Posts
-
"My Soul is Pony-Scarred for Life Because of You"
Comments(Content warning: more swearing than usual, lots of ponies.)
I’ve really put off writing this post.
I’ve been watching My Little Pony for 10 years. 10 years. Good lord, that’s a long time. I thought I would leave the fandom in 2019, after the Friendship is Magic series finale. Then I thought I would stop watching in 2020, after finishing my fan projects. Then I thought I would stop in 2021…and here I am.
I’ve known for a long time that I wanted to write something about what My Little Pony and its fandom mean to me, but I’ve put it off for a long time because it brings up a complicated group of emotions and ideas that are hard to explain. This post is going to be long, so let’s get started.
How Did I Get Into My Little Pony?
I first got into My Little Pony via the show. Then I got really into it because of the fandom.
This post is not trying to get anybody else into the fandom. I decided long ago that it wasn’t worth doing so. But, I can’t explain what the Friendship is Magic fandom means to me if I don’t explain why the show appealed to so many people, and how that laid the foundation for everything that came after.
I started watching in 2011, during the hiatus between Season 1 and 2. I was a high school student attending Canada/USA Mathcamp that summer. Mathcamp is a summer math program that introduces talented high school students to interesting university level math, like topology or complexity theory. One thing special about Mathcamp is that it encourages student-organized events. As long as you get enough staff to agree to supervise, students can organize anything they want. The brony phenomenon was in full swing, a few students were fans, some staff were fans, and they organized a watch party. I went, watched a few episodes, saw the appeal, and resolved to watch the rest of the show later.
Not everyone who went got it. I distinctly remember one staff member who wanted to give the show a chance, but was completely baffled why MLP was popular after watching a few episodes. We had just finished “Call of the Cutie”, so we all called him a blank flank, which just sparked more confusion. Good times.
Season 2 started out really strong, and I stuck with the show all the way until its final season in 2019. Friendship is Magic has its ups and downs, but at its core it’s a wholesome, well-animated cartoon that shifts between light low continuity slice of life episodes, and high fantasy adventures where the fate of the world is at stake. The characters have fun personalities, they play off each other well, and then occasionally it turns into a magical girl anime with big rainbow laser beams. What’s not to like?
Of course, people got the wrong idea. No, it’s not about the 1980s Generation 1 cartoon, it’s almost exclusively about the Friendship is Magic cartoon from 2010. No, it’s not some fetish thing, most of the fandom just likes the show. (There is some porn, because people are always horny, but it’s not a focal point.) No, it wasn’t some elaborate gaslighting ironic joke. Maybe for some it was, but, again, most just genuinely liked the show.
There was other criticism too. “I can’t believe you’re watching a kid’s show.” When people said this, I don’t think they actually meant “shows made for kids can’t be good.” All of Pixar and Disney’s best work is a clear counterexample. I think they really meant that it’s easier to get away with a bad cartoon that’s all flash and no substance if you market it to kids. A lot of people mentally bucketed My Little Pony as one of those shows. That may have been true before (Generation 3.5 is legendarily bad), but every reboot is another chance to make things right.
In short, yeah, My Little Pony: Friendship is Magic is an advertising vehicle where the toys come first, but it’s a fun advertising vehicle. Sometimes making something good is the right way to make money. I wouldn’t say the writers succeeded all the time, some episodes are really bad, but the good ones are great. In context, the story told in “The Perfect Pear” is exceptionally cute and emotional.

A good show explains why a fandom exists, but it doesn’t explain why the fandom grew so explosively during 2010-2013. I’ve heard a brony describe it as a lightning in a bottle, and I think that’s true. It was dumb luck, amplified through the Internet.
In 2006, the sociology researchers Salganik, Dodds, and Watts had a question: given that every publisher wants to identify the next hit song, why is predicting song popularity so hard? They came up with the Music Lab, an artificial music platform. Participants were asked to listen and rank new songs. Optionally, some groups were allowed to see rankings from previous participants.
The paper is here, and the short version is that song popularity was just genuinely unpredictable. A popular song in one group would be near the bottom with the next. Interestingly, the more people observed other people’s rankings, the more volatile the popularity would be. That suggests some level of herd mentality - initial popularity is very random, but once you get popular, it is easier to retain popularity because people defer to the crowd and attention is zero-sum. I assume these dynamics are even stronger now compared to 2006, given a bigger Internet and stronger recommendation systems.
In most realities, My Little Pony: Friendship is Magic is a quietly successful cartoon that sells a bunch of toys, and otherwise leaves no mark on popular culture, outside a bit of nostalgia many years later. In our reality, it won the cosmic lottery, and after it did, the premise and size made it too novel to ignore. Not the premise of the show: the premise of the fandom. “Several 13 to 30 year old men swear up and down that the new My Little Pony show is worth watching” was a bizarre enough meme to spread far and overpower many existing aversions. The only reason I gave MLP a chance was because I was into Homestuck at the time, and MLP profile pics and references were appearing on the MSPA forums.
The show staff certainly didn’t expect it. In a panel with showrunner Lauren Faust and writer M. A. Larson, they talked about what it was like to work on the show during Season 1, and in particular, the day they watched a bunch of Russian teenagers singing along to Winter Wrap-Up. In that moment, the brony fandom they never predicted clarified into something real. The only thing left was deciding what to do about it.
“Fans are Great. Fandom is Weird”
There were haters, like there always are. Every culture creates its counterculture, and bronies are no different. Even so, bronies got it especially bad. It was astoundingly difficult for fans to explain the appeal to outsiders, and even if they did, it was incredibly easy to write off the whole thing as a bunch of weirdos.
This may be an unpopular opinion, but the MLP fandom totally deserved it. Kids didn’t deserve to be bullied for liking My Little Pony, but the fandom as a whole definitely deserved some gentle teasing. You know the old saying:
“Fans are great. Fandom is weird.”
(Terry Pratchett, supposedly, but I haven’t found a primary source.)
I’ve yet to see any fandom that wasn’t weird in one way or another. I mean this in the most endearing way possible, but I’ve been in Touhou fandom. I’ve been in Homestuck fandom. Let’s say I have a pretty calibrated sense of how weird fandoms can get. MLP fandom was and is weird. That’s why I love it.
We’ll see what I mean later, but for example, it was a meme to say “welcome to the herd” when someone declared they were a new member of the fandom. During the animating process, ponies were copy-pasted in the backgrounds of different episodes to save on animation costs. The fandom made up entire names and backstories for those characters, before any of them had gotten a speaking line. The character designs for Derpy, Whooves, Lyra, Bon-Bon, Octavia, Vinyl, and others were set instantly, but all the canon stories afterwards were heavily influenced by what fans wanted to see. Then there was the endless fan music, which ranged from remixing musical numbers in the show, to original music that sampled pony vocal chops, to instrumental music that was just inspired by the show.
Elements of this appear in many fandoms, but brony fandom was unusually prolific. The only good explanation for this level of content is passion, but that’s not a very satisfying answer. It just punts the question to why people were so passionate about a show that was good, but certainly not the Second Coming.
For their part, the show staff supported the fandom, and Hasbro said they didn’t plan to shut the fandom down, given it was free publicity. They made a poster for San Diego Comic Con 2011, and starting with Season 2, they made slight nods to the adult fandom here and there.

I don’t think Hasbro could have shut down the fandom even if they wanted to. It was bigger than them now.
I think the explosion of MLP fan content is most easily explained by the MLP universe’s untapped potential. If someone does good worldbuilding, you bet people are going to do more things in that world. In this respect, Friendship is Magic was almost hyperoptimized for fandom. The ensemble cast made it easy for fans to find at least one character they found compelling. The simple pony templates made it easy for people to make original characters. The show makes frequent allusions to world mythology, the history of Equestria, and other kingdoms ruled by different creatures, but rarely dwells on them for too long because they don’t serve the plot. This is the right move from a storytelling point of view, but unanswered questions beg fan answers.
There are also out-of-universe factors. When Hasbro wants a new toy line, the writers have to write it into the show, whether it makes sense or not. Sometimes, network executive intervention makes the show worse. According to rumor, the Season 3 finale felt so rushed because the writers begged (and failed) to get approval for a 2-part episode. Other times, it isn’t even the executives’ faults. The writers just drop the ball and put out a stinker. And, since Friendship is Magic has to stay family-friendly, there’s inherent constraints on what the show staff is allowed to depict.
My fave note on #MLPSeason4Finale “We cannot show Twilight punch Tirek in the face”
— Meghan McCarthy (@MMeghanMcCarthy) May 10, 2014
(Original storyboard of Twilight v Tirek fight.)
You couldn’t ask for a better sandbox to play in. And fans did play in it. They did all kinds of crazy shit. Sturgeon’s Law still applies, but the MLP fandom was prolific enough to produce lots of content in the 10% that wasn’t crap.
Want a voice-acted 9 hour Ace Attorney x MLP crossover video series? Sure, why not. Turnabout Storm is slow at times, but it does a great job at capturing the tone of Ace Attorney, has lots of shout-outs to both IPs, and the case’s resolution is excellent. Similarly, when I reread Fallout Equestria, I felt it still held up as a case study in how to write a protagonist who uses their abilities to their full potential, and villains whose actions are consistent with their end goals.
Those are both stupidly long, so if you want something shorter, how about Ponycraft 2 or Shingeki no Pony? Both are playing in the what-if space of “what if My Little Pony was a darker, more violent show”, crossing over with Starcraft and Attack on Titan respectively, and there’s some inherent humor in the juxtaposition between the two.

Mad Pony: Friendship Road, by Yulyeen
Want something without a crossover? Well, it’s not as popular, but I’ll always talk up the pony music video The Stars Will Aid in Her Escape, set to “Cosmic Love” by Florence and the Machine. It’s a cool discovered association, with a lot of nice visual editing. The pairing between “The stars, the moon, they have all been blown out, You left me in the dark” from Cosmic Love and the story of Luna’s turn to Nightmare Moon is uncanny, as well as the observation that both twilight the time and Twilight the character act as the bridge between Sun and Moon.
In some ways, fan content can be better than original content. Fanwork is like painting a tapestry, but instead of the standard colors like red and blue, you get more exotic colors like Reimu or Papyrus. This is inherently more limiting, and narrows the target audience to niche audiences, but in exchange, that fan work can convey very specific feelings or ideas to fans that have the required background. Those references can then further build on each other, creating very dense networks where every fan creation has ties to several other ones, producing endless variations on a common theme. Original work can’t do this, or at least not to the same degree. The reference pool is just too wide for this level of interaction.
The fan work may not objectively be higher quality, but it can subjectively be better, and when it comes to entertainment, you like what you like.
Falling Down the Rabbit Hole
Perhaps it’s silly that bronies ascribed so much meaning to an IP that has minimal real world value, and could carry on without them. But, again, they like what they like. We like what we like. The real world is inherently a pretty brutal place, and the universe really doesn’t care about anything. When faced with an unstoppable meaning-eating monster, anything that fights against that is good.
I remember during the aughts, when I was first trying to work my way into sports media, the popular line among the cool kids was that things like sports are a distraction that monopolizes peoples’ attention and energy that otherwise would go into enacting real political change. But things like sports are the fucking point! MMA, or learning how to play the lap steel, or thrift fashion, or Counter-Strike, or Scrubs fan fiction, or whatever in the world it is for you. That’s what you’re fighting for, if you’re fighting. Every hour you get to spend in that world is your victory against all this.
(Fighting in the Age of Loneliness: A Conversation with Felix and Jon)
I’ve come to realize that I put a lot of respect on people who take a nonsense idea, with minimal usefulness to the real world, and just run with it to completion because they want to. The lack of usefulness is almost the entire point. This doesn’t make me real money. It doesn’t make me smarter. It doesn’t help me on dates. It’s just a thing I do, in the time I have. Nonsense only exists because we’re serious about making it. There’s too many things that get dropped at the first sign of resistance, and I’d rather live in a world where people follow through on what they’re passionate about.
When it comes to fandom in particular, it’s interesting because a critical mass of passion leads to content that brings in more fans, leading to more content, and more fans, and so on. You get these engines of creation that twirl further and further away from show canon, and it’s fun to trace the web of inspiration. Fallout Equestria was an influential fanfic, which then spawned its own subgenre, a few game making projects, and not one but two different fanfiction print projects. The former focuses on just the Fallout Equestria universe, while the latter takes its name from FoE and prints a wider selection of MLP fanfic, if you can stomach the shipping cost from Russia.
Fighting is Magic was a 2D fighting game made by a group of fans with solid fighting game design skills. They made enough progress to show it off at side events for Evo, one of the biggest fighting game tournaments in the world. The high profile drew a cease and desist letter from Hasbro, and they complied, shutting down all development. In response, Lauren Faust offered to do some character design work, and Skullgirls licensed their engine to the team for free thanks to meeting a crowdfunding goal for Skullgirls DLC. Given a lifeline conditioned on redoing all art assets and implementation in the new engine, they renamed to Them’s Fightin’ Herds, ran a crowdfunding campaign, and released in early access on Steam in 2018, about 6 years after their first build. The game still receives updates today, and although story mode (still) isn’t done, its existence at all is a bit of a miracle.
I dunno how familiar people are with fan projects, but there are probably hundreds of ideas for fan projects starting every day. I would say 99% of them never go beyond the idea phase. It’s exceedingly unlikely that any given fan project will go anywhere at all, let alone stick together for as long as we have. Of the ones that do get past the idea phase, most of them are filled with passion, but are lacking skills. […] The tiny team we started with, from a random collection of people who happened to see a single post on a single forum at a certain time happened to get along and have the drive and skills that complemented each other and most of the gaps were filled right off the bat.
(Interview with TFH dev team, circa 2015)
The game has been divorced from its My Little Pony origins for years, but it’s thanks to the show that it exists at all, and I’m happy it’s moving towards its own identity. They released their first new character this year, and she’s a pirate goat that can cling to walls how is this not the greatest?
Sometimes, you don’t have a team. You have one crazy person. Consider Lullaby for a Princess, an animation by WarpOut. It’s 7 minutes long, and you could make a good argument that it’s the best thing the fandom’s ever made.
The backing song “Lullaby for a Princess” is by ponyphonic, a duo who imagined a song Celestia would sing to Luna after banishing her to the moon. WarpOut was inspired by the song, and decided to animate it with an exceptionally high quality bar. Although the music and backgrounds were done by other artists, the meat and potatoes of animating was done by one person, frame by frame, averaging 0.5 seconds of footage per day.
Footage from behind the scenes video
Much of my interaction with the fandom now is just through the pony music scene (which, yes, is a thing). You’ve got Ponies at Dawn as the “big” label, but then there are smaller labels like Equinity and new labels like VibePoniez curating more lofi music. Which all feeds into sites like the Equestrian Trot 100 (no longer maintained), or Horse Music Herald, as well as pony radio stations like PonyvilleFM.

These songs get a few thousand views. The launch parties get around 100 to 200 listeners. Nothing crazy, but good enough for people to keep tuning in. Sometimes, you have to write a song. If My Little Pony is the inspiration, so be it. Maybe somewhat fittingly, my favorite song from the pony music community is itself a remix of another fan song - The Wasteland Wailers’s acoustic cover of On Hold by YourEnigma.
When making this post, as an exercise I tried drawing out the web of MLP fan content I could recall off the top of my head. I didn’t get very far before realizing this was insane and I needed to stop.

(Click for full size)
There was a certain energy in the fandom, where people felt empowered to make whatever they wanted, along with an assuredness worn by fans who knew the community would keep growing and last forever. And like every group in history, they were wrong.
Time Marches On
Compared to what it was in the early years, the brony fandom’s a shell of what it was. The golden age is over and what’s left is much less definable. People in the fandom will get upset if you claim it’s dead, but it feels unlikely it’ll ever recover in size to what it once was.
You could try to blame it on Season 3. Controversial at the time, and still near the bottom of “best season” polls. You could blame it on the shifts in the show’s tone. As the show evolved, it “grew up”, making more nods to the adult audience, which not everybody liked. Some felt this cheapened the innocence of the show, or that giving fans what they wanted made the show worse on an objective level. Or, maybe it’s just seasonal rot. Slice of life shows tend to suffer after they exhaust the obvious storylines. I think the most likely explanation is that it’s the same thing that happened to Pokemon Go. For a short time, the world collectively had a fever dream and got in on the hype. Then the hype faded and the world moved on.
I’ve long hesitated to call myself a brony, even though I’ve watched the entire series, read about 2 million words of fanfic, created a custom MLP-themed Dominion expansion that I tried to get into Equestria Daily, and most recently led writing for My Little Pony: Puzzles are Magic, an MLP-themed puzzlehunt.
I will let the defunct ethnography blog Research is Magic explain why.
In my dissertation research, I study people who self-identify as Vietnamese and how they form connections with one another in local communities, on national and continental levels, and even transnationally. I’ve purposefully avoided categories like “Vietnamese Americans” or “the Vietnamese diaspora” because they tend to presuppose certain sorts of relationships that people may or may not have with each other […]. Therefore, I have often used terminology like ‘self-identify as Vietnamese” because the identification of oneself as Vietnamese means that a person is self-consciously engaged in identity work of a sort that produces potential links to other people who also self-identify as Vietnamese.
[…]
Kurt and I say often, “I’m not sure I’m a brony,” and we have both wondered about what keeps either of us from taking the plunge, so to speak. I would venture a guess that our anxiety stems from an incongruity between the moment we started to construct for ourselves an idea of a brony community and its relationship to our other affiliations. For me at least, I had been a casual viewer of the show for a long time. Even once I heard that bronies were a thing, I did not feel a need to reevaluate my watching of the show in those terms. I was part of the public/counterpublic in the sense we began with—of a kind of rapt attention to a cultural object—but since there was no utility for me in identifying with others, I felt no need to do the associated identity work.
Once Kurt and I decided we were going to do research on bronies, then the community became a “thing” for us…but it also meant that we at that same moment already had identities vis-a-vis that thing: brony researchers. Having produced the relationship with the fandom as one of a scholarly gaze, it’s been difficult to take on the brony label, even though we’re often doing exactly the same thing bronies are. The way the imagined community is imagined, the moment at which it is imagined, and a person’s relationship to that imagined thing all become important considerations.
Research is Magic: “What Sort of Group are Bronies?”
I’ve always preferred calling myself an “MLP fan” or “member of the fandom”, and I know I’m not alone. When I went through the feedback for Puzzles are Magic, I saw someone say they’ve seen every episode, but don’t consider themselves a brony. Or a couple said they and their partner called each other Flutter Butter and Dashie, but they didn’t consider themselves bronies. And then meanwhile, I go to a pony convention, where you would assume everyone self-identifies as a brony, and an attendee says they’re 2 seasons behind the show, and a panel gives a warning that their presentation includes spoilers for the currently running season, when you’d think catching up on the show would be a prerequisite of showing up.
The people who call themselves bronies are the ones who get use out of calling themselves bronies. They get a sense of fellowship in adopting the label. I never found that fellowship. It was fun to watch the show, and watch fan content, but I never felt the need to stand up for a generic brony, nor did I ever take the jump to actively participate in fandom discussion, or work on fan projects with people I hadn’t met before IRL.
It’s for these reasons that I found myself having less fun at brony conventions. The first one was great, but afterwards, not so much. Fandoms all have a pyramid of intensity. Of all the viewers, some become fans. Of those fans, some produce content or go to fan sites. Of those people, only some go to conventions. So at conventions, you don’t meet the average fan. You meet the super hardcore fan. Which, to me, is split between very cool people, and people I never want to interact with in my life. Dealing with the people I don’t want to interact with takes up all the energy I have to meet everyone else. (I feel I have a similar reaction to Bay Area rationalists.)
The fans I get along with realize the absurdity of the brony fandom, and just go along with it. They can seamlessly jump between hating on your favorite pony, and asking if you want to join them for lunch. Maybe they acknowledge that they’re sort of there for the ponies, but really there for the people. Or, they come up with genuinely impressive surrealist humor. I have yet to hear a more brain-stopping question than “If you could ship Twilight Sparkle with any pre-2000 US President, which would you pick?”
Maybe it’s just because of the demographics, but man is there a lot of shitposting. Like donating an empty box of Froot Loops for the charity auction. It is at least signed by the Toucan Sam voice actor, but it’s also a cereal box.

Or, well, this nonsense from 2018.

(A dabbing Ugandan Knuckles, spinning fidget spinners while eating a Tide pod, attached to a container of Tide pods not to be opened until after Friendship is Magic ends.)
You know if this kind of humor works for you. For me, it does! I appreciated getting to watch someone do a live rendition of “We Are Number One” in full Robbie Rotten cosplay. But, memes often don’t have any deeper meaning, and trying to live off just memes is like trying to live on only french fries. Talking to someone who only lives off memes is even worse.
The more time I spent in these convention spaces, the more I started to see the dreary plain white conference room walls instead of the magic. The decline in popularity was becoming starker. Going to a panel hosted by someone trying their best to work a room and failing would be fine if the seats were packed, but it was 1/3rd full at best and that just made it depressing.
There were some good conversations, but there were also content creators whose work I respected acting like assholes. Or panels that felt like excuses to hoard the meager clout still achievable in horse fame, rather than put on a show for fans. There were too many people who were there just to feel something. To get excited about being part of something greater, and having no avenue for that besides ponies. A sort of repressed nerddom exploding out at once, with no sense of perspective or self-awareness on what it meant in the grand scheme of things - absolutely nothing. Ponies are cool, but I don’t want them to be the only thing in my life. I’m perfectly okay with spending an irresponsible amount of time on MLP, as long as I know it’s irresponsible.
Unfortunately, there are people who don’t know it’s irresponsible, lack perspective on its irresponsibility, and can’t leave the MLP community because all their friendships and connections are based on MLP. They are also the people who always go to conventions. Horse conventions are their churches. The places where, for one brief weekend, the fandom is the real world, and as all-encompassing as they want it to be.
This is a subtle point, and I want to be very clear about it: I don’t have a problem with people like this existing. I think every hardcore fandom has some people who truly had no friends, community, or stable family situation before discovering the fandom. There are tons of stories of people who went through dark times, who likely would have taken their own life if they hadn’t found something to live for, in something as wonderfully goofy as My Little Pony.
It is clearly good that they found that something.
“People have come together and formed relationships and got married and had kids during the course of the show, because of the show … and we were wondering, how many kids owe their existence to this show?”
I wish them all the best. I just don’t want to talk to them. Maybe that makes me stupid, or selfish, or hypocritical to be so judgmental in a fandom whose motto is “love and tolerate”. I don’t know. That’s always been one of the struggles in MLP fandom. The show drew together people from around the world, including opposite sides of the political spectrum, and when the highly online far left and far right learn about each other, the peace can only stay for so long.
When your entire world is a single fandom, small conflicts become life-threatening attacks. Bad episodes become existential threats. Every time drama happens in the brony fandom (and there is always drama), I wish I could force everyone involved to watch and understand “This is Phil Fish”, a discussion on Internet fame (or more specifically, what it’s like to be a media object defined by people hating you).
Imagine you’re at some Manhattan cocktail party, and in conversation with a stranger you’ve only just met, you say, “Can you believe this bullshit Phil Fish said on Twitter?” Do you think the more plausible response is
A: God I know, what an asshole, or
B: I don’t really care.The correct answer is C: Who the hell is Phil Fish?
Phil is not famous the way we are used to thinking about celebrities. Despite being in a movie (a documentary about video games), the average random passerby has no idea who he is. […] The world at large does not know or care who makes video games. FEZ has shipped a million units, so in a random sampling of 7000 strangers, it would have been played by 1 of them. Phil is subculturally important, not culturally important.
He’s only famous to us.
In 2019, I had given myself a resolution: after I finished Puzzles are Magic, I’d move on from My Little Pony. It was getting smaller, I’d seen everything conventions had to offer, and I had some merch to remember it by. What else was there to do?
One Last Ride
BronyCon was the largest My Little Pony convention. Starting from small meetups in the New York City area, it later moved to New Jersey, then Baltimore, reaching 10,000 attendees by 2015.
I say “was”, because BronyCon ended in 2019. There were a few factors going into it. Attendance was declining about 20% year-over-year from its peak in 2015. Friendship is Magic’s final season was airing that October, just over 9 years after its first episode. Being the biggest con was part of BronyCon’s identity, and organizing staff decided they would rather end BronyCon with one big finale coinciding with the last season, rather than carrying on and watching it grow smaller each year. Given there were other MLP conventions with no plans of stopping, I thought it was a good call.
(To this day, my favorite video about conventions, from any fandom)
I waffled back and forth over whether to go, and decided that if I didn’t go, I would regret it for the rest of my life. So I went.
Evidently, others had the same idea. In 2018, they got 5,465 attendees. Knowing it was the last BronyCon, organizers expected a bump to around 7,000 or 8,000. They got 10,000. All sorts of people turned out. Lauren Faust, who had moved on from the show after Season 2. Old fandom members, who got super into it, then left the fandom in 2014, coming back to catch up with old friends for one weekend because it felt right. New fans who started just 1 or 2 years ago, well after the hype had faded. My Little Pony is now at the stage where kids in the target demographic of 6-7 years old at the start are almost adults now, and a bunch grew up with the show in the same way my generation grew up with Harry Potter. Every year, BronyCon got international attendees, but this year was the last one. If there was a time to splurge on international flights, now was it.
BronyCon. Was. Nuts.

I felt the fandom had told itself a collective story: the show’s ending. People’s lives are moving on. There will always be a core group of fans keeping the fire lit, like the Trekkies between the Original Series and Next Generation, but that’ll be it. The fandom believed it was not capable of pulling off big conventions, and the entire weekend was spent proving that wrong. People just needed a reason to come out of the woodwork.
We all knew this wouldn’t last. BronyCon was only so big because of the FOMO from existing fans, not new ones. It wasn’t going to kickstart a new wave of growth. Still, that didn’t make it any less entertaining. I saw a fan show off his Rainbow Dash decaled Ford Mustang. The Chipotle across the street seemed to have at least one person in a pony T-shirt at all hours of the day.
At the vendor hall, I talked to one of the few Asians I saw, buying the literal last Kirin shirt they had available in black. It was a little short, and I heavily suspected it’d be too small for me after going through the wash, but there wasn’t any choice. They had run out of merch on the first day.

They told me to come to their panel about the South East Asia brony scene, which sounded interesting, but I completely forgot to. Sorry!
I did talk to another Asian brony in the games room, while watching a Them’s Fightin’ Herds tournament match. While people in the background were yelling about a game they obviously didn’t understand, he talked to me about the Chinese brony scene. A lot of the Chinese fanbase is younger (like 10 years old), but there are still adult fans and they pulled in around 1200 attendees at their most recent convention. He was from Shenzhen, and was part of a group of 30 that made it past the visa issues to the US. He was spending his time buying merch to bring back for everyone who couldn’t come. I suspected he was from a rich family, since he was only 18, but he lived in Shenzhen, had gotten a sponsor tier badge ($250+, guarantees shorter lines and other perks), was carrying around a really high quality Starlight plushie (which he said cost $530 to commission), and he offered me $50 if I’d stand in line to get Lauren Faust’s autograph. Given that said line was 4 hours long because everyone wanted to tell Lauren Faust their life story, I declined.
The convention center was getting used by other events too. That year, it was co-located with the Rubik’s Cube National Championships. I saw some cubers walking through the same halls, and can only imagine what they were thinking when passing by the occasional fursuit.

I had privately made the Elements of Harmony ↔ Infinity Stones connection before BronyCon, and was gratified to see someone else had done the same.
In the evening, I went to one of the nighttime 18+ panels about the history of pony conventions, got a pony-themed cocktail, and listened to a bunch of people talk about how they got here, and all the horror stories of past cons. The one with the fire, the one where the organizers ran out of money and were completely gone while shit was hitting the fan, and so on. You know what they say, shared trauma brings everyone together. The cocktail was vodka, apple juice, triple sec, cranberry syrup, and small pieces of strawberry, and it was way too sweet. Shouldn’t have been surprised.
A number of brony conventions run concerts hosting fan musicians, who play their music to a crowd. Sometimes they play remixes of songs from the show, but more frequently they play original music that wouldn’t be out of place at an indie EDM concert. Because pony is what brought people together, but it’s not the reason people stay.
Usually, these events suck. Hard. Not by any fault of the music acts, it’s just that they’re filled with a bunch of awkward people, in a room that’s far too big, where no one’s brave enough to dance. The one at the final BronyCon? The Last Ride? It was lit. Okay, well, not by the standard of a real nightclub or music concert, but it was packed at 2 AM. Someone was waving an enormous Equestria flag. A person starts an impromptu conga line, yelling “JOIN US! IT’S OKAY! We’re all retarded.” Someone else signals everyone to clear a circle, and when we do, he starts showing off his sick breakdance moves. Between the insane circumstances, and the casual self-directed use of “retard” in the year 2019, I’m not sure I could give a better summary of the state of the fandom.
Despite everything, the rise and the fall in popularity, the content creators who moved on and see their pony work as an old shame, the outing of community figureheads as racists or sexual abusers, I could see the magic that originally drew me in. Enough that although I wouldn’t call myself a brony, if someone did, I wouldn’t feel the need to correct them. It’d be too hard to explain.
“Sometimes We’re Self-Conscious About Our Dumb Sport”
I don’t have any plans to go to another con. None of them are going to top BronyCon anyways.
I probably won’t watch Generation 5. I’m not sure how much longer I’ll stay in the fandom. We called it a ride because the MLP fandom loves horse puns, but it’s a fitting name. The point of rides is to stop. It’s okay for them to stop. Or, at least it’s okay for me to get off it if I want to. I think that’ll happen one day. For now, I still get something out of listening to new songs from the pony music community, and the few fan artists I follow.
I have spent an irrational amount of time and money on My Little Pony paraphernalia, and there is only one thing I regret. Once, I was wandering vendor tables, and saw someone was selling Arduineighs - a pony-themed Arduino board. They were themed after Twilight Sparkle’s Secret Shipfic Folder, a PG rated board game making fun of tropes in poorly written romantic fanfiction.

I bought one for $5, and regretted it almost immediately. I’ve never soldered in my life, what am I going to do with an Arduino board you have to assemble yourself? The coolness of the plain metallic look wore off pretty quickly.
Everything else? No regrets. I don’t regret the plushies, the prints, the Daybreaker shadow box, the badge of Flurry Heart labeled “DEMON BABY” that I bought from a teenager who offered 10% off if I subscribed to Pewdiepie on YouTube. (I didn’t.) I don’t regret the time spent carefully trawling the MLP wiki for the perfect Lyra thumbnail. I certainly don’t regret spending my senior year writing terrible Java applets to playtest MLP Dominion cards - eventually, I parlayed that into a SWE internship interview.
I come back to this question of what MLP all meant to me, and I’ve decided that’s just the wrong question to ask. Pony fandom was a sizable part of my life for 10 years. It wasn’t separate from reality, it was an exaggeration of reality, at its worst and at its best. The drama, the weirdos, the cool content creators, the jerk content creators, the toxic arguments, the jaw-dropping fan work, all of it. My thoughts on it don’t fit in a nice tidy box, because life doesn’t fit in a nice tidy box.
In the late 2000s, there was a Youtuber named ChaosAngel. Every few days, he uploaded a metal remix of a Touhou song, usually from the most recent Comiket. The songs ranged from prog rock to black metal, and his work was pretty influential on my music tastes. His channel was hit with copyright strikes from various doujin circles, and it was eventually taken down without appeal.
In response, he created a new channel, reuploading every song except the ones with copyright strikes. To announce the channel, he uploaded a “song 0” - a remix of Mima’s theme Reincarnation.
What were the reasons of the evil spirit Mima for her wish to destroy humankind, and why she goes from light to darkness was never known. Mima always denied her death, and she claims to be just a wandering spirit instead of a ghost, while she found the way to revive herself.
So let us continue what she couldn’t accomplish, by reviving ourselves.
Thanks for watching.
“No one shall be able to drive us from the wonderland that ZUN created for us.”
Sure, Hasbro’s the ones who created Wonderland, but it’s the fans that make it a place worth visiting. Together we’ve created bizarre cathedrals of horses and magic, stylized with cringeworthy stained glass windows, and it needs someone to bear witness. As long as people maintain it, I’ll check in from time to time, even if it’s only out of nostalgia. Even if it’s all fake compared to the real world. The cathedrals are real to us.
Maybe you have a brony fandom of your own. Something you’re a fan of, that you can’t explain. I think it’s more common than people think. I got this feeling when I watched a documentary about MMA.
There’s no magic out there when it comes to the contest over resources that governs our lives and the lives of our children. […] The magic that we wish we saw everywhere else was in the cage, because it was conjured by people who were just too fucked up to make it in the world outside. In a world where everything seemed to get slightly better then slightly worse at a more constant rate, at least there was one place where unthinkable things actually happened. At least if you put two weird people with incredible abilities in front of each other, their combined experiences and opposing martial abilities would create a beautiful, maddening story.
“Fighting in the Age of Loneliness”, 1:24:20
Dana White is an MMA fan, and there’s a very real insecurity in MMA fans. Whether you’re watching a shitty UK stream on your friend’s off-brand tablet, or you’re the president of the world’s biggest promotion, sometimes you may feel a little self-conscious about our dumb sport.
Everyone who loves this sport has had a moment where they watch an event with a friend, a family member, or a romantic partner. It was probably during the pay-per-view golden age of the late 2000s, where the person you hoped would become just as obsessed as you [in MMA] saw men in awful tattoos wearing shorts that said Condom Depot in huge letters on them, [pushing] one another against a fence for 15 minutes. […] Your target audience found it too weird, too boring, too terrifying, or all three. And the cultural image of MMA fighters is a bunch of enormous, angry men, with weird tattoos, who always seem to be yelling. And the image of fans is a sea of guys with big guts and chiseled arms, wearing Affliction shirts and getting wasted before insulting random passersby. But does it matter? We love this sport! […] We love it, and that’s all that should matter. And who gives a shit if we don’t have hundreds of millions of people watching with us every time. And why do we care if people think we’re weird or fucked up for watching it? We know what our sport is, and we know who we are! From the most stereotypical ones, to the grandmas and grad students who get just as excited as the Affliction shirt guys.
“Fighting in the Age of Loneliness”, 1:27:30
Maybe you’re trying to justify why it’s worth cheering for the Seattle Mariners, possibly the most tragic team in baseball.
The Mariners aren’t special on account of their lack of success, it’s just that success is entirely irrelevant. We’ve entered another realm here, one that’s far larger and doesn’t operate on the dead currency of winning and losing. Unless you let those limits go, you’re an astronaut who brought your wallet. The Seattle Mariners are not competitors. They’re protagonists. […]
With the benefit of hindsight, we know that on-field contention wasn’t in the cards for the Seattle Mariners, and has never been to this day. That was never happening. The only fight left was for happiness.
“The History of the Seattle Mariners”, 2:26:50 and 2:44:50
I’ve long given up on getting anyone else into this fandom, this thing where observing it is hard and pretending it doesn’t exist is easy. That’s fine. People don’t have to see it or understand it. They just have to accept it. If they can’t, they can go to hell.
Over the years, I’ve come around to the “relentless march of the normal” theory. Any culture that gets big - any culture at all - cannot grow and stay big without losing its unique charm, because that unique charm can’t survive in a culture that tries to appeal to everyone. So that culture has a choice: accept it’ll change, or find a way to grow slowly enough to protect itself. We all wish we could get both the charm and the popularity. I’ve yet to see anything succeed. All those early brony thinkpieces examining why people don’t watch the show were a waste of time. If they had gotten what they wanted, we wouldn’t have recognized what came out. Sometimes it’s worth fighting for legitimacy, but bronies lost that fight ages ago. Trying to argue “we’re better than the furries” is not going to save you from the wider world. Make fun of yourself by saying you’re trash, and move on.
The kids, when they like something on the Internet, they call themselves the trash of the thing.
BronyCon was lucky that their final run was the year before COVID-19 swept through and cancelled all pony conventions for 2020. It was really unclear how the brony ecosystem would fare. Con treasuries took a big hit, and artists who rely on con sales as supplementary income were in trouble. In response, some organizers set up PonyFest, a free online brony convention with remote panels and a vendor hall hosted in Discord. Cool idea, a lot of work required. I bought some cute MLP-themed boba stickers in support.
Once again, they held a music concert, but this one was virtual in Pony Town, a social MMORPG where people can make pony OCs to chat and hang out. Looking at that concert of fan music, streamed live into an actively developed fan game that hit 15k concurrent users this year, I realized this fandom actually might never die. Where are these people even coming from?
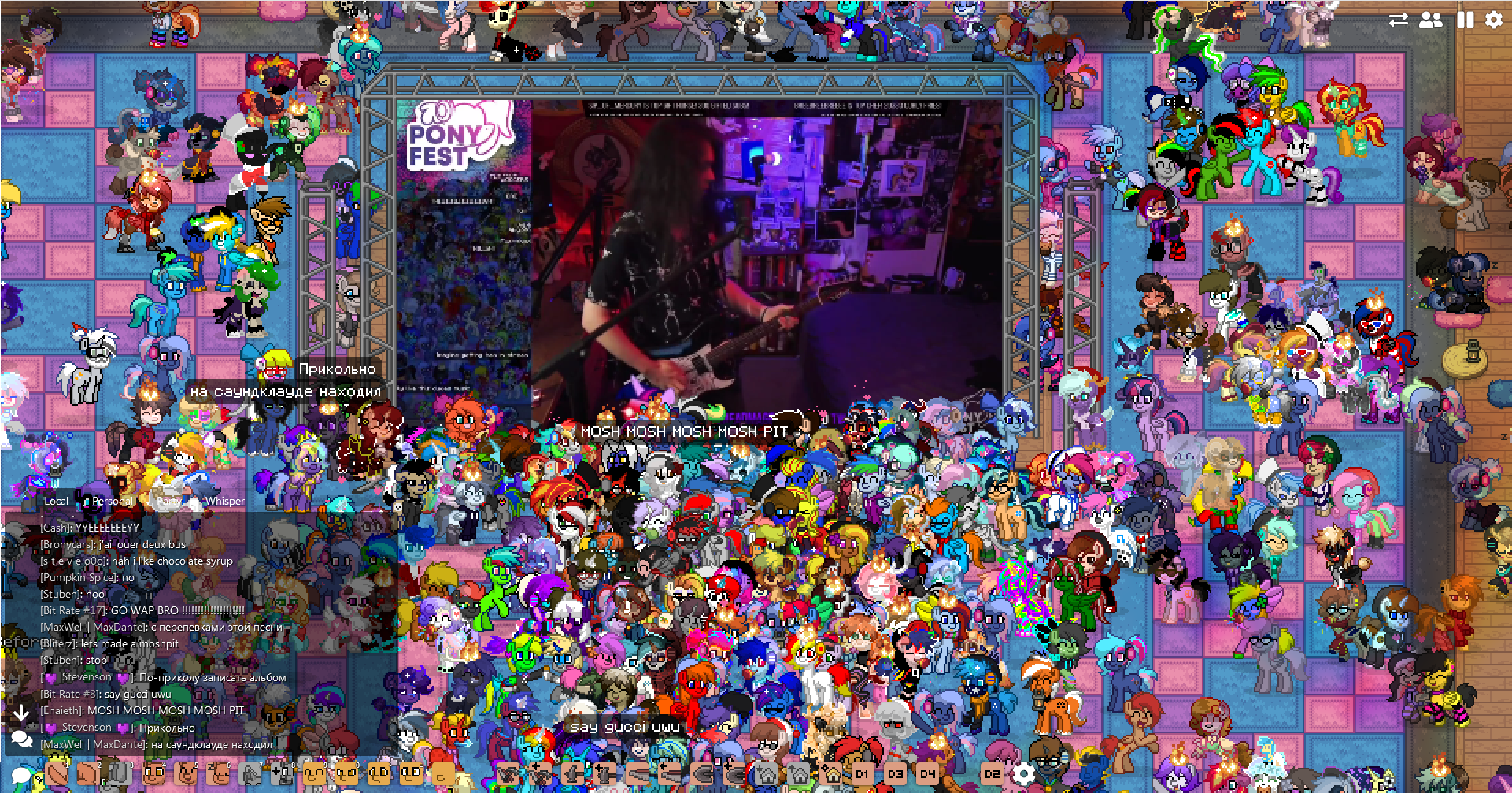
{Click for full size)
Sure, Friendship is Magic is over, but the fans left have transcended the show. They’re doing what makes them happy. The recursive engine of fan art of fan art is going to keep spinning. The Generation 5 movie kick-started things a little bit, and maybe the TV series will be good. Maybe it won’t. It doesn’t matter either way. Friendship will always be magic. Once you’re in, a part of you never leaves.
Letting go is harder than it seems
I still wonder if you remember meIt’s been so long, you’ve gone so far
Through space and time between us in my heart
I’ve lost my way, now I can’t see
I still wonder if you remember meThanks to Alex Mun and Diyang Tang for reviewing earlier drafts.
-
Review: How To Invent Everything
CommentsHow to Invent Everything is a book by Ryan North, of Dinosaur Comics fame. Its premise - time travel is real! You’ve just used your time machine, but now it’s broken and you’re stuck in the past. You want to:
- Not die.
- Recreate your modern life of luxury.
How to Invent Everything doesn’t literally cover everything, but you can see it as a book about the highlights of civilization. It covers basic survival tips, building up to important technologies like the compass, then ending with fundamental science concepts and a basic intro to computing and logic gates. Its main thesis is that with the right reference text (itself), you could reproduce 12000 years of human progress in, say, 5 years of work.
Odds you’re ever in the exact same scenario as the premise? Vanishingly small. Still, it’s a fun read if you’re interested in exploring how humanity improved its quality of life from first principles.
* * *
The main reason I like this book a lot is that it’s very, very reductionist. That necessarily falls from the premise, but it makes it easy to trace the links between technological innovation. Steam engines relied on precision engineering to make airtight pistons. That required a standard unit of measure and knowing how to make steel. Steel requires knowing how to smelt iron, and that requires kilns. To get the kiln to high enough temperature, you want it to be made out of bricks, and bricks are easy if you know how to make charcoal. There are many details to fill in for getting the raw materials, and the book deliberately focuses on the technology rather than the politics of convincing people to help create your vision, but having the road map to go from nothing to the core of the Industrial Revolution is a big deal.
(It’s also fun to consider how different things would be if certain natural resources weren’t so plentiful on Earth. So much technology traces its lineage to the chemical and physical reactions that turn wood and mud into useful materials, and it’s not like wood has to exist on a planet with life.)
Over and over again, the book points out the difference between when inventions were invented, and when they could have been invented. The gap is usually decades, or centuries. It’d be easy to conclude that humans are dumb, and in some sense that’s true. If you assume that evolution increases intelligence very slowly, and civilization appears as soon as an organism is smart enough to construct it, then the natural conclusion is that humanity is the dumbest species that’s just smart enough to create civilization.
So yes, we’re dumb. On the other hand, when you read the “solution” to different technologies, it can be hard to fault humanity. The prerequisites for the bicycle were around for a long time, but considering their design, even minor changes make the bicycle just a novelty instead of a more efficient means of transportation. (See this post by Jason Crawford for more analysis.)
It’s also easy to see how environmental factors can hamper innovation. Take crop rotation for instance. The core idea of crop rotation is that if you grow the same crop every year, and haven’t invented fertilizer yet, your crops will use up nitrogen in the soil. Next year’s crop is bad, the one after that is worse, and eventually the soil is no longer fertile. The easiest way to fix this is to let fields lie fallow, which means growing no crops to give time for the land to recover. Alternatively, you can plant legumes like clover, which replenish nitrogen thanks to their symbiotic relationship with nitrogen-fixing bacteria.
Now, imagine you are a generic human around 10000 BC. You’ve just discovered the basics of farming, and have reached an uneasy level of food security. Some bozo is saying you should leave a perfectly good field alone for long term sustainability. Are you going to listen to them? Keep in mind that you don’t know the chemistry, you have no way of learning the chemistry because the right tools don’t exist yet, crop experiments have a long delay to payoff, and you have limited experimentation budget because messing up crops means people go hungry. It’s easy to see why we don’t have evidence of two-field crop rotation until 6000 BC, and four-field crop rotation wasn’t invented until around the 17th century. Discover the correct causal links seems very hard, especially given the other confounding factors.
I don’t want to give humanity too much credit. Hot air balloons took a really long time to invent, given that baskets, controlled fire, and fabric all existed for centuries. Incubators for premature babies were not used until 1857. All that needed was a warm box, and their introduction reduced premature infant mortality by 28 percent. The Pelton wheel is a more efficient waterwheel from the 1870s, about 1400 years after the earliest known waterwheel. Its primary differences are using pressurized water and a better paddle shape. It really doesn’t feel like discovering those two should have taken 1400 years, but it did. It’s made worse when the book cites a source that Pelton was inspired by spraying a cow in the face.

I mean, cool story, but it’s a bit embarrassing no one thought about the physics earlier.
* * *
Does How to Invent Everything offer any greater truths about the universe? Well, maybe. Here are my takeaways.
Models don’t have to be correct to be useful. Many times, people had the wrong idea about why a technology worked, but that didn’t stop it from working. For thousands of years, no one knew where alcohol came from when brewing beer, but people brewed it anyways. Similarly, there is evidence the Egyptians knew that eating liver helped them see in the dark, but it would take many years to learn this was because livers are heavy in vitamin A.
Technology can be lost. Rongorongo is a set of glyphs found on Easter Island that might be an independent invention of writing, but it’s hard to tell because no one knows how to read it. In Rapa Nui culture, only the privileged few could be taught how to read and write, and after a smallpox epidemic went through the island, anyone literate was dead and the symbols were just that - symbols. As another example, the cure for scurvy was lost and rediscovered seven different times between 1400 and its final discovery in 1907. That’s crazy. You wouldn’t think “eat a fresh orange” would be so hard for a society to remember, and yet there it is. Arguably, this is an argument we should focus on better archiving of information.
Society advances when information spreads easily. One question How To Invent Everything toys with is what point in history would let you most influence the trajectory of humanity. It concludes that the answer is either introducing spoken language, or introducing writing. Spoken language allowed humanity to share complex concepts with each other, which let ideas live after death. Writing (and later, the printing press) allowed people to share those concepts further than their community. Even if an entire village disappeared, if their writing remained, their ideas could persist.
Both these technologies are so incredibly useful to society that it’s hard to see how progress was made before their invention, and they look a long time to invent. Anatomically modern humans are estimated at 200,000 years ago, spoken language is estimated at 50,000 years ago, and writing is estimated at around 3200 BC. Again, I don’t fault humanity for this. Getting a community to agree on the meanings of arbitrary sounds seems really hard when no one knows what language is. Getting that same group to agree on how those sounds map to written glyphs seems extra hard. It’s a horrible coordination problem.
If the engine of invention is powered by people sharing random ideas until good ones emerge, then I can’t help but wonder if the best inventions are ones that make sharing ideas easier. Social media’s gotten a beating ever since 2016, but I am coming around to the argument that social media increases the volume of both bad information and valuable information. In this view, you can argue for free speech both morally and practically. Morally, people should not have to self-censor. Practically, progress can come from ideas that sound heretical in the present day, and it can be hard to tell whether history will agree with our judgment.
Atomic gardening is insane. Not actually important, I just thought it was cool. Find a source of radiation. Put it in the center of a field. Plant a bunch of crops around the radiation source at varying distances. Hope you get useful mutations. You have basically no control over the results, it’s just random search in genetics space. It’s the kind of crazy idea that could only come from the 1950s, when atomic hype was high and fear about radiation was low. Some grapefruit varieties sold today trace their lineage to atomic gardening, and shooting X-rays at Penicillium molds led to a mutation that 5x-ed penicillin production. I suppose history has judged it as a net positive, but I almost feel personally offended that such a brute force method worked.
-
Six Years Later
CommentsSorta Insightful turns six years old today!
If you’re new, every year I do a meta-post about how my blogging went that year. I’ll be honest - I’ve had a lot less motivation to write this past year. There isn’t a single reason for this. It’s more like a few reasons compounding together.
More Time on Social Media
I haven’t checked how much time I’ve been spending on YouTube and Reddit, but it’s definitely rising. Recommendation algorithms keep getting better.
I know these systems work well on me, so I try to avoid adding social media streams. I don’t have a TikTok or Instagram or Snapchat, since I don’t want to add any many mindless scrolling into my life if I can help it. We’ll see how long that lasts. For better or worse, those are the communication mediums of today, and culture goes forward with or without you.
Puzzlehunt Obligations
This past year, I’ve been doing more work for puzzlehunts. It’s hard work, but it’s fun.
I see puzzle construction as trying to tell a story where you have minimal control over how the story plays out. You’re trying to convey a solve path, but if you make it too obvious then the solve is no longer interesting.
The more relevant part re: this blog is that puzzle constructing is time consuming. It’s like game development. You place the solver in a system, they’ll stretch it in ways you never thought of, and you just have to run around patching up all the holes that become apparent. It’s also a team project with a hard deadline where I can read comments from people who are looking forward to participating. In comparison, this blog is a personal affair, with no strict deadlines or hype trains. That means I’ve felt greater feelings of responsibility and urgency for puzzlehunt writing compared to blogging.
To put hard numbers on this, based on my time tracker, last year I spent about 100 hours on blogging and about 435 hours on puzzlehunt construction. It’s a pretty stark difference.
Interest in my Hobbies are Cooling Down
A number of my posts were me writing about something I was passionate about. I had a post about a My Little Pony x Doctor Who crossover, a post about a My Little Pony x Euclidean geometry crossover, and a post about Neopets. It made sense for me to write them at the time, but I’m less into MLP now, and I’m less into Neopets ever since the site redesign, and I’m just not into fandom as aggressively as I was in 2015 or 2016. I still like MLP and Neopets, and keep up-to-date on what happens in those spaces, but they’re a smaller part of my life.
So when I think about writing a grand post explaining why I got into My Little Pony, it’s a lot harder to do so. When I consider starting a post about why you should read Gunnerkrigg Court, it’s hard because I think about Gunnerkrigg a lot less. There’s always Dominion, but at this point I’m basically retired.
What I’ve realized is that most of my posts are not long-burning posts. They’re works of passion - I bash them out in a few days, or I don’t finish them at all. Sometimes, that passion is a function of the time, rather than anything intrinsic about myself. I told a few people I was going to write an “offline RL manifesto” back in 2018, since I thought it was criminally understudied, but it’s since become a reasonably sized research area and that manifesto no longer feels as important. The post I wanted to write about measurement feels less important now that fairness / interpretability / AI safety is more widely accepted.
I know I just said blogging is a personal activity, but I guess one of my personal activities is writing up hot takes, and takes can’t be hot if you feel they’re already known. I somehow find it more rewarding to create a new point of discussion, rather than adding to or emphasizing an existing one.
I realize this isn’t how writing has to work. Preaching to the choir is fun, after all. However, it’s how I’m approaching writing right now. This is likely why I’ve found puzzle construction to be nice - puzzles deliberately aim to be novel.
Settling Into Patterns
I feel like more of my life has “normalized”, for lack of a better word. By this, I mean that if I picked some arbitrary week 1 month in the future, and made a prediction for what I would do that week, it’d be more accurate than if I did the same exercise a few years ago.
There’s just fewer surprises. I’m not meeting as many people, and I’m doing fewer new things. This is all quite terrifying, to be honest. I’m still figuring out what to do there, but seeing less means I’ve had less inspiration for blogging.
It doesn’t do you much good to draw unless you have something to draw, and the only place you’re getting anything to draw is out of that head. And the only way you can exercise the mind is by bringing new ideas to it so it’ll be surprised, and say “God I didn’t know that.” That’s the greatest thing in the world, that “Gee I didn’t know that.” And there you are, you know?
(Chuck Jones, director of several classic Looney Tunes cartoons. I recommend this Every Frame a Painting video, if you haven’t seen it before.)
I am spending more time on social media…but that doesn’t seem to drive much inspiration for me.
General Tiredness with COVID-19
I stopped blogging about COVID at some point, but I remember believing that things would go back to normal after vaccines were widely available. However, I didn’t account for the degree of vaccine hesitation, as well as the slower rollout of vaccines worldwide enabling evolution of variants that (might) escape vaccines developed so far.
My expectation is that things are and will get better, but last year, I could point to a clear future event (conclusion of widescale vaccine trials). Whereas this year, I don’t have anything to point to besides rising vaccination rates (yay!) and new variants (boo), with an unclear sense on how both will evolve. That’s sapped a lot of energy out of my life in general.
* * *
I’ve considered whether all this means I should stop blogging. As an exercise, I’ve tried imagining the world where I never update this blog again…and it feels really bad. I do care about blogging, so I’ll try to slice out more time towards working on it.
Statistics
Word Count
Last year, I wrote 32,161 words. This year, I wrote 26,955 words.
5812 2020-08-18-ai-timelines.markdown 1112 2020-08-18-five-years.markdown 1549 2020-12-30-car-co2.markdown 6597 2021-01-29-mh-2021.markdown 4249 2021-02-18-flash-games.markdown 5420 2021-04-07-grad-school-5years.markdown 1018 2021-05-23-dominion-temple.markdown 587 2021-05-23-world-can-change.markdown 611 2021-07-05-blog-ads.markdown 26955 totalI wrote 9 posts this year. Some were quite long - this year I averaged 3000 words per post, compared to about 2500 words per post last year.
View Counts
These are the view counts from August 18, 2020 to today, for the posts I’ve written this year.
12426 2020-08-18-ai-timelines.markdown 277 2020-08-18-five-years.markdown 1912 2020-12-30-car-co2.markdown 912 2021-01-29-mh-2021.markdown 167 2021-02-18-flash-games.markdown 2367 2021-04-07-grad-school-5years.markdown 102 2021-05-23-dominion-temple.markdown 210 2021-05-23-world-can-change.markdown 86 2021-07-05-blog-ads.markdownThis mostly tracks what I expected, although I’m surprised the post about Flash games has so few views. Maybe my nostalgia about Flash games is narrower than I thought.
Time Spent Writing
I spent 100 hours, 11 minutes writing for my blog this year, which is about 20 hours less than I spent last year.
That rounds to 16-17 minutes per day, which is actually not too bad for a time commitment (although in practice my blogging is very bursty, rather than writing a few minutes each day).
Posts in Limbo
Post about measurement:
Odds of writing this year: 20%
Odds of writing eventually: 30%If I don’t write this next year I’m going to remove it from my list of pending ideas.
Post about Gunnerkrigg Court:
Odds of writing this year: 45%
Odds of writing eventually: 50%Basically I am saying that if I don’t do it this year, I don’t think it will ever happen and will remove it from this list.
Post about My Little Pony:
Odds of writing this year: 50%
Odds of writing eventually: 90%I cannot see myself never writing about the My Little Pony fandom. It was a huge part of my life, but I’m ready to describe it as was, rather than is. Of course I say this when a lot of my music history is pony EDM…but outside of a few music artists I found via MLP, I’ve stopped caring about a lot of the brony fandom. Much of my enjoyment of MLP was derived from seeing how new episodes were interpreted by the fandom, and so far I have zero hype about Generation 5.
Post about Dominion Online:
Odds of writing this year: 25%
Odds of writing eventually: 50%Post about puzzlehunts:
Odds of writing this year: 70%
Odds of writing eventually: 90%