{array}{c|ccccc} & \textbf{b}_1 & \textbf{b}_2 & \textbf{b}_3 & \textbf{b}_4 & \textbf{b}_5 \\ \hline \textbf{a}_1 & 0.731 & 0.731 & 0.731 & 0.731 & 0.731 \\ \textbf{a}_2 & 0.731 & 0.731 & 0.731 & 0.731 & 0.731 \\ \textbf{a}_3 & 0.731 & 0.731 & 0.731 & 0.731 & 0.731 \\ \textbf{a}_4 & 0.731 & 0.731 & 0.731 & 0.731 & 0.731 \\ \textbf{a}_5 & 0.731 & 0.731 & 0.731 & 0.731 & 0.731 \\ \end{array}\]Same thing occurs! Let’s play a sample game. Even if the win probability is the same no matter who starts, surely the choice of who to send out in the future matches matter.
Game start, A = 1 B = 2 Win prob for A is 0.731 A = 1 beats B = 2 If B sends in 0: A wins 0.804 If B sends in 1: A wins 0.804 If B sends in 3: A wins 0.804 If B sends in 4: A wins 0.804 B sends in 0 A = 1 beats B = 0 If B sends in 1: A wins 0.836 If B sends in 3: A wins 0.836 If B sends in 4: A wins 0.836 B sends in 1 A = 1 loses B = 1 If A sends in 0: A wins 0.759 If A sends in 2: A wins 0.759 If A sends in 3: A wins 0.759 If A sends in 4: A wins 0.759 A sends in 0 A = 0 beats B = 1 If B sends in 4: A wins 0.800 If B sends in 3: A wins 0.800 B sends in 4 A = 0 beats B = 4 If B sends in 3: A wins 0.969 B sends in 3 A = 0 beats B = 3 B has no more players A wins
The probability of A winning the crew battles shifts as matches are decided in favor of A or B, but the win probability does not change for any of the choices.
I found this pretty surprising! Going into this I assumed there would be some rule of thumb tied to difference in skill level. I certainly didn’t expect it to not matter at all. This result does depend on how we’ve modeled skill, that player with skill \(p\) beats player with skill \(q\) with probability \(p/(p+q)\). However, this model is very common. It’s called the Bradley-Terry model and is the basis of Elo ratings. (And the basis for tuning AI chatbot responses based on human feedback.)
Let’s write up this observation more formally.
Conjecture: Suppose you have an \(N\) player crew battle, with players \(A = \{a_1, a_2, \cdots, a_N\}\) and \(B = \{b_1, b_2, \cdots, b_N\}\). Further suppose each player has a non-negative skill level \(p\), and every matchup follows \(\Pr(a_i > b_j) = p_{a_i} / (p_{a_i} + p_{b_j})\). Then the probability \(A\) wins the crew battle does not depend on strategy.
I haven’t proved this myself, but it feels very provable. Consider it an exercise to prove it yourself.
So…What Does This Mean?
Assuming this conjecture is true, I believe it means you should entirely ignore player strength when picking players, and should only focus on factors that aren’t tied to skill, like character matchups. In Super Smash Bros. Melee, Fox is favored against Puff, so if you’re playing against Hungrybox (the best Puff player of all time), this suggests you should send in Generic Netplay Fox even though they’ll most likely get wrecked. And conversely, it suggests a crew should avoid sending Hungrybox in if Generic Netplay Fox is in the ring, even though Hungrybox would probably win.
This is a pretty extreme conclusion, and I wouldn’t blindly follow it. Psychologically, it’s good for team morale if everyone can contribute, and sending people into matchups with a big mismatch in skill hurts that. But also, this suggests that crew battle strategy really isn’t that important in the first place! At the top level, it’s rare to see very lopsided character matchups. Pro players tend to pick strong characters that have good matchups against most of the field. Given that the lopsided matchups are the only ways to get edges via strategy, the math suggests that team captains actually don’t have much leverage over the outcome of the crew battle.
If your crew loses, you don’t get to blame bad crew battle strategy. Your crew is just worse. Deal with it, take the L.
July 2024 edit: Jon Schneider reached out to let me know the conjecture above is true and is a folklore result in some math circles. To prove it, you can model fights as independent exponential random variables, where each player starts with a lifespan sampled from their distribution, and expend life until one player runs out. If two players sample lifespans from exponentials with mean \(\mu_1, \mu_2\), then the probability player 1 wins is \(\mu_1 / (\mu_1+\mu_2)\). The result then follows from the memoryless property of exponentials - the expected lifespan of a player is always the same no matter how long they’ve been fighting. From here you can show that the win probability is the probability team A’s total lifespan exceeds team B’s total lifespan, and memoryless properties guarantee that total doesn’t depend on ordering.
-
MIT Mystery Hunt 2024
CommentsThis has spoilers for MIT Mystery Hunt 2024. Spoilers are not labeled.
I hunted with teammate again this year, because there is nothing quite like writing a Mystery Hunt to forge friends through fire.
Pre-Hunt
This year, I got to Boston much earlier than usual. This was in-part because the company I work for does limited vacation, which I’m bad at using. I needed to spend some to avoid hitting the vacation cap, and what better time than Mystery Hunt?
This made my Hunt much more relaxed than usual, since I got a few days to adjust to East Coast time, and was able to schedule visits to Level99 and Boxaroo before Hunt. We only went to Level99 because of Dan Katz’s post on the subject. Let it be known that we had fun, puzzle blog recommendations are good, and I would recommend it too. Now that I know what the challenge rooms are, the Puzzlvaria post reads so differently. (My group also took a hint on Pirates Brig, with the same “yes, really do what you think you should do” reaction. However we figured out a way to three-star the room without much athleticism.)
For Boxaroo, we did a friendly competition with another group from teammate. We’d each do two escape rooms, fastest combined time wins. The Boxaroo organizers knew we were doing this, so they:
- Invited mutual friends spoiled on the rooms to spectate and heckle our attempts.
- Told us we were “3 minutes slower than the other group” instead of our actual time.
When we compared notes afterwards, we lost 😔. It was very close though, with our total time only 30 seconds slower. I guess that’s like getting 2nd at Mystery Hunt by 10 minutes.
We also got shown a backstage tour of the room, due to finishing early. Some non-spoilery notes are that the room had dynamic extra puzzles that trigger if the group is solving it quickly, and the room has a “wedding proposal mode”.
Finally, we did Puzzled Pint, except, being silly people, we decided to make it more interesting by doing it “all brain”. No writing implements allowed, and each puzzle must be solved before looking at the next one. With 8 people, this seemed doable, but then the first puzzle was a nonogram, prompting a “OH NO IT’S SO OVER”. We didn’t solve the nonogram, but we did solve the puzzle, and eventually the entire set. Here’s the puzzle from “Animal Casino” if you want to attempt the same challenge.

Big Picture Thoughts
Hunt went long again this year, although this time it was more because of puzzle count than puzzle difficulty. If you were forced to pick how a Mystery Hunt runs long, I think most people would pick the “too many puzzles” side of Mystery Hunt 2024 over the “too difficult puzzles” side of Mystery Hunt 2023.
Still, my preferred Hunt ending time is Sunday morning. On Saturday, TTBNL told our team captain that Hunt was projected to end Sunday evening, and while this was great for planning sleep, it did make me a bit worried we wouldn’t finish. After no “coin has been found” email came by Sunday 10 PM, I was extra concerned. I ended up pulling an all-nighter to try to push towards a finish, which we missed by two metas, Sedona and Nashville.
Running a Hunt with 237 puzzles is just…an insane number of puzzles. It is not necessarily a problem. One minor complaint I have about Hunt discourse is when people say “puzzle count” when they really mean “length of hunt” or “difficulty of hunt”. It’s perfectly possible to write a Hunt with 237 puzzles that ends on Sunday if the difficulty is tuned correctly. A quick estimate: in 2022, Death & Mayhem was the first team to finish the Ministry, at Friday 18:47 EST, or 5.5 hours from puzzle release. The Investigation and the Ministry is approximately 40 puzzles. A very naive linear extrapolation of (237 puzzles / 40 puzzles * 5.5 hours) gives a 33 hour finish time of Sunday 1 AM. You could target that difficulty, overshoot a bit, and still end with a reasonable end time.
The issue is more that you are really creating a harder problem for yourself than you need to. Puzzle creation time isn’t linear to difficulty, and you need a lot of hands on deck if you start with a high puzzle count. TTBNL was a big enough team that I could see it working out, and understand why the team thought it would work out. But in practice, the difficulty trended up higher than the structure allowed. The “fish” puzzles in Hole were a bit harder than I expected “fish” puzzles to be, and the killers in this Hunt were just as hard as killers in other Mystery Hunts I’ve done. I still had a ton of fun, the majority of puzzles I did were clean and had cool ideas, and the fraction of “meh” puzzles was no higher than previous years. There were just a lot of them.
I really like that TTBNL did in-person interactions for each Overworld meta, to the point that I think we should have done so in 2023 and found a way to handle the logistics hell it would create. And when TTBNL decided to give out free answers on each meta interaction, doing so with a “you need to use it now” caveat was a great way to avoid the “teams stockpile free answers” problem we ran into during 2023. Between the events giving 2 free answers instead of 1, and the gifted free answers, I believe we used around 15 free answers by the end of Hunt. It still does not feel great to free answer your way to metas, but it feels a little better when it’s gradual rather than nuking a round at the end.
Thursday
Instead of going straight to the team social, I stopped by the Mathcamp reunion, which I failed to go to last year due to writing Hunt. I was very amused to see one group playing Snatch and another group playing Set, because these are exactly the two games supported by teammate’s Discord bot. I got back to the team social in time to play a custom Only Connect game. The Missing Vowels round included a “famous horses” section, and I got flamed for losing a race to identify PINKIE PIE. I knew the answer. My reaction time is bad. Gimme some slack.
We very definitely did not want to win this year (it wasn’t even asked on the team survey), so we had a #losecomm this year to figure out the most reasonable way to do so while still having fun.
The solution they arrived at was that no one was allowed to start or even look at a metapuzzle until all feeders in the round had been forwardsolved. This could be overruled at the discretion of losecomm. For example, if the last feeder was super stuck or grindy, we’d skip it for the sake of fun. We would also avoid using free answers. Otherwise, hints and wild guesses were all fair game.
This policy is really more restrictive than it sounds, because the meta solvers on teammate are pretty overpowered and solving at 70% of the feeders is often like getting to skip 50% of the work. It also implicitly means no backsolving, because you’ll never be in a position to do so. That further reduces your puzzle width, assuming that the hunt structure awards unlocks to backsolves.
Kickoff and Tech
I enjoyed kickoff a lot. The flight safety health & safety video was excellent, and getting Mike Brown (author of “How I Killed Pluto and Why It Had It Coming”) was a nice touch. TTBNL has a number of Caltech people, so it makes sense they could do it, but it was still funny.
As we walk towards our classrooms, I try to login to the hunt site from my phone, and manage to do so once but see a 500 error on a refresh. That’s not a great sign. Once we get to our rooms, the 500 errors persist, and…now it is time for a tangent.
The Tech Rabbit Hole
Early in the handoff between 2023 and 2024, TTBNL decided they wanted to use the 2023 hunt code. We cleaned it up, released it as the next iteration of tph-site, and gave advice during the year on debugging Docker errors, setting up registration, providing examples of interactive puzzles, and so on. As Hunt got closer, these messages got more frequent and shifted to email handling, webserver parameters, and server sizing. Most of our recommendations at this time were “use money to pay your way out of problems, running a server for a weekend is not that expensive if you just want CPUs”, and so they used the same specs we did: a 48-core machine with a ton of RAM and similar webserver settings.
When tph-site is under load, it’s common for the server to stall for a bit, eventually respond, and recover from there. When the hunt site does not recover, everyone who’s done tech infra for teammate starts suspecting an issue with too many database connections. This has been a persistent problem with tph-site’s usage of websockets via Django Channels, where the codebase is super hungry on database connections when many websockets are open. We’ve never fully resolved this, but intuitively there’s no way a site with a few thousand concurrent users should need 600+ Postgres connections. It just…no, something smells wrong there on the math. This issue has burned us in the past, but we’ve always found a way around it with connection pooling and using bigger servers.
We’re pretty invested in getting Hunt fixed so that we can do puzzles. A few teammate people drop into the #tech channel of the handoff server to help debug with TTBNL. There isn’t too much we can do, aside from passing along sample queries we used for diagnostics, asking questions about server configuration, and recommending TTBNL remove all non-essential websockets.
In discussions with the tech team, we find that:
- TTBNL ran a load test before Hunt. The server worked, with an initial spike of delay that recovered later, similar to tests we saw before.
- The live server is behaving differently from that load test, becoming unresponsive.
- The typical locations that should contain error logs contain nothing (???!!!)
- CPU and RAM usage are high, but not near their limits.
- Although the site is not responding, TTBNL is able to directly connect to the Postgres database and finds the database connection rate is high, but also not at the maximum set in the config files.
This makes debugging the issue really hard, since there are no logs, there is no reproduction of the error outside prod, and the server isn’t hitting any obvious bottlenecks. And so the best routes we can recommend to TTBNL are to apply random changes to the database config while we all read webserving documentation to see if there’s something we missed.
TTBNL will probably go into more detail in their AMA, but my rough understanding is that they figure out the request queue is the reason the server crashes and stops responding. As a temporary measure, they deploy a change that caps the request queue size, causing the server to throw more 500s immediately instead of trying to queue them. (This is later explained to teams as “fixing the server by making it fail faster”.) It still seems likely there’s a resource leak, and the root cause isn’t traced, but the site is now stable enough that it will keep working as long as it’s restarted occasionally, which is good enough to make Hunt go forward.
(From xkcd)
We got a very brief shout-out at wrap-up for helping fix the server. I don’t think we did much besides moral support.
I will say that I’m not sure we would have done better in TTBNL’s position. Whatever happened is mysterious enough that we haven’t seen it before. I’ve been poking into tph-site post-hunt, and I still don’t understand why the load test pre-Hunt failed to capture the during-Hunt behavior. Maybe the 15% more Hunt participants this year pushed things over the edge? Maybe a new team’s hunt management software hammered the backend too hard? Maybe MIT Guest Wi-Fi does something weird? I kept seeing “Blocked Page” errors on MIT Guest Wi-Fi when I tried to use Google search on Firefox, unless I used Private Browsing, so they’re definitely doing something different than normal Wi-Fi.
Whatever the cause, I suspect that this is a problem that is better cut at the source. By now, both GPH 2022 and Mystery Hunt have had server issues tied to websockets via Django Channels. For GPH 2023, Galactic entirely rewrote their backend for GalactiCardCaptors to avoid Channels because they didn’t understand why it broke for them and lost trust in its scaling. And for the Projection Device, although avoiding Channels wasn’t the intention, the backend for it was written in Go instead.
I think the platonic ideal hunt server would remove Django Channels from the codebase and use an alternate solution for websockets. That is the ideal, but I’m not sure the migration work would be worth it. The Projection Device may not have used Channels, but the core hunt site of Silenda from that year did. So did Spoilr, the codebase for Mystery Hunt 2022, and tph-site from Mystery Hunt 2023. Real companies have made Django Channels work for them, and past hunts have used it without major issues. This might be a case of preferring the devil that’s already implemented over the one that’s not.
Hunt! (Friday)
With the site fixed, it’s time to get into the puzzles proper.
The Throne Room
Herc-U-Lease - Ah, the scavenger hunt! Technically not in this round but I’ll put it here since I didn’t do anything in this aside from getting nowhere on Annual International Fictionary Night.
We did a few tasks, but on doing a cost-benefit analysis, we decided the effort needed to get enough drachma was too high for the reward. By the time the nerf came in Saturday, we had a lot of open puzzles to work on, and the cost post-nerf was still too high for us.
Looking at past Mystery Hunts, the 2022 scav hunt maxed out at 100 points, with 10 points for the hardest tasks. The 2023 scav hunt maxed out at 90 points, with 30 points for the hardest tasks, although I’m guessing most teams did the 10-15 point tasks. That’s around 10 hard tasks for both hunts if you’re on a big team. The 2024 scav hunt maxed out at 60 drachma and gave 3 drachma for the hardest tasks, or 20 hard tasks, twice as many. Even post nerf to 45 drachma, it was still 1.5x longer. Given that the goal of scavenger hunts is to get teams to do goofy things for your and their entertainment, I’d recommend future teams trend easier and target 10 hard tasks as their maximum.
I’ll still include our video for “throw something through 12 rings, each held by a different person”, because it never saw the light of day.
Everyone knew that tangerine was going to hit someone.
The Underworld Court
This round was released via Google Docs to teams, using phone callbacks. I don’t really miss them but it was a fun throwback.
Badges Badges Badges - The first puzzle I worked on while waiting for puzzle release. Honestly I’m surprised this is the first time someone made the nametags a puzzle, but they have only been a thing for 3 years. I quickly recognized mine was NATO, but by the time I figured out what “echo” is, someone else has already solved the full badge. Then I got sidetracked into tech debugging.
Roguelikes with a K - Listen, I’m always down to try a roguelike. I quickly learn I’m bad at roguelikes relative to teammate, and busy myself with organizing the sheet instead. We submit (well, call-in) what we think is the final answer, but realize the next step before TTBNL calls us back. I still have objections to some of the interpretations, they felt a bit loose. We considered Wordle to have resource management, since you had a limited number of guesses, but figured out it needed to be “false” during our error correction tweaking. Overall, cool idea, just wish it was tighter.
Dating Stars - The solvers of this puzzle had figured out the Chinese zodiac, but not anything else in the virgin vs chad memes. They were convinced the Western zodiac would be relevant, and in an increasingly desperate attempt, they asked a Homestuck consultant (me) to check if anything lined up with the trolls. I read over the puzzle and said “definitely not, also what in this puzzle would clue Homestuck???” They broke-in after I left.

Judges of the Underworld (meta) - Two of us (including me) were convinced that the heights of the pillars on the round page would be important for ordering, and got confused why it was reading so poorly, right up until someone resorted the sheet. We definitely did not need all the feeders to solve this meta, but those are the rules.
Rivers of the Dead
Why the Romans Never Invented Logic Puzzles - This idea was both cursed and a lot of fun. Three of us were working on a grid, slowly making deductions and backtracking through mistakes, and then Lumia says “okay, I’ve solved the logic puzzle” and drops the completed grid into the spreadsheet. This has happened to me enough times that I’ve stopped questioning it.
Initially, the large fractions of Js in the cluephrase makes me think we need to filter it with the Latin alphabet (i.e. there are no Js in Latin so ignore all Js). This doesn’t work, but I eventually decide that it really ought to be a do-it-again. We notice the self-confirming step and solve it from there. I get annoyed enough at the puzzle to start writing code to bash the finale, but the puzzle is finished before I get my code going.
Two Outs, Two Strikes, and… - I didn’t work on this puzzle, but want to call it out as very funny.
temporary name - We solve the answer matching pretty quickly. I volunteer to enter it into the site. It fails to do anything, and I announce we’re missing something. Around 10 minutes later, someone else resubmits the same answers to the website and it works, unlocking part 2. I guess I filled out the form wrong? Oops.
Do You Like Wordle? - This was a very infamous puzzle to me, because it was our last feeder in all the Underworld rounds. We initially ignored the puzzle due to the warning notice in errata. That meant that when we got back to it, we had very little progress on it, and effectively the entire team was forced to play Wordle due to our losecomm policies of forwardsolving everything. We split into two rough teams. One team played a bunch of Wordle games and shared screenshots into Discord, while the second team studied the screenshots to try to determine when a game would solve to a blue square or green square.
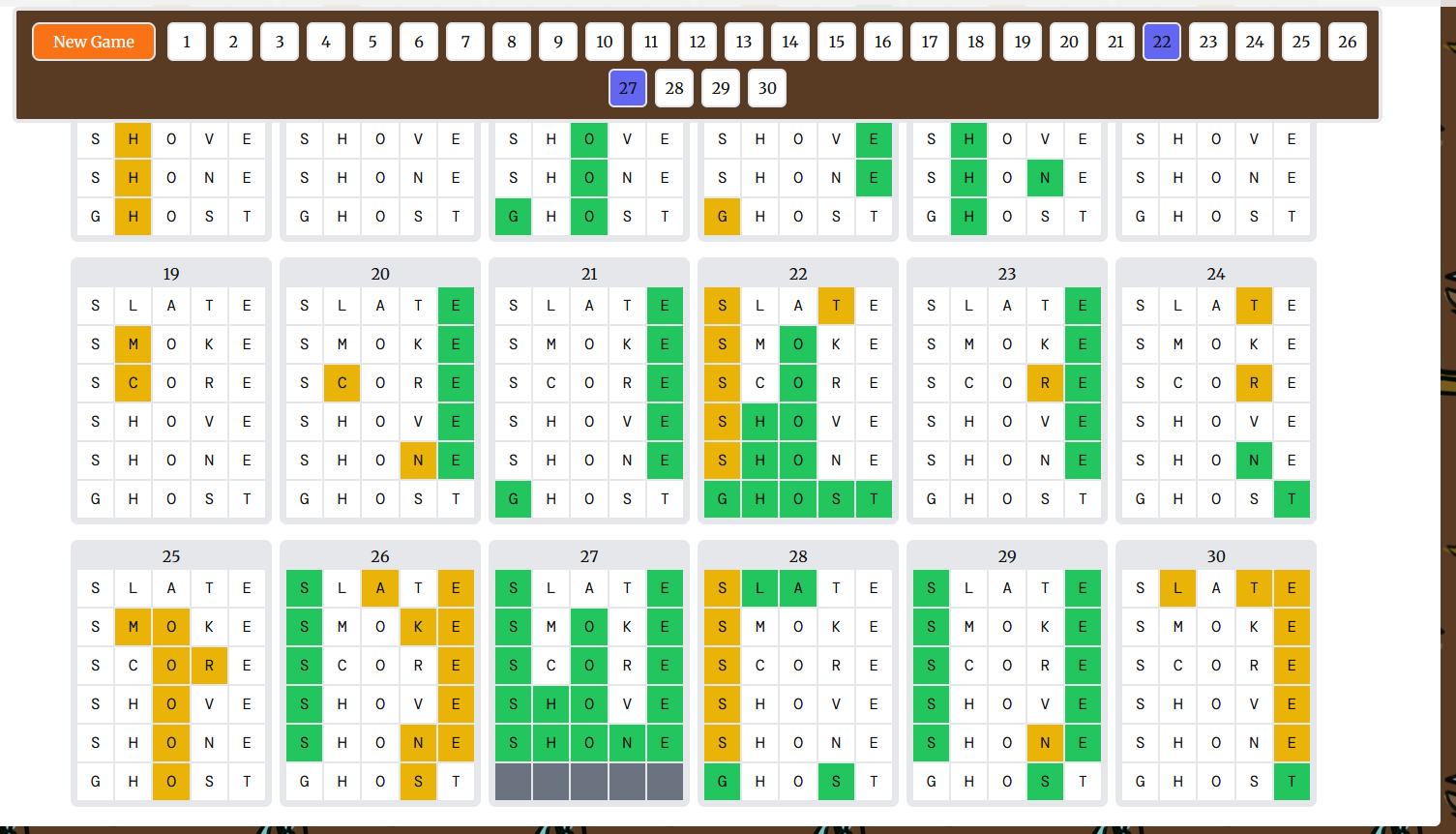
I asked some people to try games where all 26 letters were used. After finding this always led to blue games, they proposed the correct extraction idea - that a game was blue if the target letter appeared in any guess, and green if it appeared in no guesses.
I was skeptical of this, because the letters we had were starting
..i[phcdn][gk]hq, and I wanted it to form a 5x6 grid in the end instead of a 30 letter cluephrase. But teammates were adamant that this was the start of “BRING HQ …”. Seeing it continue[vx]smdid not give me much confidence, but I had no better ideas and the theory was looking consistent, so I started grinding out letters while saying “there’s a chance we’re doing everything wrong” every few minutes. Eventually we got enough to read out the cluephrase.I have mixed feelings on this puzzle. The place it had in our unlock progress was always going to make me get annoyed with it, no matter the quality of the puzzle, but it did feel especially grindy. As the author of Quandle, a puzzle that asks you to solve 50 Wordles, I realize how hypocritical it is of me to say this. I think for me it came down to this puzzle outstaying its welcome. Generally, I found I needed to play 3-4 games per board to restrict the letter enough in our regex to move on. That works out to 90-120 Wordles for the entire puzzle. I think Quandle is solvable at around 40-45 Wordles in comparison, and those extra 50 Wordles made the difference. Additionally, the game sometimes messed with my ability to generate useful runs. I’d start a game thinking “this time, I will use S and T but not R”, eventually realize the winning word was ROAST, and go “goddamnit”, losing the sense of control I associate with video games and interactive puzzles. In short, idea cool, but execution a bit too much of a drag.
Solving Wordle got us to the meta, and the runaround. I decided to go spectate the runaround with a bunch of other teammates, but when I realized this was going to look like someone reading a page aloud for many minutes, I bailed. People at our HQ told us TTBNL was going to unlock new rounds for us while the runaround ran, and I realized I came to Mystery Hunt to do puzzles, not watch people do puzzles.
The Hole in the Ceiling of Hades
I personally liked that puzzles unlocked in Hole throughout the Hunt, and know a bunch of people on teammate declared themselves “no Overworld, only fish” during the weekend. However, when the story page said “you are quite sure whatever’s up there isn’t necessary for getting out of Hades”, many of us interpreted it as “this round is not needed for Hunt completion at all”, and thought it was an optional round. This doesn’t make sense on reflection (why would a team write 50 optional puzzles), but, it’s what we thought.
The fact that we had over 40 solves in the round despite believing it was optional is a testament to the joy people got from doing easier puzzles in between Overworld puzzles.
It also meant I did almost none of this round. Oops! At least I’ll have a lot of things to go back to.
Streams of Numbers - I worked on this puzzle before we knew the round was supposed to be easy. That is my excuse for everything that went wrong.
After the initial ID of the numbers, we got very stuck on extraction. OEIS didn’t turn up anything, and after some shitposts like “it’s a fluid dynamics puzzle”, I decided to try extrapolating the sequences. How? Well, I guess I could extend the polynomial defined by the points…
I fit a polynomial to the first sequence, treating the values \(a_1, a_2, a_3, \cdots, a_n\) as points \((1, a_1), (2, a_2), (3, a_3), \cdots, (n, a_n)\), then evaluating the polynomial at \(n+1\). This gave back another integer. I tried it on another sequence and saw the same thing, so I excitedly shared this fact and we derived numbers for the rest. They were again all integers. In puzzle solving, you are often looking for the coincidence that isn’t a coincidence, the designed structure that suggests you’ve found something important. Getting integers for every sequence? Yeah, that had to be puzzle content.
Or was it? After failing to extract from values like -12335, the two of us working on the puzzle started to suspect that any polynomial defined by integer y-values would extrapolate to further integer y-values. “It’s finite differences right?” I considered this, said “Yeah you’re right”, but we both agreed that we were bad at math and should ask people better at math for a second opinion.
Upon asking the room, the responses were 50% “IDK sounds like you know the math better than we do” and 50% “no this has to be puzzle content”. I asked for a counterexample where integer points led to non-integer extrapolations, showing that typing random integers into Wolfram Alpha’s polynomial interpolation solver kept giving back new integers. This ended when someone new looked at the puzzle, and proclaimed “I don’t know the math, but I do know this puzzle is definitely not about polynomial interpolation”.
We abandoned the puzzle and it got extracted by fresh eyes a while later.
So, Is This Guaranteed by Math?
Yes, and it’s exactly because of the method of finite differences. If you haven’t seen it before, it’s pretty cool, albeit mostly useful in high-school math competitions that are long behind me. Do we have time for math? Of course we have time for math, what a silly question.
If you have values \(a,b,c,\cdots\) that you suspect are generated by a polynomial, then you can take consecutive differences \(b-a, c-b, \cdots\), take the consecutive differences of that, and repeat. Eventually you will end at a sequence of all constants.
1 4 9 16 25 3 5 7 9 2 2 2
If you extend the constants, and propagate the difference back up, you get the next value of the polynomial. I’ll mark the new values in parens.
1 4 9 16 25 (25+11=36) 3 5 7 9 (9+2=11) 2 2 2 (2)
Since this is all addition and subtraction, each step always ends at another integer, so the next value of \(f(x)\) must be an integer too.
As for why this is the case, the short version is that if you have an \(n\)-degree polynomial \(f\), then the polynomial \(g\) defined by \(g(x) = f(x+1) - f(x)\) is at most an \((n-1)\)-degree polynomial (all the \(x^n\) terms cancel out). The first line is writing out the values of said \(g\). The second line is the values of the \((n-2)\)-degree polynomial \(g_2(x) = g(x+1) - g(x)\). Repeating this keeps reducing the degree, ending at a 0-degree (constant) polynomial. Extending the constant and propagating the sum back up is the same as backtracking through the series of \(g\) polynomials back to \(f\).
In fact, you can derive the closed form of \(f(x)\) from any such difference table, but if you want to know how, you should really just read the Brilliant article about finite differences instead. It has rigorous proofs for all these steps.
What were we talking about? Oh right, puzzles! Unfortunately that was the only puzzle I did in this round. I was asked to solve some stuck clues in 🤞📝🧩 but was just as stuck on them as other teammates. And I didn’t look at the meta for this round.
Hunt! (Saturday)
I got to HQ at 8 AM the next day. Losecomm announced that the “forward solve” everything policy was gone. We were now allowed to backsolve, abandon hard puzzles, look at metas early, use free answers, and generally solve as fast as possible, with losecomm transitioning to a wincomm posture until further notice.
This felt early to me, but after Hunt ended, I got the full story: TTBNL did an HQ visit, and losecomm took the opportunity to ask TTBNL if they could tell us where we were in the leaderboard. We were told we were outside the top 10. Historically, teams outside the top 10 don’t finish Hunt. Our handicaps were too strong and we needed to speed up if we wanted to see everything.
I still did not try-hard as much as I could have, since I was approaching Hunt from a “forward solve cool things” standpoint. This is the first hunt in a while where I tried zero backsolves. Well, I’ve heard most of the Overworld metas were hard to backsolve anyways.
Minneapolis-Saint Paul, MN
Triangles - Oh boy, this puzzle. We started the puzzle on the D&D side, except I had no appetite to search up D&D rules, so instead I looked into the wordplay clues. We knew we wanted groups of 5 assembling a D20 from the beginning, but making it work was pretty tricky given the (intentional) ambiguity. Still, we were able to break in on some easier categories like single letters and the NATO alphabet. Once we got about half the categories, we started assembling the D20, using it to aid the wordplay. By the end, we had the D20 assembled despite only figuring out 10 of 12 groupings. My favorite moment was when we knew “Web browser feature” went to the “ARCHITECTURE + LITERATURE + PHYSICS” category, but just could not get it. Out of exasperation, I looked at my Firefox window and spoke everything I could see out loud. “Forward, back, refresh, home, tab, toolbar, extension, bookmark, history - WAIT, HISTORY”.
With the wordplay done, we figured out the ordering of D&D rules, mostly from me inspecting network traffic and getting suspicious why the request was including the count of rules seen so far. After much effort, we got all the D&D data to be consistent with the checksums, but became convinced that the numbering on the D20 would be driven by combining the wordplay half with the D&D half, rather than from just the wordplay half. Looking at the hints, I don’t think we ever would have gotten it, and we were pretty willing to move on after being stuck for many hours. (The assembled D20 was stomped flat and tossed into a trash can at the end of Hunt. No one wanted to bring it home.)
In a more normal Hunt I would be upset, but we were just trying to have fun and the wordplay part of the solve was rewarding enough.
Yellowstone, WY
The 10,000 Commit Git Repository -
*puzzle unlocks*
Brian + Alex Gotsis from teammate tech team: “Do you want to work on this puzzle?”
Me: “Sounds terrifying. I’m in the middle of this Triangles solve, but I’ll come by after we finish or get stuck.”
(Entire Git puzzle is started and solved in the time it takes us to get 1/4th of the way through Triangles.)
Hell, MI
I missed this entire round. The bits and pieces I saw looked cool, I’ll have to take another look later. The majority of this round was solved between Saturday 1 AM - Saturday 5 AM, and then the meta was handed off to people who’d actually gotten sleep.
Las Vegas, NV
The Strat - An amusing early morning solve. Came in, solved some clues, wrote a small code snippet to help assist in building the word ladders, and broke-in on the central joke of the puzzle. We then got stuck on extraction for a long, long time. We managed to solve it eventually by shitposting enough memes about the subject to notice a few key words, saving the people who were studying real-life evolutionary trees.
I feel like this puzzle would have worked if the enumerations were either removed, or changed to be total length ignoring spaces. They helped confirm things once we knew what we were doing, but were quite misleading beforehand. We spent a long time looking at the “breakpoints” implied by the enumerations.
Luxor - did some IDing, but quickly left when I realized I was not interested in researching the subject matter.
In my heart of hearts, I am a gambler. But I understand my flaws and don’t want to get into gambling in cases where it could lead to me losing real money. So instead I clicked the Mandalay Bay slot machine a few hundred times to contribute data.
We figured out the mechanic pretty quickly, although we did hit some contradictions in the emoji-to-letter mapping that we had to backtrack a bit to resolve. After assigning most of the letters, the distribution analysis people came back with the outlier emojis and we solved.
Our main objection at the time was the lack of a “roll 10x” or roll 100x” button as seen in puzzles like Thrifty/Thrifty. I suppose it wasn’t a huge deal though, we didn’t need as many rolls to break-in as that puzzle.
Planet Hollywood - I helped on the clue solving and ordering. For the extraction, right before Mystery Hunt we had run an internal puzzle event with an identical “connect the dots” mechanic as this one. That one clued spots in a specific shopping mall, and we initially thought we needed to find the locations of each restaurant within the Planet Hollywood resort. I bailed, but looking back I see the extraction was less painful than I thought.
Everglades, FL
Oh boy, we really overcomplicated the Hydra meta and almost full-solved the round before finishing it. This was when we started using our free answers to strategically direct solves towards specific metas.
How to Quadruple Your Money in Hollywood - Originally, I thought this puzzle was going to be a joke about Hollywood perpetually remaking movies, recycling plots to sell the same idea multiple times. I still don’t understand why the 2nd last entry is formatted like letters rather than email - is this supposed to be because the movie for this clue predated widespread email?
Isle of Misfit Puzzles - The minipuzzles I did (East Stony Mountaion, Kitchen Island, CrXXXXgrXm Island) were fun, although I did spend a bunch of time meticulously coloring cells in Sheets to match the Clue board and then saw it get unused in extraction. If it got used in numeral extraction, we skipped that for most minipuzzles. We were confident enough in the Hashi idea that most minis only had 2-3 possible numerals, and we brute-forced the numbers via the answer checker. I generally appreciated partial confirms but think this was one case that went too far. Final step was still cool though.
The Champion - I keep doing puzzles thinking they’ll be Magic: the Gathering puzzles, and then get baited into doing something else. We started by IDing the combat tricks. I am still embarrassed that our last ID was Gods Willing, I literally play that card in competitive.
From there, we got Yoked Ox first, and I did the right Scryfall query to break in on the right set of 16 cards to use. This then led to a surprisingly difficult step of pairing flavor text to puzzle content. In retrospect, identifying a few matching words across 16 paragraphs of text was always going to be a bit tricky.
What then proceeded was a total struggle of trying to pair The Iliad to The Theriad. I tried to do this, and mostly failed, getting distracted by Sumantle instead. The two of us who’d done all the MTG identification were both going to an event, so we called for help to fix our data while heading to the Student Center
“what are you doing?”
“fact checking the iliad”Nero Says - I have done Mystery Hunt for over 10 years and this is the first time I’ve done an event. Exciting! Normally I skip events for puzzles, but this year I wanted to try something new.
I got picked for the “detail-oriented” event, which ended up being a game of Simon Says in a time loop. Featuring many gotcha moments, it was very unlikely you’d clear it the first time, but upon losing the first time we got a worksheet that hinted at actions we should take to solve the event and break out of the time loop. Every now and then, you’d have things like “find someone with the same birth month as you, then tie at rock-paper-scissors”, and the intention was that you’d remember to pair with each other again the next loop.
One item on the worksheet was “what secret phrase will you unlock if everyone fails the first instruction”, and, in very predictable fashion, every time we tried to achieve a few people trolled by not messing up the first instruction. On around the 5th try, TTBNL decided to declare that we’d done it, although I definitely spotted one troll trying to keep going.
We wheel-of-fortuned the answer before the event finished, but decided to stick around to see more silly stuff.
The Champion, Redux - Coming back to the sheet, we saw the ordering had changed a lot. We didn’t fully ID everything, but had enough right to use the bracket to error correct. I set up the VLOOKUP to do extraction (cute cluephrase), and we finished the puzzle. We were very thankful this puzzle got solved. This is one of those puzzles where I would have hated it if we got stuck, but didn’t because we didn’t.
5050 Matchups - Every few puzzlehunts, I assume something is RPS-101 when it isn’t. This time it actually was RPS-101! The consequence is that I ended up solving, like, ten copies of 5050 Matchups, while taking breaks from…
Sumantle - This puzzle was cool at the beginning, but I have no idea what model got used for this, the scoring was incredibly weird. Our guess was that it was a pretty lightweight model, because the semantic scoring seemed worse than state-of-the-art. For many words in the first layer of the bracket, we had a ton of guesses in the 2-20 range without landing on the exact target word. The people on the team with ML experience (including me) tried importing multiple off-the-shelf word embedders, to search for new guesses via code, but we couldn’t find one consistent with the website. Word2vec didn’t match, GloVe didn’t match, and overall it just got very frustrating to be close but have no real recourse besides guessing more random words. We started joking about a “Sumantle tax”, where you were obligated to throw some guesses into Sumantle every hour.
I feel this puzzle would have been a lot better with a pity option if you guessed enough words near the target word. Having one would have reduced frustration and probably cut our solve time from 5 hours to like, 2 hours.
Mississippi River
The Hermit Crab - We needed a hint to understand what to do (trying to break-in from the last one was a mistake), but this was a cool way to use previous Mystery Hunt puzzles once we understood what we were doing. Was very funny when we figured out how to use Random Hall. I ended up solving Story 1, 2, 3, and 4, although I had to recruit logic puzzle help to check some theories on how story 4 worked. For story 10, I got the initial break-in, but needed help on extract. Personally not a fan of classifying SAMSUNG NOTE SEVENS as “fire”, but it is defendable. We also needed a hint on how to reuse the final shell - I think it was fair but would have taken us a while to figure out.
99% of Mystery Hunt Teams Cannot Solve This - LOL that this puzzle unlocked while our math olympiad coach was eating dinner. That is all.
Newport, RI
Najaf to… - teammate has a few geography fans, who write puzzles like First You Visit MIT and play GeoGuessr Duels. Many times in this Hunt, the “Geovengers” assembled and disassembled as puzzles that looked like geography turned into not-geo puzzles. This was the puzzle that finally made the Geovengers stick together for a puzzle.
How does it work? Oh I have no idea. I didn’t work on it.
Augmented Raility - video game puzzle video game puzzle video game puzzle.
teammate is the kind of team that takes this puzzle and identifies all the games and 80% of the maps in the games in 5 minutes without using search engines. Finding the exact positions took longer, but not too long, and we nutrimatic-ed the answer at 5/10 letters. I wonder if choosing Streets for GoldenEye 64 was a reference to Streets 1:12 (slightly NSFW due to language).
Von Schweetz’s Big Question - We did the first step, which reminded me a lot of Anthropology from Puzzles are Magic, and then started the second step, which also reminded me of Anthropology from Puzzles are Magic - not mechanically, more that I suspected the 1st step was an artificial excuse to make indices more interesting for the 2nd step. Unfortunately we didn’t finish this one since the meta for the round was solved before we got very far.
Nashville, TN
Sorry Not Sorry - Incredible puzzle idea. Not sure I like that it’s such a sparse “diagramless” but we were cackling for most of the solve.
Duet (meta) - We understood the round structure of Nashville, and that there was likely something after Duet, but that didn’t make doing so easy. There was pretty significant despair at the midway point of this puzzle, which we got to at like Monday 5 AM. The people working on this meta needed a hint to remember that this was a video puzzle with information not seen in the transcript.
Oahu, HI
I did not work on this round. My impression of this round was entirely colored by Fren Amis unlocking, and every cryptics person leaving their puzzle to join the Brazilian cashewfruit rabbit hole for 12 hours.
“help i am trapped in a foreign language cryptic and it is eating me like a sad cold blob of paneer”
New York City, NY
New York City was the round where we started think we’d unlocked the last round of the Hunt. It was not, we still had 3 rounds ahead of us. This hunt made me appreciate the design of the Pen Station round page in Mystery Hunt 2022, where you could see there was room for 10 regions in Bookspace. I’m starting to believe that it’s okay for Mystery Hunts to more transparent on their hunt structure than they normally are. The people who like optimizing Hunt unlocks can go solve their optimization problem, and the people who don’t will appreciate knowing where they are in Hunt. This is something that Mystery Hunt 2024 was worse at. (As a side note, I was also sad that there was no activity log, but we skipped implementing it in the 2023 codebase for time, so I guess I can only blame myself.)
A More 6 ∪ 28 ∪ 496 ∪ … - Featured my favorite hint response:
The puzzle is not about chemistry. It is about the US government.
Intelligence Collection - Codenames is always a good time. We found the assassins pretty early, and initially thought it would be a do-it-again using the clue words to make a new Codenames grid. This felt unlikely, since it threw away a lot of information, so that part of the sheet was labeled “copium meta”. I had to explain what “copium” meant to someone unfamiliar with the word. This was a definite lowlight in my journey of realizing where I fall on the degeneracy scale. At least we figured out the colors from the copium meta!
Queen Marchesa to g4 - Two Magic: the Gathering puzzles in one puzzlehunt? Surely this is illegal. Well, I won’t complain. I was hopelessly lost on most of the chess steps and mostly played MTG rules consulting and identification of the high-level objective. I was quite proud of figuring out the correct interpretation of the Time Walk puzzle, but this definitely paled to the bigbrain solutions for the Rage Nimbus and Arctic Nishoba boards. This puzzle was HARD but I felt it justified itself.
Olympic Park, WA

Yeah IDK I’m still pretty confident this is Mr. Peanut.
Transylvanian Math - This is the kind of puzzle that on its surface could be really annoying to solve, but ended up being really fun because the source material was so good. I’m curious, did anyone else break-in by finding a 2003 forum post written by a fan of Britney Spears?
ENNEAGRAM - I was recruited to help unstick this puzzle. As preparation, they made a clean version of the sheet, excluding exactly the part of the dataset that was needed to extract, hence I didn’t get anywhere. If you’re new, don’t worry, this happens all the time. Shoutouts to this flyer many of us saw when walking back to hotels.

Gaia (meta) - This was by far the most memorable meta solve of Hunt for me, so, strap in, this’ll take a while.
On opening the puzzle, we dragged a few stars around, noted some things, and identified the Vulpecula constellation. I figured out the Gaia catalogues connection, and started digging into the database to see what we could find. We tried to recruit astronomy help, and learned that:
- This year teammate had someone who looks for exoplanets in their spare time.
- They had already left and were traveling home.
So, we’re on our own.
We start by transcribing position and motion data of the stars in Vulpecula, to figure out the mapping between puzzle coordinates and star coordinates. After dealing with the horrors of understanding the sexagesimal system, and how to convert between hours and degrees, we muddle our way towards understanding the puzzle coordinates are just milliarcseconds from Earth’s perspective.
By now, we’ve realized that there are 10 unique letters that we want to map to digits, so that we can get new motion vectors for the stars. But, we don’t know how to do so. I propose that the “= X” for each answer is the sum of the letters in the answer, but this gets shot down because it feels too constrained (the value for ENNEAGRAM’s answer is very low for its length).
I take a break to get some water, and, thinking about the meta, decide that it’s still worth trying. I don’t have any better ideas on how to use the answers, and I know how to write a Z3 solver to bash it with code. I’m confident I can prove the idea is 100% correct or 100% wrong in at most 30 minutes.
By the time I come back, the other Gaia meta people have independently decided it’s worth trying the “sum of letters” idea. What follows is a teammate classic: can the programmer make their code work faster than the people working by hand? I win the race and find our 4/6 answers only gives two solutions.
Excitedly we find that one works and one does not, so we’re clearly on the right track. We split up the work: one person generates the IDs (“I can write a VLOOKUP”), a 2nd generates the target positions (“I understand milliarcseconds”), and a 3rd drags the stars into place (“I have a high-quality mouse”). This gets us to Columba, we extract letters from the Greek…and get stuck.
We have all the right letters, and we even realize that it’s possible the Gaia star contributes to the answer. However, we assume that if it does, its extraction works in the same way as the other stars. (Solving with this assumption gives that the 5th letter of the Gaia answer must equal the “alpha” letter, or 1st letter, of the Gaia answer. It’s weird logic, but can be uniquely defined.) Our lack of astronomy knowledge comes back to bite us, and no one on teammate thinks to look more closely at α Columbae until TTBNL gives us a hint at Monday 5:30 AM that the Gaia star contributes 5 letters to the meta answer.
The puzzle was all fair, and I had a lot of fun up to the end, but I do wish the ending was a little more direct on using Gaia. We were stuck at “BE NEON?” for about 6 hours.
Sedona, AZ
I didn’t work in this round, it passed me by while I was working on the Gaia meta. I did look at the meta, which we seem close on, but this is one of the 2 metas we didn’t solve by end of Hunt.
Still, one story that doesn’t fit anywhere else. Around Monday 12:20 AM, we realized it would be the last time we could get HQ interactions for the night, so we sent this:
Hi Benevolent Gods and HQ,
Us mortals of teammate would like to express our willingness to assist the gods with any tasks that they may need, perhaps in exchange for another “free answer”?
TTBNL obliged, giving us the Hera interaction early.
“So, how long have you been working on the Hera meta? It’s a tricky one.”
“We just unlocked it.”
“Oh. …The gods have decided to give you two free answers!”
“Can you do three?”
“Sure we can do three.”
And that’s how we finessed three free answers right before getting kicked off campus.

Part of the Hera interaction, where we played charades via shadow puppets.
Texas
There’s another round? Yep, there’s another round. This time we were pretty confident it was the last one, since we knew how many puzzles it would have and we were no longer unlocking things as we redeemed free answers elsewhere.
Since we unlocked it so late, most of the work here was done out of hotel rooms. Across teammate, we designed some hotel rooms as “sleeping rooms”, and others as “working rooms”, shuffling people around depending on desire and ability to stay awake. I didn’t come to Mystery Hunt planning to pull an all-nighter, but with us being in reaching distance of an ending, I decided to stay up.
Halloween TV Guide - I keep telling people that My Little Pony is a smaller part of my life now, but the first clue I solved was the MLP reference. I am never beating the brony allegations. I left this puzzle after the “octal-dec” break-in since I didn’t want to grind TV show identification, but I did successfully use Claude to identify some TV shows from short descriptions.
Appease the Minotaur (meta) - It was nice to see a metapuzzle unlock from the start of the round. I broke in on beef grades, helped transcribe the maze borders into Sheets, then dozed off in the way you do when your body wants to sleep but you’re trying not to. We knew what we were doing the whole time, so we decided to drop it and work on other metas, waiting for free answers to get full data before trying extract. I bet that if we had really tried, we could have finished at 5/8 feeders, but solved at 8/8 instead.
A Finale of Sorts
Coming back to campus in the morning, solving had mostly slowed down to chipping away at metas and waiting for increasingly delayed hints. Once the “coin has been found” email came out, we got a call from TTBNL giving the runaround cutoff time. They said that based on our solve progress, we likely wouldn’t make it. This really killed the motivation to start work on the last part of Nashville we just unlocked, so many of us decided to start cleaning up HQ instead.
Stats aren’t out yet, but I believe with our final push we got to around 7th. A bit disappointed we didn’t finish, but we had a good showing. Looking forward to next year!

(Tame Meat enjoying a brief period of flight.)
-
My AI Timelines Have Sped Up (Again)
CommentsIn August 2020, I wrote a post about my AI timelines. Using the following definition of AGI:
An AI system that matches or exceeds humans at almost all (95%+) economically valuable work.
(Edit: To clarify, this doesn’t have to mean AIs do 100% of the work of 95% of people. If AIs did 95% of the work of 100% of people, that would count too.)
My forecast at the time was:
- 10% chance by 2035
- 50% chance by 2045
- 90% chance by 2070
Now I would say it’s more like:
- 10% chance by 2028 (5ish years)
- 25% chance by 2035 (10ish years)
- 50% chance by 2045
- 90% chance by 2070
To explain why, I think it would be most instructive to directly compare my 2020 post to my current one.
The Role of Compute
The last time I seriously thought about AGI, I saw two broad theories about the world.
Hypothesis 1: Scaling is enough for AGI. Many problems we consider challenging will disappear at scale. Making models bigger won’t be easy, but the challenges behind scaling up models will be tackled and solved sooner rather than later, and the rest will follow.
Hypothesis 2: Scaling current methods is not the right paradigm. It is undeniably important, but we will reach the limits of what scale can do, find we are not at AGI, and need new ideas that are far from current state-of-the-art methods to make further progress. Doing so will take a while.
Quoting myself from 2020,
How much are AI capabilities driven by better hardware letting us scale existing models, and how much is driven by new ML ideas? This is a complicated question, especially because the two are not independent. New ideas enable better usage of hardware, and more hardware lets you try more ideas. My 2015 guess to the horrid simplification was that 50% of AGI progress would come from compute, and 50% would come from better algorithms. There were several things missing between 2015 models, and something that put the “general” in artificial general intelligence. I was not convinced more compute would fix that.
Since then, there have been many successes powered by scaling up models, and [in 2020] I now think the balance is more like 65% compute, 35% algorithms. I suspect that many human-like learning behaviors could just be emergent properties of larger models. I also suspect that many things humans view as “intelligent” or “intentional” are neither. We just want to think we’re intelligent and intentional. We’re not, and the bar ML models need to cross is not as high as we think.
(2020 post)
Most of the reason I started believing in faster timelines in 2020 was because I thought hypothesis 1 (the scaling hypothesis) had proved it had real weight behind it. Not enough to declare it had won, but enough that it deserved attention.
Now that it’s 2024, do I get to say I called it? The view of “things emerge at scale” is significantly more mainstream these days. I totally called it. This is the main reason that I feel compelled to keep my 50% / 90% numbers the same but stretch my 10% number forward. If scaling stops then it’ll take a while, and if it keeps going I don’t think it’ll take that long. The evidence so far suggests that the scaling hypothesis is more likely to be true.
If there is something I did not call, it would be the flexibility of next token prediction.
There are certainly problems with GPT-3. It has a fixed attention window. It doesn’t have a way to learn anything it hasn’t already learned from trying to predict the next character of text. Determining what it does know requires learning how to prompt GPT-3 to give the outputs you want, and not all simple prompts work. Finally, it has no notion of intent or agency. It’s a next-word predictor. That’s all it is, and I’d guess that trying to change its training loss to add intent or agency would be much, much more difficult than it sounds.
(2020 post)
It turned out that next token prediction was enough to pretend to follow intent, if you finetuned on enough “instruction: example” data, and pretending to follow intent is close enough to actually following intent. Supervised finetuning with the same loss was good enough and it was not much more difficult than that. The finding that instruction fine-tuning let a 1.5B model outperform an untuned 175B model was basically what made ChatGPT possible at current compute.
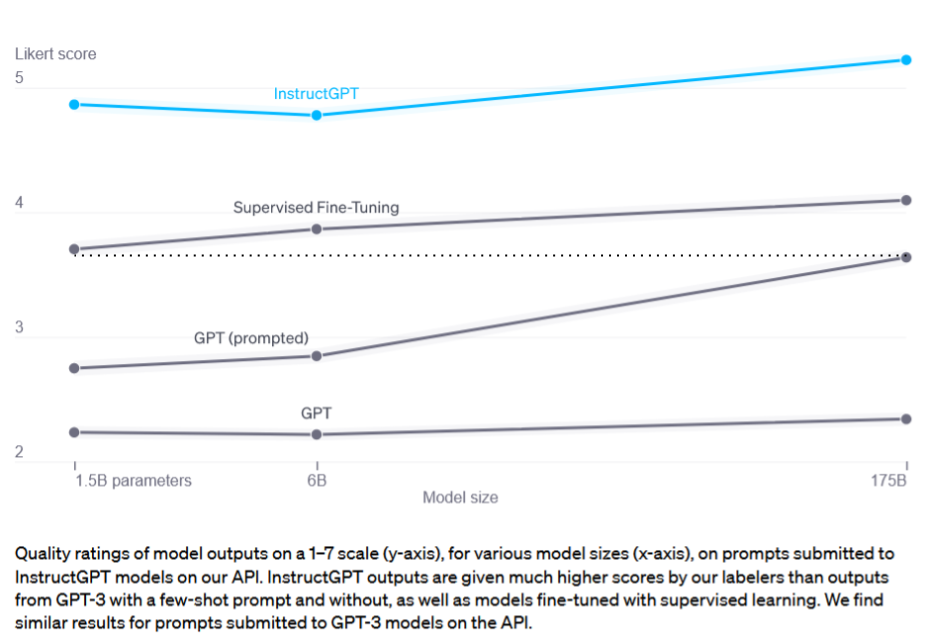
Diagram from InstructGPT analysis, with added line comparing the 1.5B supervised finetuned model to an untuned 175B model. Feel free to ignore the blue line that includes RLHF.
I was correct in claiming that something very important was happening at scale. I was wrong in how many ideas would be needed to exploit it.
Every day it gets harder to argue it’s impossible to brute force the step-functions between toy and product with just scale and the right dataset. I’ve been converted to the compute hype-train and think the fraction is like 80% compute 20% better ideas. Ideas are still important - things like chain-of-thought have been especially influential, and in that respect, leveraging LLMs better is still an ideas game. At least for now - see experiments on LLM-driven prompt optimization. Honestly it wouldn’t shock me if a lot of automatic prompt generation happens right now and just doesn’t get published, based on what people have figured out about DALL-E 3.
Unsupervised Learning
Unsupervised learning got better way faster than I expected. Deep reinforcement learning got better a little faster than I expected. Transfer learning has been slower than expected.
(2020 post)
Ah, transfer learning. I remember the good old days, where people got excited about a paper that did like, 5 tasks, and showed you could speed up learning at a 6th task. Now it is all about large internet-scale models that have gone through enough rounds of next token prediction to zero-shot a wide class of tasks. Or to quote work from my colleagues, “large language models are general pattern machines”. As far as I know, the dedicated transfer learning techniques like PCGrad are not only unused, they don’t get much further research either.
Suffice it to say that unsupervised and self-supervised methods have continued to shine as the dark matter powering every large language and multimodal model. They’re still the best methods for vacuuming up compute and data. Throw everything in the hole and the hole will provide.
If you’ve got proof that a large Transformer can handle audio, image, and text in isolation, why not try doing so on all three simultaneously? Presumably this multi-modal learning will be easier if all the modalities go through a similar neural net architecture, and [current] research implies Transformers are good-enough job to be that architecture.
(2020 post)
I don’t think there are sufficient advances at the algorithms level of unsupervised learning to affect my timelines. It feels compute driven to me.
What about other learning algorithms? There is still a role for supervised learning and reinforcement learning, but they certainly have less hype behind them. When deep reinforcement learning was at peak hype, I remember people accused it of being horribly inefficient. Which it was! The reply I’d always give was that deep RL from scratch was insane, but it was a useful way to benchmark RL methods. The long run would eventually look like doing RL on top of a model trained via other means.
Fast forward to now, and I got my wish, except I’m not happy about it. RLHF people tell me that they think pretty much any RL algorithm will give okay results as long as you have good preference data, and the most important questions are the ones surrounding the RL algorithm.

Calling back to the famous cake slide from Yann LeCun’s NeurIPS 2016 talk on predictive learning, people respect the cherry but it’s natural for people to care more about the cake. The slide is “slightly offensive” but I’d say it came slightly true.
I still think better generic RL algorithms are out there, and they would make RLHF better, but it’s harder to justify searching for them when you could spend the marginal compute on extra pretraining or supervised fine-tuning instead. It’s what you turn to after you’ve done both of the former. Robot learning in particular has drifted towards imitation learning because it’s easier to work with and uses compute more effectively. At least in my research bubble, the field is drifting from generic RL methods to ones that exploit the structure of preference data, like DPO and its siblings. Still, I feel obligated to plug Q-Transformer, a generic RL + Transformers paper I worked on in 2023.
Better Tooling
In the more empirical sides of ML, the obvious components of progress are your ideas and computational budget, but there are less obvious ones too, like your coding and debugging skills, and your ability to utilize your compute. It doesn’t matter how many processors you have per machine, if your code doesn’t use all the processors available.
[…]
The research stack has lots of parts, improvements continually happen across that entire stack, and most of these improvements have multiplicative benefits.
(2020 post)
Nothing in the tooling department has really surprised me. However, as more people have moved to Transformers-by-default, the tools have become more specialized and concentrated. Stuff like FlashAttention wouldn’t be as much of a thing if it weren’t relevant to like, literally every modern ML project.
If I had to pick something I missed, it would be the rise of research via API calls. API owners have a wider audience of hobbyists, developers, and researchers, giving more economic justification to improve user experience. I also liked Pete Warden’s take, that people are now more interested in “the codebase that’s already integrated LLaMa or Whisper” over generic ML frameworks.
Overall I’d say tools are progressing as expected. I may have been surprised when LLM assistants appeared, but I always expected something like them to arrive. However, I missed that the pool of people providing research ideas grows as AI becomes more popular and accessible, which should account for some speedup.
Scaling Laws
At the time I wrote the original post, the accepted scaling laws were from Kaplan et al, 2020, and still had room for a few orders of magnitude.
Two years after that post, Hoffman et al, 2022 announced Chinchilla scaling laws showing that models could be much smaller given a fixed FLOPs budget, as long as you had a larger dataset. An important detail is that Chinchilla scaling laws were estimated assuming that you train a model, then run inference once on your benchmark. However, in a world where most large models are run for inference many times (as part of products or APIs), it’s more compute optimal to train for longer than Chinchilla recommends, once you account for inference cost. Further analysis from Thaddée Yann TYL’s blog suggests model sizes could potentially be even lower than previously assumed.
Despite the dramatic reductions in model size, I don’t think the adjustments to scaling laws are that important to model capabilities. I’m guessing the Pareto frontier has bent slightly, but not in a dramatic way. Maybe I am wrong, I have not seen the hard numbers because it seems like literally every lab with the resources has decided that scaling laws are now need-to-know trade secrets. But for now, I am assuming that FLOPs and data are the bottleneck, and if you control for both we are only slightly more efficient and new scaling laws haven’t affected timelines too much.
I’d say the most important consequence is that inference times are much smaller than previously projected. In combination with smaller model sizes, there’s been a lot of progress in quantization to make those models even smaller in scenarios where you’re time or memory limited. That’s made products faster than they otherwise would be pre-Chinchilla. In the early 2010s, Google did a lot of research into how much delays impact search engine usage, and the conclusion was “it matters a ton”. When search engines are slow, people use them less, even if the quality is worth waiting for. ML products are no different.
Speaking of…
Rise of the Product Cycle
As part of the 2020 post, I did an exercise I called “trying hard to say no”. I decided to start from the base assumption that short-term AGI was possible, describe my best guess as to how we ended up in that world, then see how plausible I found that story after writing it. The reason to do this is because if you want to be correct that AGI is far away, you have to refute the strongest argument in favor of short-term AGI. So, you should at least be able to refute the strongest argument you come up with yourself.
At the time, I described a hypothetical future where not many ideas would be needed, aside from scale. I assumed someone developed an AI-powered app that’s useful enough for the average person.
Perhaps someone develops an app or tool, using a model of GPT-3’s size or larger, that’s a huge productivity multiplier. Imagine the first computers, Lotus Notes, or Microsoft Excel taking over the business world.
(2020 post)
This hypothetical app would bring enough revenue to fund its own improvement.
If that productivity boost is valuable enough to make the economics work out, and you can earn net profit once you account for inference and training costs, then you’re in business - literally. Big businesses pay for your tool. Paying customers drives more funding and investment, which pays for more hardware, which enables even larger training runs.
Since this idea would be based on scale, it would imply the concentration of research into a narrower set of ideas.
As models grow larger, and continue to demonstrate improved performance, research coalesces around a small pool of methods that have been shown to scale with compute. Again, that happened and is still happening with deep learning. When lots of fields use the same set of techniques, you get more knowledge sharing, and that drives better research. Maybe five years from now, we’ll have a new buzzword that takes deep learning’s place.
I thought this was a helpful exercise, and concluded by saying “the number of things that have to go right makes me think it’s unlikely this will occur, but it’s worth considering”.
And then everything I thought was unlikely came true.
We have a ChatGPT app, which went viral and inspired a large cast of competitors. It is not a huge productivity booster, but it’s enough of one that people are willing to pay for it. Supposedly Microsoft loses $20/user on Copilot, but David Holz has claimed Midjourney is already profitable. I’d split the difference and say most AI services could be profitable, but run at a loss in the name of growth.
This has driven tech giants and VCs to throw billions at hardware and ML talent hiring. Deep learning is old news - now everyone says “LLM” or “generative AI” or “prompt engineering”. Masked Autoencoders can handle audio, multimodal Gemini and GPT-4V handle vision, and a few video generation models are uncanny but making good progress.
To me it now seems completely obvious that transformers will be pushed much, much further than any other model architecture in the history of machine learning. There is too much hype, the scaling is inevitable, and even if the doomers’ point of view becomes more popular, there are enough optimists that I expect somebody will push forward, safety and alignment and fairness concerns be damned. To borrow a point from Gwern’s essay on timing, speculative technology is created by the experts with the most faith that it will succeed. It will always seem insane that those experts could be correct, and in fact those experts will usually be too early, but when they are right they will succeed before the world catches up to their ideas. And experts with the most faith tend to understand the possible negative externalities, but assume they’ll be fine. For better or for worse.
Trying to Say No, Again
Let’s run this exercise of “let’s assume near-term AGI is possible, how do we get there” again, to see what’s changed.
Once again, we’d assume progress comes primarily from larger compute budgets and scale. Maybe it’s not transformers, maybe one of the “transformer replacements” that claims to be more efficient will finally win. (I know some people are excited about Mamba and other state-space models.) Increasing parameter count in code is easy if you have the compute and data to exploit it, so let’s assume the bottlenecks are on compute and data. We can take “ML powers products powers funding powers ML” as a given. That’s just what’s happening. The question is whether something will make scaling fail.
I don’t really know enough about hardware to discuss it in any detail, so let’s just assume it’ll continue to grow. Computer chips have gotten more expensive, given that everyone is keeping their eyes on them, including nation states. Still, computers are useful, ML models are useful, and even if models fail to scale, people will want to fit GPT-4 sized models on their phone. It seems reasonable to assume the competing factions will figure something out. The silicon must flow, after all.
Data seems like the harder question. (Or at least the one I feel qualified talking about.) We have already crossed the event horizon of trying to train on everything on the Internet. It’s increasingly difficult for labs to differentiate themselves on publicly available data. Differentiation is instead coming from non-public high-quality data to augment public low-quality data. The rumor is that GPT-4 is good at coding in part because OpenAI spent a lot of time, effort, and money on acquiring good coding data. Adobe put out an ad asking for “500 to 1000 photos of bananas in real life situations” for their AI projects. Anthropic has a dedicated “tokens” team to acquire and understand data, based on job listings. Everyone wants good data, and they’re willing to pay for it, because people trust the models can use that data effectively as long as they can get it.
All the scaling laws have followed power laws so far, including dataset size. Getting more data by hand doesn’t seem good enough to cross to the next thresholds. We need better means to get good data.
A long time ago, when OpenAI still did RL in games / simulation, they were very into self-play. You run agents against copies of themselves, score their interactions, and update the models towards interactions with higher reward. Given enough time, they learn complex strategies through competition. At the time, I remember Ilya said they cared because self-play was a method to turn compute into data. You run your model, get data from your model’s interactions with the environment, funnel it back in, and get an exponential improvement in your Elo curves. What was quickly clear was that this was true, but only in the narrow regime where self-play was possible. In practice that usually meant game-like environments with at most a few hundred different entities, plus a ground truth reward function that was not too easy or hard, and an easy ability to reset and run faster than real time. Without all those qualities, self-play sputtered and died with nothing to show for it besides warmer GPUs.
I think it’s possible we’re at the start of a world where self-play or self-play-like ideas work to improve LLM capabilities. Drawing an analogy, the environment is the dialogue, actions are text generated from an LLM, and the reward is from whatever reward model you have. Instead of using ground truth data, our models may be at a point where they can generate data that’s good enough to train on.
There are papers exploring this already, usually under the umbrella term “synthetic data”. One of the early results around GPT-4 by Pan, Chan, Zou et al was that GPT-4’s label accuracy was competitive with human crowdworkers. Diffusion based image augmentation has been shown to improve robot learning, and Anthropic has based a lot of its branding on constitutional AI and “RL from AI feedback”. NeurIPS had a workshop on synthetic data as well. Other papers more directly use self-play terminology - see Improving Language Model Negotiation from Fu et al and Self-Play Fine-Tuning from Chen et al.
Language models in 2024 remind me of image classification in 2016, where people turned to GANs to augment their datasets. One of my first papers, GraspGAN, was on the subject, and we showed it worked in the low-data regime of robotics. “Every image on the Internet” is now arguably a low-data regime, which is a bit crazy to think about.
If the models don’t eat their own tail, the end result is a world where data becomes increasingly untethered from human effort, and progress just fully turns into how many FLOPs you can shovel into the system. Even if the accuracy of synthetic labels is worse, it’s often cheaper. I expect these ideas to work, although I’m uncertain on the time scale, and the result will be a world where direct human feedback is only used to bootstrap reward models for new use cases or sanity check data generated for existing ones. Everything else will be model-generated and model-supervised, feeding back into itself, with increasingly indirect human supervision.
Language models are a blurry JPEG of the Internet, but that is because current LLM text is bad for training. Blurrifying the Internet was the best we could do. What happens if that changes, and LLMs become blurry JPEGs of something clearer than the Internet?
Search and Q*
I don’t have too much to say about search, but I should mention it briefly.
During the Sam Altman drama, Reuters reported a method called Q*, creating a lot of speculation. In the circles I was in, the assumption was that it was some Q-learning driven search process. Eventually Yann LeCun put out a post saying people really needed to cool down, since literally every lab has looked into combining search with LLMs, and it would not be that surprising if someone made it work.
He was 100% correct. It is a very obvious idea to try. DeepMind put out a preprint that CNNs are good evaluators of Go moves in December 2014, added search via MCTS, and turned it into AlphaGo within a year. It was the ML success story of the decade. People do not forget the lessons from machine learning’s crowning achievements.
Search methods are usually very computationally inefficient, and I don’t know if our base models are good enough to use as search subroutines. Taking MuZero as a data point,
For each board game, we used 16 TPUs for training and 1000 TPUs for selfplay.
This is about a 100x increase in compute hardware. Still, one benefit of search is that it really ought to work. It is one of the most reliable ideas in machine learning. The reason we use search less now is because we’ve come up with better ideas for how to use compute. Search will always be there to eat marginal FLOPs if we run out of better ideas. Think harder, then teach yourself to come up with your final result the first time.
How Believable is All This?
Overall I think it’s plausible that we’ll continue to scale, that some of the perceived bottlenecks won’t matter, and we’ll discover ways to use current models to widen the ones that do. I’m finding it increasingly hard to refute that view of the world.
This theory of the world does rely heavily on model-generated data panning out. It’s possible that theory doesn’t play out. Or, that it leads to some gains, but runs into diminishing marginal returns. Still, let me know when you see the scaling laws hit a wall, instead of talking about why they ought to stop. So far, I don’t think they have.
On Hype
In 2016, a few prominent ML researchers decided to pull a prank. They set up a site for “Rocket AI”, based on some mysterious method called “Temporally Recurrent Optimal Learning” (TROL), then all coordinated stories about a wild launch party at NeurIPS 2016 that got shut down by the police. It was all fake, as detailed in this postmortem. There’s a fun quote near the end:
AI is at peak hype, and everyone in the community knows it.
Here’s the Google search trends for “AI” since 2016, scaled out of 100. Let’s see how peak 2016 hype compares to now.
Oh, what naive children we were! I do think it’s funny that AI is one of only a few research topics where people try to play down hype for the sake of the conversational commons. Imagine feeling like you need to discourage people from being interested in your research. There’s a real privilege there.
I have really really tried to avoid getting caught up in hype. I don’t like AI Twitter for reasons I’ve explained here, but I especially do not like AI twitter post-ChatGPT. So I want it clear that when I say I think AGI could be soon, I am not doing it for street cred, or to fit in. It is something that feels genuinely possible. The routes for improvement are clear, it’s just a question of if they will fail assuming billions of dollars of funding.
In AI, models can never do everything people claim they can, but what the models can do is ever-growing and never slides backward. Today is the worst AI will ever be. Even if all the VC companies bust and LLMs dry up, we’ll still have the models that are already trained and the ideas already derived. There is no going back. I’d recommend people think about what that means.
Everything has been changing since last generation was born
And they won’t try to take in change is a two edged swordThanks to all the people who gave feedback on earlier drafts, including: Diogo Almeida, Vibhor Kumar, Chris Lengerich, Matthew P. McAteer, Patrick Xia, and Hugh Zhang.
Appendix - The Bull and the Bears
When getting feedback on early drafts of this post, the main lesson I learned is that for AGI, there is one bull and many bears. The bull is to say that we can figure out how to scale models, and scaled up models will solve all the other hard problems. The bears are to declare X, Y, or Z as reasons progress will slow down or stop. And everyone has a different bear.

I ignored these bears in the main text because I felt it disrupted the flow of the argument, but I do want to acknowledge and reply to the bearish counterarguments I’ve come across. If I don’t mention your bear, I apologize.
The Data Provenance Bear
This article from Scientific American asks whether generative AI is making itself harder to train, by polluting the Internet with junk LLM text. For a more malicious angle, some papers have explored whether you can poison datasets by deliberate data injection - see Carlini et al, 2023.
As I’ve argued earlier, I think this is very important in the short term, but will be worked around and become less important later. The entire “AI self-play” thesis assumes that we will cross a tipping point where LLM text (filtered in some way) is good enough to train with.
One thing this does impact is our ability to evaluate models. I feel like every surprising LLM result gets accused of test set leakage these days, because it has happened before and is increasingly hard to verify it isn’t happening. That does drag on research, especially as running evals at all becomes expensive. But, coming from robot learning I am quite biased to think that will be annoying rather than existential. In robot learning “our benchmarks are both expensive and bad” has been true ever since 2016. and we’ve still found ways to go forward.
The Overhangs Bear
For people unfamiliar with the term as it’s used in AGI discussion, an overhang is when the ideas to create really good AI exists, but people don’t know it yet. There is an overhang between the best model creatable with present resources, and the best models we actually have. Once people believe in the ideas, you see a rapid increase in capabilities as researchers quickly assemble the right ideas together and fill in the overhang.
The implication is that progress relative to compute will be faster than it “should be” while the overhangs are filled. Extrapolating progress during overhang filling would overestimate future progress.
I think this view of the world is correct in describing how technology evolves and I’d agree that there are fewer overhangs in 2024 compared to 2020. Where it breaks down for me is that this view doesn’t give great guidance on when the next overhang will appear. “There are important combinations of ideas people have not put together yet” is just always true and part of why people do research. To me, “overhangs exists” sounds the same as “progress is a series of sigmoid curves”, where every so often you go through an inflection point. Making a projection during the inflection point is wrong, but so is doing so after the inflection point. The important question is how often the field reaches new inflection points.
I’m not sure how good scaled up transformers can get, but we’re not done with trying to scale them up. It’s possible the next big inflection point lies in better computers rather than better neural nets. I have a friend who runs an ML computing startup, and he used to ask me “what would you do if you magically had 1000x more FLOPs and 1000x more memory?” He stopped asking me this question after GPT-3. I think he knew my answer by then.
The “Scaling is Hard” Bear
A friend reminded me that for every LLaMa, there’s a Meta OPT that doesn’t live up to expectations. If you’re bored one day, the team behind OPT released a very detailed logbook of the issues they ran into. It features gradient overflows during Thanksgiving, mysterious activation norm spikes that traced to an accidental library upgrade, and more.
Scaling isn’t exactly a “numbers go up, use more hardware, oops we have state-of-the-art” game. It requires not just ML expertise, but a more specific expertise that (I assume) is learned mostly by experience rather than reading papers.
So, one theory you could have is that figuring out how to scale ML model training becomes a research problem of its own, that is not solved by scale, and eventually becomes so intractable that progress stalls.
I don’t find this theory particularly likely, given the history of scaling compute so far, and scaling of other big projects like the Apollo program (support bigger rockets) and Manhattan Project (get more enriched uranium). But I don’t have any specific argument against it.
The Physically Embodied Bear
One of the classic questions in ML is whether intelligence is bottlenecked on physical embodiment.
If this model is good at language, speech, and visual data, what sensor inputs do humans have that this doesn’t? It’s just the sensors tied to physical embodiment, like taste and touch. Can we claim intelligence is bottlenecked on those stimuli?
(2020 post)
Humans grow up and learn from a huge host of stimuli and sensors. Models learn differently. Large ML models do not have to learn the same ways humans do, but the argument goes like this:
-
Our AGI definition is
An AI system that matches or exceeds humans at almost all (95%+) economically valuable work.
- 95%+ will include taking physical, real-world actions.
- Right now, the majority of data feeding models is not embodied. If we assume scale is the answer, lack of embodied data will make it hard to scale.
Right now, I don’t think intelligence is bottlenecked on having data from physical stimuli, but performing well at real tasks likely is.
There are recent efforts on improving availability of embodied data in robot learning, like Open X-Embodiment, as well as prior datasets like Something-Something and Ego4D. These might not be big enough, but I don’t see a reason you can’t use models to generate your way out of the limited embodied data that exists right now. People are exploring this right now - see Universal Policies from Du and Yang et al, 2023. One of the big reasons I co-led AutoRT was because I thought it was important to explore what embodied foundation models looked like and push towards getting more embodied data - because I would much rather have a dumb physical assistant than a superintelligent software assistant. The latter would certainly be helpful, but I find it more concerning.