Posts
-
MIT Mystery Hunt 2021
CommentsThis has spoilers for MIT Mystery Hunt 2021, up through the endgame.
I had two reactions at the end of Hunt this year.
- Wow, that hunt was amazing.
- Wow, that hunt was enormous.
The puzzles were all pretty clean. The round structures were inventive. I didn’t find myself drawn into the story very much - I think because it felt like the motivations of the characters changed, but those changes didn’t affect the narrative goals of the solvers. The standout from this year, however, was the overarching Projection Device. It is completely insane that ✈️✈️✈️Galactic Trendsetters✈️✈️✈️ managed to pull off an MMO, and that leads into the 2nd bullet point.
Game development has the worst ratio for time-spent-creating to time-spent-experiencing. Okay, maybe stop motion animation is more time consuming, but game dev is up there. It’s an unholy mixture of animation, programming, environment design, and level design. To make a game world feel immersive, it needs a certain level of detail, which requires creating lots of assets and interactions to fill up the space. Easter eggs like MITHenge didn’t have to be in the game, but on the other hand they kind of did, because it’s those Easter eggs that make players feel rewarded for exploration, outside of just unlocking puzzles. Adding those details take time. Throwing multiplayer into the mix just makes it worse. For Teammate Hunt, we were already sweating at making 8 Playmate games work, and those were limited to 6-player instances. MIT Mystery Hunt was 3x more participants with way more features and a much larger world.

Now, on top of this, Galactic had to…ah, yes, write a record-setting number of puzzles. I mean, I liked a bunch of them. They hit several cultural niches I liked. But last year, I already said I didn’t think the scale of Hunt was sustainable, and now I feel it definitely isn’t sustainable. I realize it’s weird to say this when Galactic just proved they could make it work, but ✈️✈️✈️Galactic Trendsetters✈️✈️✈️ is a team that’s consistently proven they’re willing to bend over backwards and go to insane lengths to make the puzzlehunt they want to make, even if they have to write a conlang or go nuts on interactive content.
I also know that most people on GT don’t have kids, and some were between jobs when they won Mystery Hunt. Those people essentially put their job searches on hold for a year to work full-time on Mystery Hunt, which is great for us, but not something we should treat as normal. I’m not sure what Palindrome’s time looks like, but I suspect Galactic had an abnormally large amount of time to dedicate to Hunt, due to external circumstances. And so when I imagine a Hunt that tops this one…I’m not sure that’s doable, year after year.
MIT Mystery Hunt has grown before - it’s not like it’s always been this big. So let’s play devil’s advocate. Why shouldn’t we just make Hunt bigger? I’d argue that people don’t want to make their teams much bigger. Here’s the team size graph from this year.

Generally, the large teams don’t go far above 100 members. I think this is partly because constructing teams have warned that Hunt may be less fun above 80 people, and partly because logistics and team culture get harder to cultivate after that size. It’s basically Dunbar’s number. Not everyone likes hunting in a large team, and there’s not much room for the large teams to grow. teammate uses a “invite your friends” system, and through friend-of-friend-of-friends we end up with a sizable Mystery Hunt crew. I think this is the first year where we advised people to slow down their invites, because of concerns we were growing too big.
Now, on the other hand, it’s easy to say Hunt should be shorter when you aren’t writing it, but Palindrome has been aiming to win for a long time, is a fairly large team, and therefore probably has a lot of ideas for the Hunt they want to write. It’s up to them. I will say that I don’t think there’s any shame in shooting for a smaller scope than this Hunt.
Pre-Hunt
My pre-Hunt week is normally spent flying into Boston, ruining my productivity for work, and eating at some Cambridge restaurant I only see once a year. None of that was happening this year, so I got a lot more work done - the main challenge was adjusting to a 9 AM start.
This year, since everyone was remote, we spent more time on our remote solver tooling, moving from a heavily scripted master Google Sheet to a mini webapp with Discord integration. There were some rough edges, but it helped a lot. The killer app was that when we unlocked a puzzle, the bot would auto-create text and voice channels, and when we solved a puzzle it would auto-close those channels.
A bunch of teammates got into NERTS! Online before Hunt. It’s fun, and it’s free! You need at least 3 people to make it worthwhile. The game rewards fast, precise mouse movement, so it might not be for you, but if this xkcd speaks to you,
then consider adding Nerts as a new source of good-natured profanity where you scream “NO I NEEDED THAT”.
I was dismayed at the lack of #ambiguous-shitposting this year, so I made a Conspiracies puzzle. I claimed this was to test our new tooling, but no, it was mostly for the conspiracies. We were considering Baba Is You and Doctor Who for the theme. Baba is You was because of Barbara Yew, and Doctor Who was because of the space theme and mention of different dimensions on the Yew Labs website. We also knew people from Galactic had gotten NYT crosswords published for 6/28 (Tau day) and 9/9 (…Cirno day?). Our conspiracies were all garbage. I expected them to be garbage. All is right with the world.
Once the Hunt site opened, we learned automated answer checkers were back, with a rate limit of 3 per 5 minutes across the entire round. Last year, teammate had a much-memed 10% confidence threshold for guessing, and we didn’t think that would work with the new rate-limit. We had some time to hash out our strategy, and decided that any coordination would spend more time than figuring out the throttling if and only if we needed to. So we mostly used a similar system - anyone guess anything you want, and if you’re rate-limited, let the team know and we’ll coordinate it then. This year we suggested a 30% confidence threshold, and that seemed to work fine - we were sometimes rate-limited, but never in an important way.

In practice, there was usually only 1 puzzle per round where people wanted to spam guesses, so the per-round limit was essentially a per-puzzle limit. Looking at guess stats, we made plenty of wrong guesses, but were dethroned from our dubious distinction of most guesses by Cardinality and NES.
While waiting for puzzle release, I decided to poke around the source code. For the record, this was before the warning to never reverse-engineer the Projection Device. I found a solve-sounds.js file, which loaded solve sounds with this code snippet:
const s = round.toLowerCase(); const a = s.charCodeAt(1); const b = s.charCodeAt(2); var h = (a+2*b) % 24; if (ismeta && link[8] == 'e' && h == 14) { h--; } const filename = '/static/audio/' + h + '.mp3';Notably this meant the asset filename was always from 0.mp3 to 23.mp3…and there was no auth layer blocking access to those files, so we could browse all the solve sounds before the puzzles unlocked. Not all the numbers are defined, I’ve left out the dead links in the table below.
1.mp3 2.mp3 3.mp3 4.mp3 5.mp3 6.mp3 7.mp3 8.mp3 9.mp3 10.mp3 11.mp3 12.mp3 13.mp3 14.mp3 22.mp3 The first one I checked was 1.mp3, so you can imagine my surprise when I started hearing Megalovania. The EC residents on our team were more surprised that 13.mp3 was the EC Fire Alarm Remix. We tried to pair solve sounds to round themes, since we had time to burn, and our guesses were kind of right, but mostly wrong.

The solve sounds were all just oblique enough that I didn’t get spoiled on any of the round themes. I also suspect some are either debug sounds, or deliberate red herrings. Of the unused ones, 5.mp3 is You Are a Pirate from Lazy Town, which could map to the Charles River events. 8.mp3 is Super Mario 64 Endless Stairs, which definitely feels like an Infinite Corridor placeholder. 11.mp3 is from Super Mario Galaxy, which is why we were guessing a Mario round, but maybe it was just a space themed placeholder for Giga/Kilo/Milli solves. My pet theory is that it was going to play just for solving Rule of Three, because that meta auto-solved with GALAXY, and a custom solve sound would mark it as important to check out.
I guess this is also a reminder for hunt writers that I’m the kind of person who clicks View Page Source on every hunt website, unless I’m told not to, so let me know early if I shouldn’t. I don’t think the solve sounds leaked much, but from the code we likely could have inferred that East Campus would be a metapuzzle of a future round, if we didn’t get distracted by puzzle release.
Yew Labs
Don’t Let Me Down - I got directed to this puzzle because “OMG, Alex this puzzle has Twilight Sparkle in it!” I checked, and it was much less pony than advertised, but I went “Oh this is the scene where she’s holding on to Tempest Shadow. Oh, that fits the title and the blanks. Alright let’s do this.” It was pretty fast from there.
✏️✉️➡️3️⃣5️⃣1️⃣➖6️⃣6️⃣6️⃣➖6️⃣6️⃣5️⃣5️⃣ - This was a ton of fun. The rate limiting on the text replies got pretty bad, and the optimal strategy would have been for me to move to another puzzle, since each minipuzzle was pretty easy and we only needed like 1-2 texters, but I was having too much fun and needed to see how the emojis were going to end.
By the time we finished that puzzle, we had made good progress on the round, and I was surprised we didn’t have the meta yet. Going into hunt, I wasn’t sure how much Galactic would gate their metas. The intro round made me worried that we’d be hard gated well after we could have figured out the meta if it were open from the start of the round, since we had the mechanic early and just needed the keyboard image to resolve the last bit of uncertainty. This never ended up being an issue for us - at the time of meta unlock, we usually still needed more feeders to solve them. (Aside from Giga/Kilo/Milli, but I’ll get to that later.)
Unmasked - Hey, a Worm puzzle! I saw it was tagged as “worm, parahumans ID”, and was all excited to do IDing, but by the time I got there it was already done. My contribution was reading the flavortext and pointing out we should track the survivors of the Leviathan fight.
A fun bit of Worm trivia: in the debrief meeting before the Leviathan fight, Legend says that statistically, they expect 1 in 4 capes to die. This was real - the author rolled dice for every character, including the protagonist, and wrote the fight around the deaths. No one was safe. If Taylor died, the new protagonist would have been someone in the Wards. If you were ever curious why no one in that fight had plot armor, now you know.
Infinite Corridor
This was my favorite round of the Hunt. It was just so weird. The round technically has 100,000 puzzles, but really those 100,000 puzzles are variations of 5 different types of puzzles. I had a lot of fun cataloguing the differences between different instances of the same puzzle family. I’m also glad I jumped on this round early, because the later in the round we got, the more incomprehensible our discussions were to newcomers.
This round also broke our new puzzle bot. Our Discord server grouped all puzzles for a round into a single category. Each category is limited to 50 channels, but it’s not like we’re going to have a round with over 50 puzzles in it, right?
Cafe Five - There was something vaguely meditative about solving Cafe Five. Nothing complicated, just serve the customers, and do it fast. It is admittedly similar to Race for the Galaxy from GPH 2019, but having comps and less punishing penalties on failure helped make it more fun. We successfully served L. Rafael Reif once, and comped him every other time.
Library of Images - I’m still not sure how we got the right ideas for this puzzle. We were also pretty confused our single letter answer was correct. I understand why after the fact, but good thing we had someone willing to submit H as an answer.
Unchained - We never figured out this puzzle, even when we tried to forward solve it knowing the answer. In retrospect, our main issue was that we weren’t counting the right things, and maybe should have listened to the songs more, rather than just looking at their lyrics.
Make Your Own Word Search - Annoyingly, the Bingo teammate used this year had “Make your own logic puzzle” as a Bingo square, but a word search isn’t a logic puzzle. Our strategy was to unlock 5 different Make Your Own Word Search instances, check all their rules, then solve just the one that seemed easiest. We ended up going for Puzzle 27. (Everyone loves 27. It’s truly the best number, only surpassed by 26.) By aggressively sharing letters between words, we were able to build it with a lot of unused space that was easy to fill, unlocking…
Infinite Corridor Simulator - We started by doing a ton of frequency analysis, which helped us backsolve one of the Unchained instances. I joined the group that tried to reconstruct the Unchained solve, while the other group tried to extract ICS. The Unchained group got stuck and I drifted back to the ICS puzzle, which had figured out 4 of the 5 extractions and was close on the 5th. Our first theory was that we would extract from the digits of pi that Library of Images corresponded to (i.e. first 7 means the answer in the first 7 of pi’s digits), but after figuring out the Library of Images extraction we tried the more obvious thing.
Infinite Corridor - I feel we split up work pretty well on this puzzle. One person wrote a scraper to programmatically build a list of Infinite Corridor puzzles. Around three of us strategized which instances of Library of Images / Cafe Five / etc. to solve. The last group manned the Cafe, since we knew we needed more tokens. Our strategy was to find the 3rd letter of FIRST / SECOND / THIRD / FOURTH / FIFTH, since that uniquely identifies between the five. Then, the 3rd letter of ZERO / ONE / TWO / THREE / SIX / SEVEN / EIGHT / NINE identifies the digit uniquely in 6/10 cases, and only needs one more letter check to clear up the last 4/10 cases.
Unchained was stuck, and we thought solving more Word Searches would take time, so our aim was to get the other 3 digits exactly, narrow the target down to 100 rooms, move to all the rooms in parallel to unlock them, then solve all ICS puzzles in that set of 100. We ended up solving a second strategic Make Your Own Word Search, which narrowed the room set to 40 options, or 8 ICS puzzles in expectation. We found the meta answer on the 3rd one. Unfortunately, since we were solving ICS by script, none of us noticed that room 73178 was an exact replica of the real Infinite Corridor, until Galactic heavily hinted this was true during the final runaround.
I like this round the most because it had this perpetual sense of mystery. How are we going to have several versions of the same puzzle? How would a 100,000 puzzle meta even work? It was neat that the answer got answered recursively, in a way that still left the “true” meta of how to repeat the extraction without solving 100,000 puzzles.
One of the cool things about MIT Mystery Hunt is that you’re continually evaluating what rounds are important / not important to funnel work towards. It was neat that Infinite Corridor was a small version of that kind of planning, embedded within a single round of the Hunt.
We didn’t get the low% clear for fewest solves before Infinite Corridor meta. Puzzkill got there with 1 fewer solve 😞. We did get the first main round meta solve though, and I’m proud of that.
Green Building
Dolphin - A fun puzzle about Gamecube trivia. I helped on the first subpuzzle after we got the a-ha, then set up formulas for the final extraction. We got stuck a bit by assuming we wanted the face that touched the Gamecube, rather than the number that was face-up, but we got there eventually.
Green Building - We got the Tetris a-ha pretty quickly, without the 5-bit binary hint. I think LJUBLJANA was the one that confirmed our suspicions. After doing a few grids, we went down an enormous rabbit hole, where we assumed we would find the number of lines we would attack with if we were following standard Tetrix Battle rules. That number would then become an index. This actually gave okay letters, our partial started AMAR???T????. The Green Building round page was arranged with Switch #1 on the bottom, so we thought we might read 13 to 1 which could give a phrase ending in DRAMA. Indexing by attack into LJUBLJANA gave a J, but the Tetris solution for LJUBLJANA was especially weird, so we thought the answer might go to a switch we didn’t have yet. We were stuck there for hours, and then someone said “hey, have you noticed the first letters of the answers spell CLEAR ALL V”?
We were scheduled for the Green Building interaction right away, and I’m pretty sure I started the Zoom call by saying “I’m so angry”, so if anyone from Galactic is reading this - I wasn’t angry at you! Your meta was fine! I was just salty we overcomplicated it.
Stata Center
Extensive - This was the only puzzle I did in this round. It played well with my skill sets (willingness to try a lot of garbage ideas on technical data). After working at it, we got all the letters except for the MIDI file and DOC file. The DOC file was partially done, and we were half-convinced it didn’t have a 3rd letter, which made our Nutrimatic attempts a lot worse.

I’m thankful that the computational geometry class I took was mildly useful - not because we needed to do any computational geometry, but because it taught me how to read and edit PLY files by hand.
We did have some tech issues around opening the DOC file. I think it was especially pronounced for us because this was a tech puzzle, so the people who self-selected for it were more likely to have Linux. OpenOffice worked for some people and didn’t work for others.
⊥IW.giga/kilo/milli
This round was another one with strange stucture. At each level, the metapuzzle was autosolved on unlock. One puzzle in the round was unsolvable forward, and you need to reconstruct the meta mechanic from the known answer to backsolve that puzzle. That backsolved puzzle then became the presolved metapuzzle for the next level down. The metas were Rule of Three, Twins, Level One, and ⊥IW.nano.
teammate had an unusually easy time with this round. It’s odd to say “unusually easy” when it took our team 12 hours to break through the first level of 8 puzzles, but this was still faster than other teams. This write-up follows the linking used in the solution page - a link to Twins means a discussion about backsolving Twins from Rule of Three.
Twins - I didn’t look at this round until people were trying to backsolve. We had solved every puzzle except Twins and A Routine Matter. Based on Rule of Three auto-solving on unlock, we correctly inferred that Twins needed to be backsolved. Or more specifically, every other puzzle looked forward solvable, and Twins did not. (This did not stop people from trying, but the image was just too small, didn’t have clear steganography inroads, and we were making progress on everything else.)
In my opinion, our solve was very lucky. Based on searching a few of the dates, the team had figured out planetary syzygies, and due to general flavor we suspected the backsolved answer would correspond to Earth. If you read the solution, every syzygy uses either Twins or A Routine Matter…which were exactly the two puzzles we didn’t have. We did, however, have TWIX, and saw it was the center planet for the X in GALAXY. Here is the first stroke of luck - we had errors in our other syzygies, but they weren’t on the X that sparked the later ideas.
Rule of Three didn’t have the image during our solve, so we were flying blind on what to do next. A teammate proposed the “common letters give index” extraction, but wasn’t sure about it. However, someone else noted that if assumed the 2nd letter of A Routine matter was O, then it would extract both the L and A of GALAXY. We pursued it a bit, and got letter constraints G???E* on Twins, at which point someone YOLO-guessed GLOBE and got it.
Maybe that solve doesn’t sound too crazy, but each step taken was an unsteady leap made off another unsteady leap. These leaps are the way to solve puzzles quickly, but they’re also the exact way you jump into the wrong rabbit hole. It was important that we had the answer TWIX, that we didn’t have errors in our data for that syzygy, that we took the proposed extraction mechanism seriously even as the person proposing it later admitted they didn’t think it would work, and that we had someone willing to try low confidence guesses. It’s a very weird situation - normally, at least one person in a solve has conviction in all the mechanics. In our case, it was more like three camps with 1/3rd of the conviction, pooling it together because we didn’t have better ideas.
Button Press - Technically part of the Athletics round, but aside from Building Hacks, this was the only field goal I did during Hunt. I was excited to do more with the Projection Device, but because of how it worked, you had to be first person exploring an area to get the new puzzle unlocks, find new field goals to achieve, etc. I let Infinite Corridor take me and by the time I emerged people had found all the Students we had access to.
How to Run a Puzzlehunt - I think this was a puzzle where I knew too much. I had looked at a ton of gph-site code when writing Teammate Hunt, and somehow argued that the GPH repo wouldn’t have puzzle data, since I didn’t see any new commits and hadn’t noticed anything suspicious in the older ones. We ended up backsolving this one.
Level One - A few of us mentioned sister cities right when we unlocked Twins, but didn’t try it for a while. In particular, I thought sister cities and twin cities were the same thing, but when I learned they were different, I tried twin cities and dropped the thread since I couldn’t get them to work. We tried some crazier extraction ideas, but eventually someone tried sister cities more seriously and it clicked into place. It took writing this post to learn that sister cities are also called twin towns - now I finally get the title! We probably could have solved this from 1 feeder, because once we got sister cities to work for 1 answer we jumped straight to backsolving. We assumed the backsolve city would be Boston or Cambridge so that we could zoom into the MIT.nano building, and only one sister city of the two matches the (3 5) enumeration.
Nutraumatic - I don’t know if there’s a name for this kind of puzzle. I’ve started calling them “figure out the black box” puzzles. They’re usually a good time, they allow for a wide variety of solutions and make it easy for the solver to take ownership of their solve path. Whereas in other puzzle types, your solve path is more pre-ordained, and can be less interesting when you foresee more of it. I think it’s pretty funny that both Mystery Hunt and Teammate Hunt had a puzzle that referenced nutrimatic. To be honest, it’s an absurdly busted tool once you get comfortable with it.
⊥IW.nano - We looked at Level One early, in case it was a puzzle we could get early, like Twins. This was a round where having recent MIT students really helped. We found One.MIT quite early, just based on the title. Then with some metaknowledge, I got the MIT alums. (My thought process was, if we need to backsolve a puzzle, then 1 letter is not sufficient. Therefore, we need semantic information. That semantic information is probably related to MIT - let me see if I can find connections between MIT and BuzzFeed…)
Like other teams, we were quite confused about the enormously long arrow, because it didn’t seem like there was content outside the orange circle. One teammate declared “if they aren’t from the centers, then they’re offsets”, which just did not parse to me, but then they made this image for Paul Krugman:

and I was convinced. Since the backsolve was intended, we assumed the arrow pointing to the Y would come from a famous MIT graduate. Otherwise, the backsolve would be really painful, because it would combine name ambiguity from imprecise arrows, with the semantic ambiguity of finding an answer that fit the flavortext and started with T. That seemed like too many degrees of freedom, so we were pretty confident that if we took our 4 remaining arrows, and checked them in parallel, we’d spot something. We found Feynman, finished the round, and abandoned the remaining puzzles due to the previous argument that the “unintended” backsolves would be too hard. That being said….we definitely should have backsolved Questionable Answers.
Clusters
Somehow, the two puzzles I worked on in this round were the two we got super stuck on. Pain. Too bad I missed Game Ditty Quiz.
Altered Beasts - Okay, this one was my fault. I saw it was Transformers, and mentioned there’s a Transformers: Beast Wars series. Every Transformer in that series has a Beast Mode, and Altered Beasts sure sounded like we should transform the beast mode the same way we transformed the Transformer clues. We had trouble finding unambiguous sources for some of them, which should have tipped us off that this was a red herring, but I thought it was a Powerful Metamorphers scenario, where it was only ambiguous due to unfamiliarity with the source material. Despite proposing the idea, I only knew about Beast Wars because of Hasbro knowledge leaking through MTG and MLP, so I wasn’t much help there. It took us a long, long time to decide the beast modes were fake. On the upside, my red herring managed to pollute two teammates’ recommendation profiles.

Balancing Act - This one, we were just totally stuck on how to be chemists. After spending a hint to get started, it wasn’t too bad.
Clusters - Like some other teams, we thought the grid on the round page would be important, but we couldn’t figure out a principled way to fill in the converted words. To the surprise of no one, it’s hard to solve a puzzle when your extraction is fake. The puzzle titles clearly seemed important, and ordering by those looked okay, but we didn’t know why there was one C and two Ds. A teammate went to take a shower, came back, and said “GUYS THE GREEK ALPHABET GOES ABGDE”, and that fixed everything. Showers: the undefeated champions of inspiration.
Students
I didn’t do this round at all, except for…
Student Center - Our first theory was that this would be about playing cards. There were 54 students, which could map to a deck of 52 cards plus 2 jokers. There were 13 unique clubs. On the round page, the meta order was Dorm Row, Simmons Hall, EAsT camPUS, Random Hall. This order didn’t seem obviously unimportant, and the first letters of their answers spelled CARD.
By that point we were hooked. Groups of 4 could mean a trick taking game! “How can we connect?” could mean a pun on bridge! It all seemed very plausible, especially because we hadn’t connected the four dorm answers to the four Greek elements. We only got to elements after staring at “strangely shaped table” for a while - after all, card game tables use normal shapes.
I didn’t solve it, but one more story about Dorm Row: we solved it without noticing the Game of Thrones connection. With some answer shuffling, one person found that Roar → RICHARDTHEFIRST, Family → RAINBOW, and Winter → WHITEFANG gave letters that looked like DRAGONS. They “just really want dragons to happen, man 🐉”, fixed those 3 answers, and successfully nutrimatic-ed out the answer from the potential assignments of the remaining answers. Thus continues a teammate tradition - every year, there is at least one puzzle we solve without understanding how to solve it.
Tunnels
I was waiting the entire Hunt for Megalovania to show up, and it finally happened! Hooray! This was the round I used the Projection Device for the most, contributing up a map of ghost mechanics for each passageway.
🤔 - Like the solution says, this grid is such garbage, but it’s also beautiful. It’s the simultaneous horror and admiration you get from a Neil Cicierega mashup. All I did was ID the Steamed Hams Puflantu clip, but 10/10 concept.
Bingo - Here’s my reaction when we unlocked this puzzle.

For a while, I had a vague plan to use my Bingo page the next time I got to write for MIT Mystery Hunt. So, finding out I got scooped was incredibly shocking, especially because my Bingo site says it’s not a puzzle. Astute readers will note that my site isn’t a puzzle, but that doesn’t mean the Perpendicular Institute’s Bingo can’t be a puzzle! Fine. FINE. I got trolled, well played. And really, I’m honored my dumb Bingo generator got referenced in a Mystery Hunt.
We usually do science on our team log after Hunt, but it was interesting to do so during Hunt to resolve Bingo statements. At the time we unlocked Bingo, we had already shitposted many, many terrible backsolve attempts for Voltage-Controlled. Seeing “Made more than 27 guesses on a single puzzle.” made us double check how many guesses we’d made on that puzzle. The answer was 28. Hmmmmm.
The QR code extraction evolved naturally for us, but we had trouble getting it to scan. Our eventual solve was done by splitting questions into three tiers: statements that had to be TRUE/FALSE to fit QR code structure, statements that were TRUE/FALSE due to concrete examples, and statements that we believed were TRUE/FALSE, but hadn’t exhaustively verified. Then we split up and randomly toggled statements from the 3rd tier in parallel, until the code scanned. I got the eventual solve, which made me happy. My one complaint is that we had “Puzzle about Among Us” marked as TRUE, because IDing it was one question in Cafe Five, but it needed to be FALSE. It was in the 1st tier, so it wasn’t too big an issue, but I think it subconsciously made me ignore Cafe Five when considering the other statements.
It’s Tricky - There was a call for people who knew how the Tunnels ghosts worked. I joined, noticed a few matches right away, and recruited help from other Tunnels navigators. We then kinda commandeered the puzzle and stole ownership until it finished. The first two letters I got were K and Z, so I really wasn’t sure we were doing the right thing - luckily the next letters we got looked much better.
Also psssst go watch the TikTok we submitted, it’s so good.
Foundation’s Collection - All I did for this puzzle was link the GOOD SMILE company webpage with a comment that “this looks weeb as f***”, then I dipped to work on something else, because I swear I’m not a weeb. (No, seriously, I haven’t watched anime in 3 years, and the ones I have watched are pretty basic. The only one that isn’t is Bokurano, which is a MESSED UP anime, just incredibly unsettling, but it has some interesting thoughts on morality and mortality and…look, I hit peak anime watching in high school and then stopped afterwards, okay?)
Tunnels - I encouraged a lot of Undertale tinfoil hatting on this meta. We had the answer FLOWER GIRL, so I was definitely looking into some Flowey stuff, checking the number of Undertale endings, wondering if it was RGB due to red stop signs / green circles / blue eyes from Sans, etc. All garbage!
Interactions
Every time we finished a main round, we got an interaction with Hunt staff. I expect these to show up on the Hunt site later, but here are some quick notes for the ones I went to.
Students - I joined this one partway through, so not sure of the details, but I believe we needed to solve each dorm’s problem using the element it was associated to. All I know is that I joined the Zoom call and someone was arguing that using Firefox to search for wood was a good way to help EC’s troubles with their RANDOM LUMBER GENERATOR.
Green Building - To clear all the vines, we needed to play a game of Tetris, where team members posed as the piece we wanted to spawn. I for one was very excited to T-pose our way to victory.
Infinite Corridor - To hire a contractor, we needed to look them up in a phone book with a rather weird sorting mechanism. This took us a lot longer than we expected, and at some point it became a meme that we should hire a contractor whenever we got stuck in a future interaction. After all, we can hire a contractor to do anything!
Athletics - This was a game of Just One, flavored as one person catching the ball and everyone else throwing. The email recommended 10 people. We had 40. Playing Just One in a group of 40 people was a complete disaster and totally worth it.
⊥IW.nano - We played a real-life text adventure, similar to getting Ryan North out of the hole, in order to pass objects from ⊥IW.giga down to ⊥IW.nano. I really wanted to crack a joke about the portals DMK key puzzle in Problem Sleuth, because it was basically that, but IDK how many people would get it.
Stata Center - To iron out the inks, we needed to bring out our irons. We had some real irons, then it devolved into forks that are definitely made of iron, pieces of paper that said Fe on them, etc. I own a life size Iron Sword from Minecraft (won it from a hackathon), so my contribution was wildly waving a sword that was definitely made of iron, not foam.
Clusters - In this one, the Athena and Minerva clusters each spoke different “languages”, and didn’t like each other’s names. We first needed to figure out their languages, which were similar to Pig Latin, except parsing a spoken Pig Latin variant is harder than it sounds. Once we figured out the language, we needed to ask them questions in their language, to figure out why they didn’t like each other’s name, and come up with a name both of them liked. That ended up being Kerberos, a punny answer on many levels.
Tunnels - This was a game of Keep Puzzling and The Tunnels Will be Fixed. The participants were split into two separate Zoom rooms. One group got the puzzle data, and the other group got the puzzle solution, without the data. Periodically, the group with the solution was allowed to send a small number of characters to describe the solution, which the other group needed to parse to figure out how to extract. The communication started at 5 characters, then got bigger if your team needed it.
Closing Thoughts
Not only did we solve the Bingo puzzle, we got a triple Bingo on our real Bingo board! The third Bingo relied on “Metapuzzle solved with fewer than half the answers”, which I violently argued was true for Infinite Corridor, given that we used < 50000 answers. Then we got it for real in Nano, so it wasn’t up for debate.
Funnily enough, I felt I got more out of the MIT part of MIT Mystery Hunt this year, despite the Hunt running remotely. teammate normally has plenty of MIT affiliation, so I usually defer on-campus puzzles to people who actually know MIT campus. In this Hunt, it still helped to know the MIT layout…but there was also a minimap. Seriously, the minimap probably 3x-ed my enjoyment of the Projection Device, I would have been so lost without it, and referring to it so often meant I learned the real MIT campus layout a bit better. Why can’t real life have fast travel, and maps that work well when your phone is indoors :(
I had a great time, and hopefully next year the world will be in a good enough place to run Hunt in person. It’s hard to say for sure…but I think it should be. Until next time.


Oh, one last thing…

TAME MEAT LIVES!!!!!
-
Carbon Footprint Comparison for Gas and Electric Cars
CommentsMy car’s dead. It went through a long series of death throes, almost making it all the way through the pandemic, but now it’s dead, and the price of fixing it is too high.
I still need a car! You can get away without one in SF, but I live in South Bay, and South Bay is still a sprawling suburban hellscape if you don’t have a car.
I also want to consider the carbon footprint of my decision. What should I do?
* * *
First off - electric, hybrid, or gas? This is supposed to be obvious, but maybe it’s not. In high school, one of my teachers claimed that a new Toyota Prius was worse for the environment than a new Hummer over the course of its lifetime, because the CO2 emitted during production time was much higher and the gas savings didn’t make up the difference. I never checked this claim, and it was 10 years ago. Let’s see if it still holds up with the advances in battery production.
The European Parliament has an infographic for lifetime CO2 emissions from different kinds of cars, from 2014.

The green bars are the share from vehicle production. The top bar is a gasoline car, the second bar is a diesel car, and the last 3 are electric cars under different assumptions of clean power. Lifetime CO2 emissions are measured in g/km, assuming a 150,000 km mileage. This is about 93,000 miles for the Americans out there. Unfortunately I wasn’t able to find the primary source for this chart, but at a glance electric cars do pay a higher up-front cost in CO2 emissions. It’s 62.5g CO2/km versus 50g CO2/km, a 25% increase. However, this is later offset by the decreased emissions from power generation. The exact difference depends on how clean your electricity is. At the extreme ends, an electric car powered by electricity from coal is worse than a gasoline car! On average though, it looks good for the electric car, 170 g/km compared to 220 g/km for a gas car.
A 2018 brief from the International Council on Clean Transportation found similar conclusions. They compared an average conventional car, an efficient internal combustion car (the 2017 Peugeot 208, which gets 65.7 mpg), and an electric vehicle (the 2017 Nissan Leaf). The Nissan Leaf won out.

Electric vehicles should have larger gains than the ones shown here, because these numbers are based on a lifetime mileage of 93,000 miles. Most EVs I’ve looked at come with a 8 year, 100,000 mile warranty on their batteries. Power grid electricity is greener than burning gasoline, so underestimates of mileage are worse for electric cars when comparing their emissions.
Interestingly, for Germans, an electric car is only on par with an efficient gas car, since their power grid is more carbon heavy. For the French and Norwegians, it’s amazing, and this is part of the argument for electric vehicles I find most compelling: gas vehicles are forever locked into using gasoline, whereas electric vehicles will become greener over time as power grids move towards renewable energy. Electricity is inherently more fungible, it doesn’t matter where it comes from, and if more of the transportation network moves to electric, it reduces lock in of suboptimal technology.
If you live in the US and are curious, the Alternative Fuels Data Center (AFDC) from the Department of Energy has a tool that lets you estimate annual emissions for different kinds of vehicles, with breakdowns by state. Their US average says a gas car produces 11,435 pounds of CO2 annually, a hybrid produces 6,258 pounds of CO2 annually, and an electric car produces 4,091 pounds of CO2 annually. In California, the electric car produces 1,960 pounds of CO2 annually, less than half the national average, thanks to heavier usage of solar and hydropower.
* * *
We’ve now established that the obvious answer is the correct one: electric cars produce less CO2 over their lifetime. Now, used or new?
Consider the chart from before. Around \(50/220 \approx 25\%\) of the lifetime emissions for a gas car come from manufacturing. For electric cars, its \(62.5/170 \approx 35\%\). As added confirmation, I checked the gas car numbers against other sources. This 2010 Guardian article finds that producing a medium-sized car produces 17 tonnes of CO2. The EPA greenhouse gas guidelines from 2020 estimates gas cars emit 4.6 tonnes of CO2 per year. The average age of cars in the US is 11.9 years, an all-time high. Using those numbers gives \(17 / (17 + 4.6 \cdot 11.9) = 23.7\%\) for gas cars, which is close enough to \(25\%\).
The three Rs go reduce, reuse, recycle, and that’s the order of priority. If you don’t need a car, that’s still the best, but reusing an old car offsets producing 1 new car. That immediately cuts your environmental impact by 25%-35%. Right?
Well, it depends how far you want to carry out the consequentialist chain. Say you buy a used car directly from someone else. That person likely needs a replacement car. If they replace it with a new car, then you haven’t changed anything. You still caused 1 new car to be manufactured, along with all the emissions that entails. In reality, not everyone will replace their car, so buying a used car is equivalent to producing some fraction of a new car. If that fraction is \(p\), then you save \(p\cdot 30\%\) of the emissions. But what’s \(p\)? Intuitively, \(p\) is probably close to 100%, since people need transportation, but is there a way we can estimate it?
As a simple model, let’s assume that everyone owns 0 or 1 car, and everyone acts identically. After someone sells their car, they have a XX% chance of not replacing it, a YY% chance of buying a new car, and a ZZ% chance of buying a used car from a third person. If the last case happens, that third person no longer has a car, and has the same choice of if and how they want to replace it. We can define the fraction of new cars (\(p\)) in a recursive way, where the first two cases are base cases.
\[p = x \cdot 0 + y \cdot 1 + z \cdot p\]Solving for \(p\) gives \(p = y/(1-z) = y / (x+y)\). In other words, it’s the number of new car sales, divided by (new cars + people who don’t replace their car). Counting new car sales is easy, because it directly affects revenue of automakers, and anything that affects revenue gets measured by everybody. Projections put it at 17.3 million new cars in 2018. Counting people who don’t replace their car is harder, but we can use numbers from the Bureau of Transportation Statistics. There are fluctuations between each year, but if we consider the 2013-2018 time span, the number of vehicle registrations increased by 18 million. So let’s say 3.6 million vehicle registrations per year. This is the net increase, so \(17.3-3.6 = 13.7\) million vehicles leave the road each year. Let’s treat 13.7 million as the number of cars that don’t get replaced. Then we get
\[p = 17.3 / (17.3 + 13.7) = 0.558\]This is a lot smaller than I expected, I thought it would be closer to 0.8 than 0.5. The Transportation Statistics numbers include aircraft and boats in their vehicle registrations, so I’m likely overestimating the denominator, meaning I’m underestimating \(p\). Let’s round up and say buying a used car leads to about 0.6 new cars. This saves 0.4 new cars of production, and you can expect a \(0.4 \cdot 30 = 12\%\) cut to environmental impact.
* * *
Combining it all together, even if you use the most efficient gas vehicle, and buy it used, you will struggle to do as good for the environment as buying a new electric vehicle. The ICCT brief estimates a 60+ mpg conventional car at 180 g CO2/km. Buying it used gives a 12% cut, to 158.4 g CO2/km. The same ICCT brief estimates electric vehicles at 130 g CO2/km, while the EU parliament infographic estimates them at 170 g CO2/km. Perhaps you’ll do better, but it won’t be by much.
California residents can expect their electric cars to be much better for the environment, thanks to more investment in green power. Other states may get smaller gains, but I estimate a 25%-50% reduction in lifetime CO2 emissions compared to a conventional car.
If you’re concerned about how regularly you can charge your car (like me), then you could consider a plug-in hybrid. These cars come with a smaller battery that lets them use electric power for short drives, then switch to hybrid mode (using gas) once that runs out. The CO2 emissions will depend on how diligent you are about charging the battery, but if your commute is short, it’ll be almost equivalent to a pure electric car with the option to fallback on gasoline.

-
My AI Timelines Have Sped Up
CommentsFor this post, I’m going to take artificial general intelligence (AGI) to mean an AI system that matches or exceeds humans at almost all (95%+) economically valuable work. I prefer this definition because it focuses on what causes the most societal change, rather than how we get there.
In 2015, I made the following forecasts about when AGI could happen.
- 10% chance by 2045
- 50% chance by 2050
- 90% chance by 2070
Now that it’s 2020, I’m updating my forecast to:
- 10% chance by 2035
- 50% chance by 2045
- 90% chance by 2070
I’m keeping the 90% line the same, but shifting everything else to be faster. Now, if you’re looking for an argument of why I picked these particular years, and why I shifted by 10 years instead of 5 or 15, you’re going to be disappointed. Both are driven by a gut feeling. What’s important is why parts of my thinking have changed - you can choose your own timeline adjustment based on that.
Let’s start with the easy part first.
I Should Have Been More Uncertain
It would be incredibly weird if I was never surprised by machine learning (ML) research. Historically, it’s very hard to predict the trajectory a research field will take, and if I were never surprised, I’d take that as a personal failing to not consider large enough ideas.
At the same time, when I think back on the past 5 years, I believe I was surprised more often than average. It wasn’t all in a positive direction. Unsupervised learning got better way faster than I expected. Deep reinforcement learning got better a little faster than I expected. Transfer learning has been slower than expected. Combined, I’ve decided I should widen the distribution of outcomes, so now I’m allocating 35 years to the 10%-90% interval instead of 25 years.
I also noticed that my 2015 prediction placed 10% to 50% in a 5 year range, and 50% to 90% in a 20 year range. AGI is a long-tailed event, and there’s a real possibility it’s never viable, but a 5-20 split is absurdly skewed. I’m adjusting accordingly.
Now we’re at the hard part. Why did I choose to shift the 10% and 50% lines closer to present day?
I Didn’t Account for Better Tools
Three years ago, I was talking to someone who mentioned that there was no fire alarm for AGI. I told them I knew Eliezer Yudkowsky had written another post about AGI, and I’d seen it shared among Facebook friends, but I hadn’t gotten around to reading it. They summarized it as, “It will never be obvious when AGI is going to occur. Even a few years before it happens, it will be possible to argue AGI is far away. By the time it’s common knowledge that AI safety is the most important problem in the world, it’ll be too late.”
And my reaction was, “Okay, that matches what I’ve gotten from my Facebook timeline. I already know the story of Fermi predicting a nuclear chain reaction was very likely to be impossible, only a few years before he worked on the Manhattan Project. More recently, we had Rémi Coulom state that superhuman Go was about 10 years away, one year before the first signs it could happen, and two years before AlphaGo made it official. I also already know the common knowledge arguments for AI safety.” I decided it wasn’t worth my time to read it.
(If you haven’t heard the common knowledge arguments, here’s the quick version: it’s possible for the majority to believe AI safety is worthwhile, even if no one says so publicly, because each individual could be afraid everyone else will call them crazy if they argue for drastic action. This can happen even if literally everyone agrees, because they don’t know that everyone agrees.)
I read the post several years later out of boredom, and I now need to retroactively complain to all my Facebook friends who only shared the historical events and common knowledge arguments. Although that post summary is correct, the ideas I found useful were all outside that summary. I trusted you, filter bubble! How could you let me down like this?
Part of the fire alarm post proposes hypotheses for why people claim AGI is impossible. One of the hypotheses is that researchers pay too much attention to the difficulty of getting something working with their current tools, extrapolate that difficulty to the future, and conclude we could never create AGI because the available tools aren’t good enough. This is a bad argument, because your extrapolation needs to account for research tools also improving over time.
What “tool” means is a bit fuzzy. One clear example is our coding libraries. People used to write neural nets in Caffe, MATLAB, and Theano. Now it’s mostly TensorFlow and PyTorch. A less obvious example is feature engineering for computer vision. When was the last time anyone talked about SIFT features for computer vision? Ages ago, they’re obsolete. But feature engineering didn’t disappear, it just turned into convolutional neural net architecture tuning instead. For a computer vision researcher, SIFT features were the old tool, convolutional neural nets are the new tool, and computer vision is the application that’s been supercharged by the better tool.
Whereas for me, I’m not a computer vision person. I think ML for control is a much more interesting problem. However, you have to do computer vision to do control in image-based environments, and if you want to handle the real world, image-based inputs are the way to go. So for me, computer vision is the tool, robotics is the application, and the improvements in computer vision have driven many promising robot learning results.

(Filters automatically learned by AlexNet, which has itself been obsoleted by the better tool, ResNets.)
I’m a big advocate for research tools. I think on average, people underestimate their impact. So after reading the hypothesis that people don’t forecast tool improvement properly, I thought for a bit, and decided I hadn’t properly accounted for it either. That deserved shaving off a few years.
In the more empirical sides of ML, the obvious components of progress are your ideas and computational budget, but there are less obvious ones too, like your coding and debugging skills, and your ability to utilize your compute. It doesn’t matter how many processors you have per machine, if your code doesn’t use all the processors available. There are a surprising number of ML applications where the main value-add comes from better data management and data summarizing, because those tools free up decision making time for everything else.
In general, everyone’s research tools are deficient in some way. Research is about doing something new, which naturally leads to discovering new problems, and it’s highly unlikely someone’s already made the perfect tool for a problem that didn’t exist three months ago. So, your current research tools will always feel janky, and you shouldn’t be using that to argue anything about timelines.
The research stack has lots of parts, improvements continually happen across that entire stack, and most of these improvements have multiplicative benefits. Multiplicative factors can be very powerful. One simple example is that to get 10x better results, you can either make one thing 10x better with a paradigm shift, or you can make ten different things 1.26x better, and they’ll combine to a 10x total improvement. The latter is just as transformative, but can be much easier, especially if you get 10 experts with different skill sets to work together on a common goal. This is how corporations become a thing.
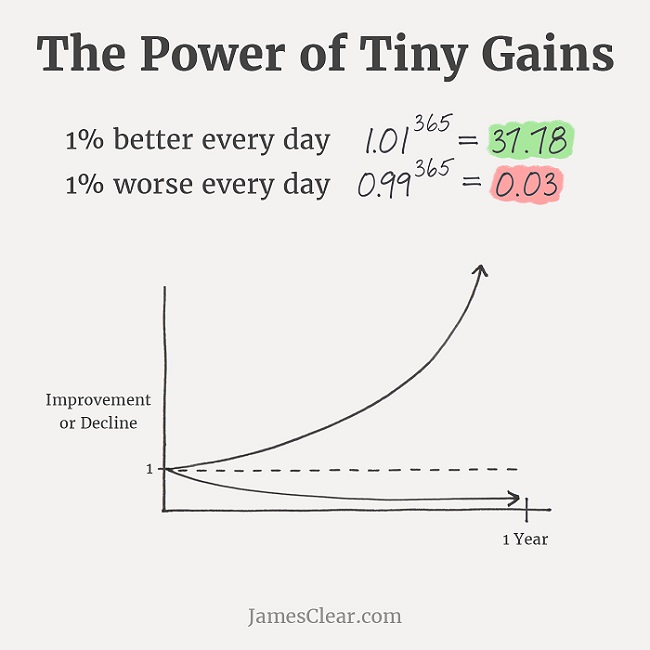
(From JamesClear.com)
Semi-Supervised and Unsupervised Learning are Getting Better
Historically, unsupervised learning has been in this weird position where it is obviously the right way to do learning, and also a complete waste of time if you want something to work ASAP.
On the one hand, humans don’t have labels for most things they learn, so ML systems shouldn’t need labels either. On the other hand, the deep learning boom of 2015 was mostly powered by supervised learning on large, labeled datasets. Richard Socher made a notable tweet at the time:
Rather than spending a month figuring out an unsupervised machine learning problem, just label some data for a week and train a classifier.
— Richard Socher (@RichardSocher) March 10, 2017I wouldn’t say unsupervised learning has always been useless. In 2010, it was common wisdom that deep networks should go through an unsupervised pre-training step before starting supervised learning. See (Erhan et al, JMLR 2010). In 2015, self-supervised word vectors like GloVe and word2vec were automatically learning interesting relationships between words. As someone who started ML around 2015, these unsupervised successes felt like exceptions to the rule. Most other applications relied on labels. Pretrained ImageNet features were the closest thing to general behavior, and those features were learned from scratch through only supervised learning.
I’ve long agreed that unsupervised learning is the future, and the right way to do things, as soon as we figure out how to do so. But man, we have spent a long time trying to do so. That’s made me pretty impressed with the semi-supervised and unsupervised learning papers from the past few months. Momentum Contrast from (He et al, CVPR 2020) was quite nice, SimCLR from (Chen et al, ICML 2020) improved on that, and Bootstrap Your Own Latent (Grill, Strub, Altché, Tallec, Richemond et al, 2020) has improved on that. And then there’s GPT-3, but I’ll get to that later.
When I was thinking through what made ML hard, the trend lines were pointing to larger models and larger labeled datasets. They’re still pointing that way now. I concluded that future ML progress would be bottlenecked by labeling requirements. Defining a 10x bigger model is easy. Training a 10x bigger model is harder, but it doesn’t need 10x as many people to work on it. Getting 10x as many labels does. Yes, data labeling tools are getting better, Amazon Mechanical Turk is very popular, and there are even startups whose missions are to provide fast data labeling as a service. But labels are fundamentally a question about human preferences, and that makes it hard to escape human labor.
Reward functions in reinforcement learning have a similar issue. In principle, the model figures out a solution after you define what success looks like. In practice, you need a human to check the model isn’t hacking the reward, or your reward function is implicitly defined by human raters, which just turns into the same labeling problem.
Large labeled datasets don’t appear out of nowhere. They take deliberate, sustained effort to generate. There’s a reason ImageNet won the Test of Time award at CVPR 2019 - the authors of that paper went out and did the work. If ML needed ever larger labeled datasets to push performance, and models kept growing by orders of magnitude, then you’d hit a point where the amount of human supervision needed to make progress would be insane.
(This isn’t even getting into the problem of labels being imperfect. We’ve found that many labeled datasets used in popular benchmarks contain lots of bias. That isn’t surprising, but now that it’s closer to common knowledge, building a large dataset with a laissez-faire labeling system isn’t going to fly anymore.)
Okay. Well, if 10x labels is a problem, are there ways around that problem? One way is if you don’t need 10x as many labels to train a 10x larger model. The messaging on that is mixed. One scaling law paper, (Hestness et al, 2017), recommends a model size that grows sublinearly with dataset size.
We expect that number of model parameters to fit a data set should follow \(s(m) \propto \alpha m^{\beta_p}\), where \(s(m)\) is the required model size to fit a training set of size \(m\).
(From Section 2.2)
Different problem settings have different coefficients. Image classification followed a \(\beta_p=0.573\) power law, while language modeling followed a \(\beta_p \approx 0.72\) line.
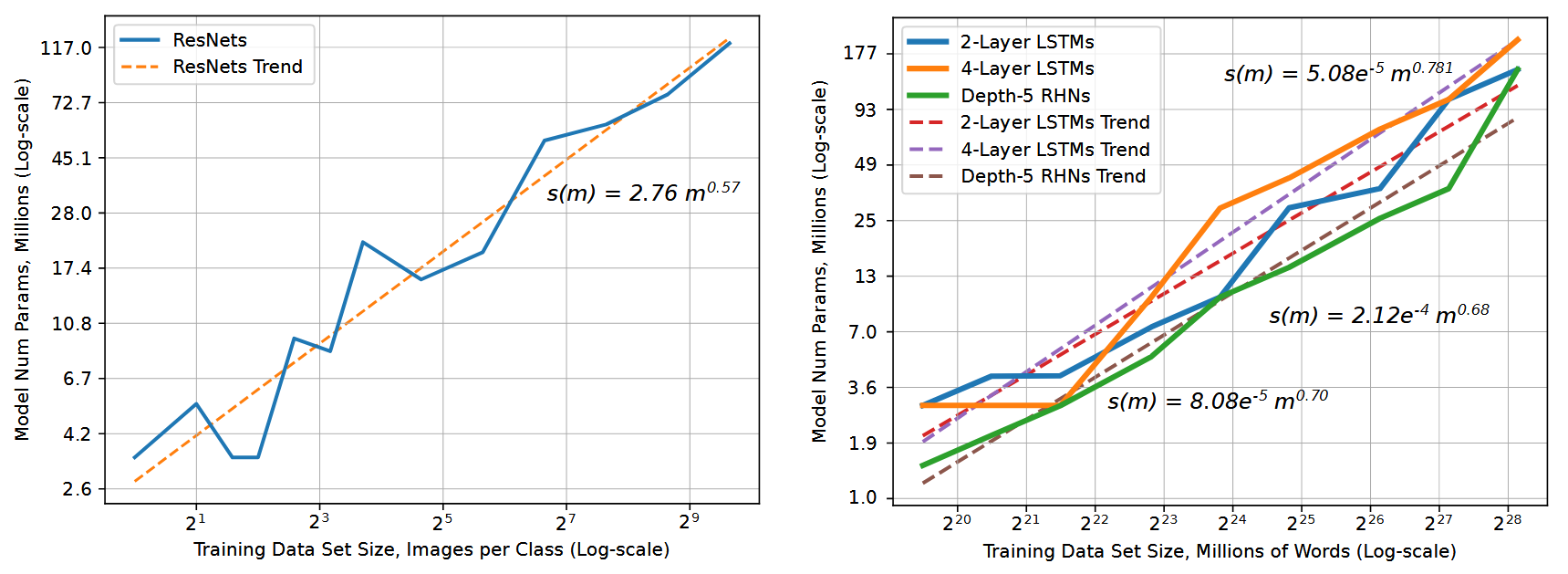
Trend lines for image classification (left) and language modeling (right) from (Hestness et al, 2017)
Inverting this suggests dataset size should grow superlinearly with model size - a 10x larger image classification model should use \(10^{1/0.573} = 55.6\)x times as much data! That’s awful news!
But, the (Kaplan and Candlish, 2020) paper suggests the inverse relationship - that dataset size should grow sublinearly with model size. They only examine language modeling, but state in Section 6.3 that
To keep overfitting under control, the results of Section 4 imply we should scale the dataset size as \(D \propto N^{0.74}\), [where \(D\) is dataset size and \(N\) is model size].
This is strange when compared to the Hestness result of \(D \propto N^{1/0.72}\) . Should the dataset grow faster or slower than the model?
The difference between the two numbers happens because the Kaplan result is derived assuming a fixed computational budget. One of the key results they found was that it was more efficient to train a very large model for a short amount of time, rather than train a smaller model to convergence. Meanwhile, as far as I could tell, the Hestness results always use models trained to convergence.
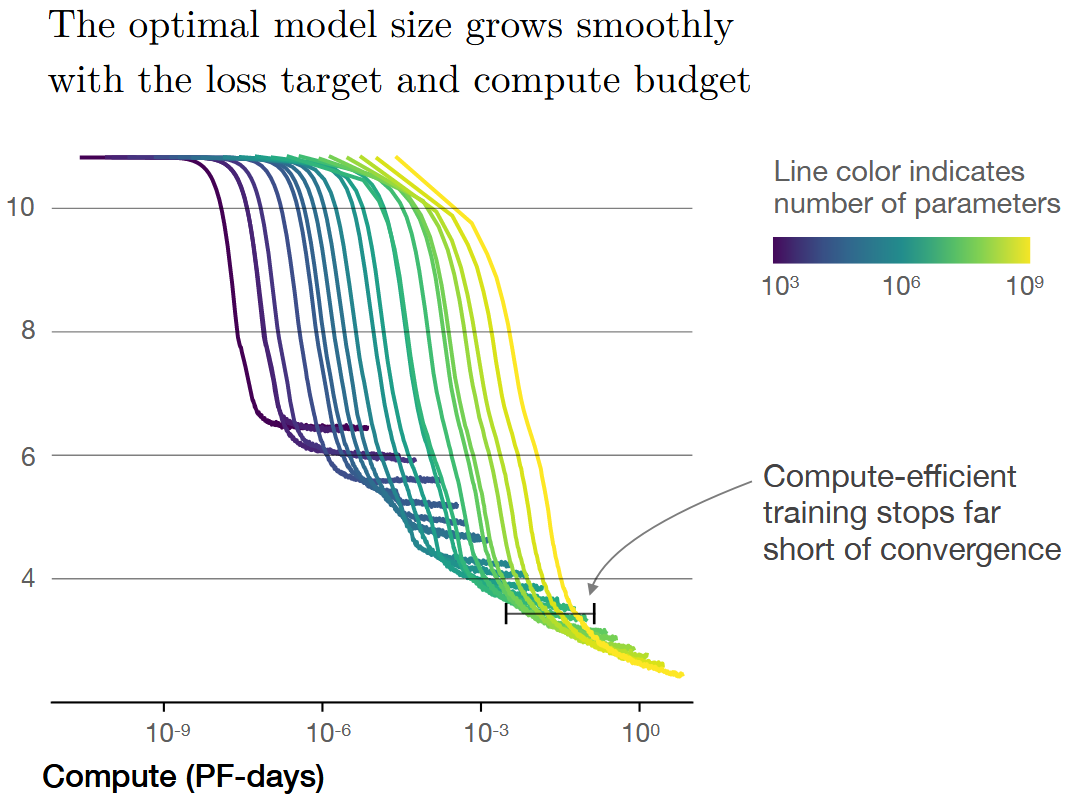
Figure 2 of (Kaplan and Candlish, 2020)
That was a bit of a digression, but after plugging the numbers in, we get that every 10x increase in model size should require between a 4x and 50x increase in dataset size. Let’s assume the 4x side to be generous. A 4x factor for label needs is definitely way better than a 10x factor, but it’s still a lot.
Enter unsupervised learning. These methods are getting better, and what “label” means is shifting towards something easier to obtain. GPT-3 is trained on a bunch of web crawling data, and although some input processing was required, it didn’t need a human to verify every sentence of text before it went into model training. At sufficient scale, it’s looking like it’s okay for your labels to be noisy and your data to be messy.
There’s a lot of potential here. If you have \(N\) unsupervised examples, then yes, \(N\) labeled examples will be better, but remember that labels take effort. The size of your labeled dataset is limited by the supervision you can afford, and you can get much more unlabeled data for the same amount of effort.
A lot of Big Data hype was driven by plots showing data was getting created faster than Moore’s Law. Much of the hype fizzled out because uninformed executives didn’t understand that having data is not the same as having useful data for machine learning. The true amount of usable data was much smaller. The research community had a big laugh, but the joke will be on us if unsupervised learning gets better and even junk data becomes marginally useful.
Is unsupervised learning already good enough? Definitely not. 100% not. It is closer than I expected it to be. I expect to see more papers use data sources that aren’t relevant to their target task, and more “ImageNet moments” where applications are built by standing on the shoulders of someone else’s GPU time.
GPT-3 Results are Qualitatively Better than I Expected
I had already updated my timeline estimates before people started toying with GPT-3, but GPT-3 was what motivated me to write this blog post explaining why.
What we’re seeing with GPT-3 is that language is an incredibly flexible input space. People have known this for a while. I know an NLP professor who said language understanding is an AI-Complete task, because a hypothetical machine that perfectly understands and replies to all questions might as well be the same as a person. People have also argued that compression is a proxy for intelligence. As argued on the Hutter Prize website, to compress data, you must recognize patterns in that data, and if you view pattern recognition as a key component of intelligence, then better compressors should be more intelligent.
To clarify: these are nowhere near universal NLP opinions! There’s lively debate over what language understanding even means. I mention them because these opinions are held by serious people, and the GPT-3 results support them.
GPT-3 is many things, but its core is a system that uses lots of training time to compress a very large corpus of text into a smaller set of Transformer weights. The end result demonstrates a surprisingly wide breadth of knowledge, that can be narrowed into many different tasks, as long as you can turn that task into a prompt of text to seed the model’s output. It has flaws, but the breadth of tech demos is kind of absurd. It’s also remarkable that most of this behavior is emergent from getting good at predicting the next token of text.
This success is a concrete example of the previous section (better unsupervised learning), and it’s a sign of the first section (better tooling). Although there’s a lot of fun stuff in story generation, I’m most interested in the code generation demonstrations. They look like early signs of a “Do What I Mean” programming interface.
This is mind blowing.
— Sharif Shameem (@sharifshameem) July 13, 2020
With GPT-3, I built a layout generator where you just describe any layout you want, and it generates the JSX code for you.
W H A T pic.twitter.com/w8JkrZO4lkIf the existing tech demos could be made 5x better, I wouldn’t be surprised if they turned into critical productivity boosters for nuts-and-bolts programming. Systems design, code verification, and debugging will likely stick to humans for now, but a lot of programming is just coloring inside the lines. Even low levels of capability could be a game changer, in the same way as pre-2000 search engines. AltaVista was the 11th most visited website in 1998, and it’s certainly worse than what Google/Bing/DuckDuckGo can do now.
One specific way I could see code generation being useful is for ML for ML efforts, like neural architecture search and black-box hyperparameter optimization. One of the common arguments around AGI is intelligence explosion, and that class of black-box methods has been viewed as a potential intelligence explosion mechanism. However, they’ve long had a key limitation: even if you assume infinite compute, someone has to implement the code that provides a clean API from experiment parameters to final performance. The explorable search space is fundamentally limited by what dimensions of the search space humans think of. If you don’t envision part of the search space, machine learning can’t explore it.
Domain randomization in robot learning has the same problem. This was my main criticism of the OpenAI Rubik’s Cube result. The paper read like a year long discovery of the Rubik’s Cube domain randomization search space, rather than any generalizable robot learning lesson. The end result is based on a model learning to generalize from lots of random simulations, but that model only got there because of the human effort spent determining which randomizations were worth implementing.
Now imagine that whenever you discovered a new unknown unknown in your simulator, you could very quickly implement the code changes that add it to your domain randomization search space. Well, those methods sure look more promising!
There are certainly problems with GPT-3. It has a fixed attention window. It doesn’t have a way to learn anything it hasn’t already learned from trying to predict the next character of text. Determining what it does know requires learning how to prompt GPT-3 to give the outputs you want, and not all simple prompts work. Finally, it has no notion of intent or agency. It’s a next-word predictor. That’s all it is, and I’d guess that trying to change its training loss to add intent or agency would be much, much more difficult than it sounds. (And it already sounds quite difficult to me! Never underestimate the inertia of a working ML research project.)
But, again, this reminds me a lot of early search engines. As a kid, I was taught ways to structure my search queries to make good results appear more often. Avoid short words, place important key words first, don’t enter full sentences. We dealt with it because the gains were worth it. GPT-3 could be similar.
I don’t know where this leads, but there’s something here.
I Now Expect Compute to Play a Larger Role, and See Room for Models to Grow
For reasons I don’t want to get into in this post, I don’t like arguments where people make up a compute estimate of the human brain, take a Moore’s Law curve, extrapolate the two out, and declare that AGI will happen when the two lines intersect. I believe they oversimplify the discussion.
However, it’s undeniable that compute plays a role in ML progress. But how much are AI capabilities driven by better hardware letting us scale existing models, and how much is driven by new ML ideas? This is a complicated question, especially because the two are not independent. New ideas enable better usage of hardware, and more hardware lets you try more ideas. My 2015 guess to the horrid simplification was that 50% of AGI progress would come from compute, and 50% would come from better algorithms. There were several things missing between 2015 models, and something that put the “general” in artificial general intelligence. I was not convinced more compute would fix that.
Since then, there have been many successes powered by scaling up models, and I now think the balance is more like 65% compute, 35% algorithms. I suspect that many human-like learning behaviors could just be emergent properties of larger models. I also suspect that many things humans view as “intelligent” or “intentional” are neither. We just want to think we’re intelligent and intentional. We’re not, and the bar ML models need to cross is not as high as we think.
If compute plays a larger role, that speeds up timelines. ML ideas are bottlenecked by the size and growth of the ML community, whereas faster hardware is powered by worldwide consumer demand for hardware. The latter is a much stronger force.
Let’s go back to GPT-3 for a moment. GPT-3 is not the largest Transformer you could build, and there are reasons to build a larger one. If the performance of large Transformers scaled for 2 orders of magnitude (1.5B params for GPT-2, 175B params for GPT-3), then it wouldn’t be too weird if they scaled for another 2 orders of magnitude. Of course, it might not. The (Kaplan et al, 2020) scaling laws are supposed to start contradicting each other starting around \(10^{12}\) parameters. which is less than 1 order of magnitude away from GPT-3. That doesn’t mean the model will stop improving though. It just means it’ll improve at a different rate. I don’t see a good argument why we should be confident a 100x model would not be qualitatively different.
This is especially true if you move towards multi-modal learning. Focusing on GPT-3’s text generation is missing the main plot thread. If you believe the rumors, OpenAI has been working towards incorporating audio and visual data into their large models. So far, their research output is consistent with that. MuseNet was a generative model for audio, based on large Transformers. The recent Image GPT was a generative model for images, also based on large transformers.
Was MuseNet state-of-the-art at audio synthesis when it came out? No. Is Image GPT state-of-the-art for image generation? Also no. Model architectures designed specifically for audio and image generation do better than both MuseNet and Image GPT. Focusing on that is missing the point OpenAI is making: a large enough Transformer is not state-of-the-art, but it does well enough on these very different data formats. There’s better things than MuseNet, but it’s still good enough to power some silly yet maybe useful audio completions.
If you’ve got proof that a large Transformer can handle audio, image, and text in isolation, why not try doing so on all three simultaneously? Presumably this multi-modal learning will be easier if all the modalities go through a similar neural net architecture, and their research implies Transformers are good-enough job to be that architecture.
It helps that OpenAI can leverage any intuition they already have about very large Transformers. Once you add in other data streams, there should definitely be enough data to train much larger unsupervised models. Sure, you could use just text, but you could also use all that web text and all the videos and all the audio. There shouldn’t be a trade-off, as long as you can scale large enough.
Are large Transformers the last model architecture we’ll use? No, probably not, some of their current weaknesses seem hard to address. But I do see room for them to do more than they’ve done so far. Model architectures are only going to get better, so the capabilities of scaling up current models must be a lower bound on what could be possible 10 or 20 years from now, with scaled up versions of stronger model architectures. What’s possible right now is already interesting and slightly worrying.
The Big Picture
In “You and Your Research”, Richard Hamming has a famous piece of advice: “what are the important problems in your field, and why aren’t you working on them?” Surely AGI is one of the most important problems for machine learning.
So, for machine learning, the natural version of this question is, “what problems need to be solved to get to artificial general intelligence?” What waypoints do you expect the field to hit on the road to get there, and how much uncertainty is there about the path between those waypoints?
I feel like more of those waypoints are coming into focus. If you asked 2015-me how we’d build AGI, I’d tell you I have no earthly idea. I didn’t feel like we had meaningful in-roads on any of the challenges I’d associate with human-level intelligence. If you ask 2020-me how we’d build AGI, I still see a lot of gaps, but I have some idea how it could happen, assuming you get lucky. That’s been the biggest shift for me.
There have always been disagreements over what large-scale statisical ML means for AI. The deep learning detractors can’t deny large statisical ML models have been very useful, but deep learning advocates can’t deny they’ve been very expensive. There’s a grand tradition of pointing out how much compute goes into state-of-the-art models. See this image that made the rounds on Twitter during the Lee Se-dol match:

(By @samim)
Arguments like this are good at driving discussion to places models fall short compared to humans, and poking at ways our existing models may be fundamentally flawed, but I feel these arguments are too human-centered. Our understanding of how humans learn is still incomplete, but we still took over the planet. Similarly, we don’t need to have fine-grained agreement on what “understanding” or “knowledge” means for AI systems to have far-reaching impacts on the world. We also don’t have to build AI systems that learn like humans do. If they’re capable of doing most human-level tasks, economics is going to do the rest, whether or not those systems are made in our own image.
Trying Hard To Say No
The AGI debate is always a bit of a mess, because people have wildly divergent beliefs over what matters. One useful exercise is to assume AGI is possible in the short term, determine what could be true in that hypothetical future, then evaluate whether it sounds reasonable.
This is crucially very different from coming up with reasons why AGI can’t happen, because there are tons of arguments why it can’t happen. There are also tons of arguments why it can happen. This exercise is about putting more effort into the latter, and seeing how hard it is to say “no” to all of them. This helps you focus on the arguments that are actually important.
Let me take a shot at it. If AGI is possible soon, how might that happen? Well, it would require not needing many more new ideas. It would likely be based on scaling existing models, because I don’t think there’s much time for the field to do a full-scale paradigm shift. And, it’s going to need lots of funding, because it needs to be based on scaling, and scaling needs funding.
Perhaps someone develops an app or tool, using a model of GPT-3’s size or larger, that’s a huge productivity multiplier. Imagine the first computers, Lotus Notes, or Microsoft Excel taking over the business world. Remember, tools drive progress! If you code 2x faster, that’s probably 1.5x as much research output. Shift up or down depending on how often you’re bottlenecked by implementation.
If that productivity boost is valuable enough to make the economics work out, and you can earn net profit once you account for inference and training costs, then you’re in business - literally. Big businesses pay for your tool. Paying customers drives more funding and investment, which pays for more hardware, which enables even larger training runs. In cloud computing, you buy excess hardware to anticipate spikes in consumer demand, then sell access to the extra hardware to earn money. In this scenario, you buy excess hardware to anticipate spikes in consumer inference needs, then give excess compute capacity to research to see what they come up with.
This mechanism is already playing out. You might recognize the chip below.

It’s a picture of the first TPU, and as explained in a Google blog post,
Although Google considered building an Application-Specific Integrated Circuit (ASIC) for neural networks as early as 2006, the situation became urgent in 2013. That’s when we realized that the fast-growing computational demands of neural networks could require us to double the number of data centers we operate.
Google needed to run more neural nets in production. This drove more hardware investment. A few years later, and we’re now on TPUv3, with rumors that Facebook is hiring hardware people to build custom silicon for AR technology. So the story for hardware demand seems not just plausible, but likely to be true. If you can scale to do something impractically, that sparks research and demand into making it practical.
On top of this, let’s assume cross-modality learning turns out to be easier than expected at scale. Similar emergent properties as GPT-3 show up. Object tracking and intuitive physics turn out to be naturally occurring phenomena that are learnable just from images, without direct environment interaction or embodiment. With more tweaks, even larger models, and even more data, you end up with a rich feature space for images, text, and audio. It quickly becomes unthinkable to train anything from scratch. Why would you?
Much of the prior work in several fields gets obsoleted, going the way of SIFT features for vision, parse trees for machine translation, and phoneme decoding steps for speech recognition. Deep learning has already killed these methods. People who don’t know any of those techniques are working on neural nets that achieve state-of-the-art results in all three domains. That’s faintly sad, because some of the obsolete ideas are really cool decompositions of how we understand language and speech, but it is what it is.
As models grow larger, and continue to demonstrate improved performance, research coalesces around a small pool of methods that have been shown to scale with compute. Again, that happened and is still happening with deep learning. When lots of fields use the same set of techniques, you get more knowledge sharing, and that drives better research. CNNs have heavy priors towards considering nearby values. They were first useful for image recognition, but now have implications for genomics (Nature Genetics, 2019), as well as music generation (van den Oord et al, 2016). Transformers are a sequence model that were first used for language modeling. They were later applied to video understanding (Sun et al, 2019). This trend is likely to continue. Machine learning has hit a point where describing something as “deep learning” is practically meaningless, since multilayer perceptions have integrated with enough of the field that you’re no longer specifying anything. Maybe five years from now, we’ll have a new buzzword that takes deep learning’s place.
If this model is good at language, speech, and visual data, what sensor inputs do humans have that this doesn’t? It’s just the sensors tied to physical embodiment, like taste and touch. Can we claim intelligence is bottlenecked on those stimuli? Sure, but I don’t think it is. You arguably only need text to pretend to be human.
A lot has to go right in this scenario above. Multi-modal learning has to work. Behaviors need to continue to emerge out of scaling, because your researcher time is mostly going into ideas that help you scale, rather than inductive priors. Hardware efficiency has to match pace, which includes clean energy generation and fixing your ever-increasing hardware fleet. Overall, the number of things that have to go right makes me think it’s unlikely, but still a possibility worth taking seriously.
The most likely problem I see with my story is that unsupervised learning could be way harder for anything outside of language. Remember, in 2015, unsupervised learning gave us word vectors for language, and nothing great for images. One reasonable hypothesis is that the compositional properties of language make it well suited to unsupervised learning, in a way that isn’t true for other input modalities. If that’s true, I could be overestimating research by paying too much attention to the successes.
It’s for those reasons that I’m only adjusting my estimates by a few years. I don’t think GPT-3, by itself, is a reason to radically adjust what I believe to be possible. I think transfer learning being harder than anticipated is also a damper on things. But on net, I’ve mostly seen reasons to speed up my estimates, rather than slow them down.
Thanks to all the people who gave feedback on earlier drafts, including: Michael Andregg, James Bradbury, Ethan Caballero, Ajeya Cotra, William Fedus, Nolan Kent, David Krueger, Simon Ramstedt, and Alex Ray.