Posts
-
The 5 Year Update on Skipping Grad School (and Whether I'd Recommend It)
CommentsIn 2015, I was in my last year of undergrad and had a lot of angst about whether I should apply to PhD programs. I ended up not applying, writing a 6000 word blog post explaining why. The short version is: lots of imposter syndrome, disillusionment about whether I could handle the marathon of research, wavering faith in doing research at all, and an eventual decision that if I wasn’t sure about research, I couldn’t turn down the money and steady work I could get from industry.
That post wasn’t really meant to be educational. It was more an expression of the feelings I had, written for myself rather than anyone else. But it resonated with a few people, and I’m happy it did.
After that, I interviewed around, got an AI residency offer from Google Research, and did that for a year. I then stayed there full-time and now work on the Robotics team. I primarily work on applying imitation learning and reinforcement learning to robot manipulation problems.
I don’t have regrets about deciding to skip a PhD. Given what I knew about myself at the time, it was the right choice. But it’s been 5 years since then, and 5-6 years is about the length of a computer science PhD. There’s a nice parallel there, so I figured I’d write an update on how things have gone. In particular, I wanted to take a step back and evaluate how my life’s differed by starting in industry instead of a PhD program.
Disclaimers
- This is based on what I believe grad school is like, but my model could be incorrect.
- This is specific to machine learning PhDs. ML is in a very unique position that doesn’t generalize to other fields. Extrapolate with caution.
- I was pretty lucky to get an industry lab research offer. 2015-2016 was a crazy year for deep learning. AlphaGo had just won against Lee Sedol, OpenAI was founded, and companies were going crazy on hiring. Google had never done an AI residency before, so they didn’t fully know how it would go and it was less competitive to get in. Things would be different if I had taken a generic SWE job offer instead.
- Working on this post has taught me that everyone’s academic and industry lab experience is wildly different. Like, completely contradictory along every axis. My experience won’t be typical because no one’s experience is typical. The space of outcomes is too big. Even if your outcome doesn’t line up with mine, I hope this post conveys the possibilities.
- Conveying the possibilities made this post long. Sorry. I tried to make it shorter and I failed.
Research Confidence
One reason I didn’t apply to PhD programs was that I wasn’t sure I was in the same weight class of research ability as my peers. My undergrad research was never good enough to publish. Meetings felt like I was desperately trying not to drown in new topics. It was all a bit much. When I talked to friends in my year, they reassured me and said I’d do well in grad school. I disagreed.
In hindsight…I’m not sure if they were right, but they weren’t wrong. I’m more calibrated on my abilities now and think I definitely could have kept up, albeit not superstar tier.
I think the reason I underestimated my ability is that getting through the first few walls is the hardest. It’s surprising how much easier research got with experience. It’s still hard, but I have a better handle on how projects organize themselves and how to follow them through. (As well as how they can fall apart, which is an unfortunate lesson that everyone learns eventually.)
When I imagine the world where I did a PhD instead, I don’t think my research self-confidence would be that different. It was at a near bottom in undergrad, and regardless of where I went, it would have improved. I was getting better, I just didn’t realize it yet.
Research Interest
I discovered over the past 5 years that I love being a spectator of research, but the burden of being a continual producer of new research is just too great for me.
This is a quote from the Ph.D. Grind, and 2015-me agreed with this as-is. Learning about new research is awesome, in the same way that taking classes is awesome. Paper authors and teachers think carefully about how to deliver knowledge as quickly and clearly as possible to your brain. If the paper’s confusing, or they taught the course poorly, they’ve failed.
Reality is unfortunately not set up this way, and since research is about understanding reality, it’s much more time consuming and draining to learn something new. In exchange, the insights can be much more satisfying.
I would now amend the quote above to:
The burden of being a continual producer of new research is too great without careful management.
I got much better at work-life balance once I left university. This is definitely at the cost of my productivity. I got more done in school, but it wasn’t sustainable for my mental health. There’s a sweet spot where I feel I can do research without burning out, and in that sweet spot research is great. In short, I could be doing more, and I choose not to because I have other priorities and life is more fun that way.
It’s intertwined with the Research Confidence section, but another reason I was disinterested in research was that failing to make progress in undergrad made me very pessimistic I would do anything meaningful in research.
When I don’t do research for a while, I miss the feeling that I’m in touch with the cutting-edge and playing a hand in shaping the future.
[…]
When I do research for longer, I realize how much of a novice I am and how unlikely it is any of my contributions will be important.
I’ve since been part of some noteworthy papers like QT-Opt and GraspGAN, and that’s helped me believe in myself. When I got my first email asking for help reproducing a paper, I was pretty excited. They wouldn’t be asking unless they were paying attention! Seeing concrete threads of influence between my work and changes in the research landscape makes it easier to keep going.
I’m guessing my interest is higher than it would have been if I went to grad school. The papers I was on that made big splashes were from large projects with 10+ authors. Those don’t tend to come out of academic ML labs. In a PhD setting, I likely would have worked on more papers that each had a smaller impact, and although that might add up to a large total impact, it would have been less fulfilling because I wouldn’t notice it as easily.
Research Reputation
By reputation, I mean: how often are you asked to peer review for a conference or journal? Are you asked to be an area chair? If you went to give a talk somewhere, how much of the interest would be driven by your name, rather than the subject of your talk? People usually call this “status”. I’m using reputation because it’s alliterative.
I find it all kinda grimey to think about, but it does matter, especially for research. Reputation matters because it’s the way you stay employed. If you want to keep doing research, you need to both be good at research, and be known as someone who’s good at research. Right now, the demand for ML / AI talent is still way bigger than the supply of PhDs, so companies will take anyone they think can do the work. This won’t last forever, and credentials are the first filter that’ll appear when it stops. Ask people in electrical engineering. I’ve heard EE companies used to hire straight out of undergrad, and now it’s hard to get anywhere without at least a master’s.
Machine learning might also be in a bubble. I’m not going to claim anything about whether that’s true, but if it is, then the climate could change very quickly. Therefore, I’m reluctant to rely too much on the past when planning my future. To quote John Langford at the Real World Reinforcement Learning workshop, “if there is one piece of machine learning which is going to crash, it’s going to be reinforcement learning”. Unfortunate for me, given what problems I find interesting!
There’s two kinds of research reputation: endorsement, and influence through publications. Endorsements are easier to get. You can give a good talk, make an impression on someone when you mingle at a conference, or contribute useful ideas during a research brainstorm within your lab. But these endorsements aren’t permanent. It’s tied to the people you work with and the institution you work at. People change jobs, fortunes turn, and if everyone who knows you leaves, then you’re left with nothing. Word of mouth has a short reach.
Endorsements can be very useful, if you have them from the right people. If a professor is willing to vouch for you, that means a lot, because they’ve seen many prospective students, are calibrated on what a good researcher looks like, and it’s common knowledge that they’re calibrated. That means they can make pretty strong cases in your favor if they think you deserve them. It’s why letters of recommendation are important for PhD applications. A recommendation from a senior industry researcher can be good for similar reasons.
Outside of these cases, most recommendations mean very little. Being known as “the person who knows X” is nice, but this alone is not enough, because lots of people “know a guy”. The recommendation only means something if the person hiring you knows how calibrated the recommender is, and only a small number of people have seen enough researchers to be calibrated. For a PhD program, a letter from a software internship saying you’re the best intern they’ve ever had means little. A letter from a professor that says “they’re a genius” can be enough by itself. It was for John Nash.

If you’re confident you want to keep doing research for the rest of your life, you need concrete, visible proof of your skills. For research, that means publishing. Using h-index as a filter isn’t perfect, and everyone knows it isn’t perfect, but it’s used all the time anyways. Getting a higher h-index requires publishing, and getting a PhD is a surefire way to force you to publish. Your papers may not be the best, but they’ll be out there, and once the papers are out there, no one can take them away from you.
When I got the AI residency offer, I treated it as a 1 year trial run of whether I wanted to keep doing research. After that year, I decided that yeah, research was cool, and I liked Google, so I went for a riskier plan: get enough publications out of my industry research to create a PhD-equivalent body of work. If I got there, no one would care I didn’t formally have a PhD. This wouldn’t qualify me for any faculty positions, but I was okay with that.
That plan hasn’t gone perfectly. I’ve been on some papers, but not that many. I’ve reviewed for conferences, but I get the feeling that the ML reviewer pool is so starved that organizers are continually scrambling for any reviewer they can get, so it doesn’t mean much. Working on big projects is good for driving the field, but the papers that come out of them are often treated as “the Apple paper” or “the Uber paper”, rather than “the paper by X & Y”.
However, I have written for this blog more seriously, and somehow my blog is now the biggest reputation boost I have. It’s not the same as a paper, but it’s another way for me to put out work that demonstrates how I think through research problems. My post about deep RL is still my most viewed post, and I’d like to think it helps get my foot in the door. In the end, what matters is influence on the research community, and well-cited publications aren’t the only way to achieve that.
If I had done a PhD, my reputation would probably have been equal. I would have written for this blog either way, and evidently it’s the main reason people know who I am. My takeaway is that more people should start blogs! I don’t know why they don’t. Maybe they’re too busy writing papers or something 😛. Joke’s on them, I get to use emojis and they don’t.
Research Ability
I realize I just spent a section saying people should publish, but a PhD isn’t about getting a lot of publications. It’s about learning how to form and attack a long term research thesis, with publications as a natural byproduct. To borrow fighting game advice, practice isn’t about winning, it’s about learning something, and that will make you win more in the long run.
This counterfactual is the hardest for me to judge, because advising in industry vs academia is so different.
A good advisor will help you figure out what problem you should try tackling next, explain why that decision makes sense, and repeat this process until you can do it yourself. This is what people mean when they say you’ll develop research taste. If a professor doesn’t do this, then they aren’t a good advisor, and professors want to be good advisors. It’s how they get their reputation.
No one is required to give you this mentorship in an industry lab. The more top-down the lab, the truer this is. Industry labs tend to organize themselves around a grand vision, like “we can build a quantum computer”, or “all AI needs is good scaling”, and although these are very broad theses, more of the research direction is already sketched out by the team leads. That leaves less research direction for you to figure out.
So, you might not have a mentor in industry, but in a PhD program, it’s possible your advisor doesn’t mentor you either! Based on talking to research scientists at Brain, a surprising number have said their professors were too busy to help them much, compared to their labmates. And if you’re stuck figuring out research with your labmates, then your labmates in an industry lab will include people who’ve already navigated a PhD. Fewer people are obligated to give you mentorship, but more people could give you mentorship.
If you figure out whether your boss / advisor will be good before signing anything, that solves everything, but doing so is easier said than done. Everyone I know who’s left Google did so because they didn’t get along with their manager, and to me it feels like a cosmic roll of the dice whether that happens or not. Getting a good professor is a similar roll with higher stakes. A PhD advisor has more power over your life than a manager does.
I think the grad student \(\rightarrow\) advisor relationship can be felt out more if you make good use of visit days, and talk to current PhD students to get their take on how things are going. So the stakes are higher, but you have slightly better odds. (You might be able to get the same level of access for industry if you’re good at pestering recruiters.)
I got lucky and had mentors in industry who encouraged me to consider where the field was going. I think on expectation, if I was in a PhD program, my research ability would be similar, but there would be high variance on how it could’ve played out.
Money and Freedom
Money isn’t my first priority, but I’m not going to ignore it.
If you only care about the money, doing an ML PhD just doesn’t make sense. Unless you discover something revolutionary that starts a bidding war, 5-6 years of ML engineer / data scientist salary + compounding returns from investing in index funds will get you more than most post-PhD jobs.
You don’t do a PhD for the money, but money tends to correlate with freedom, which is one reason people do a PhD. On that front, friends in academia have told me very different stories. Some told me they felt they could do anything, while others told me about labmates who had to teach courses they didn’t want to teach, or do research separate from their thesis to pay the bills.
The common thread in those stories was that PhD students should get as much unconditional funding as possible. Students in good situations had NSF fellowships and enough unconditional grant money from their advisor to do whatever they wanted. Students in bad situations had more of their funding come from grants with narrow proposals, requiring them to do work that matched the proposal rather than the research they were most interested in. Good advisors try to shield their grad students from these situations, but not all professors get unconditional grants.
In contrast, ML industry labs have one source of funding (the company), and it’ll pay enough that you won’t need to think about side hustles. You will probably have fewer responsibilities outside of research, but you won’t have radical freedom. I remember a dinner at NeurIPS, where a professor said that sometimes the best thing for a grad student is to have them go read textbooks for 9 months to learn all the math foundation they need for their research interests. This is an example of something you can do in academia that you can’t really do in industry.
It’s also possible that your company will lay-off your research lab without much recourse. To give recent examples, in 2014 Microsoft closed their entire Silicon Valley research lab. In 2020, UberAI downsized and Alphabet shut down Loon.
The freedom in an industry lab isn’t obviously worse than a PhD. A person with stable funding in an industry lab likely has more research freedom and time than a PhD student with unstable funding. On average though, I’d say that PhD programs have the edge.
Research Direction
I started undergrad planning to double major in math and CS, and like theoretical CS in general. If I had gone to a PhD program, there’s a real chance I would have ended up in learning theory instead of robot learning.
Many industry labs have good theory people, but on average an industry lab will be more experimental. The argument is, industry labs have access to bigger computing clusters, therefore it’s more scientifically interesting if industry labs work on projects that exploit the comparative advantage of more compute, because this produces research of a different flavor. (I would link a post that argues this with examples, but it was hosted on Google+.)
I find this argument reasonable, but it puts pressure on theoretical work. Why should the industry lab pay you for this work, when you aren’t using any of industry’s resources and could do identical work in academia? All you need is your brain.
From what I’ve seen, theory work from industry labs is usually a hybrid of new theory, along with experiments showing that it works. Otherwise, pure theory work is rare, unless there is a high certainty path between that theory and something revenue generating. In those scenarios, it’s important for the company to hire theory people to stay on the cutting edge.
Speaking more generally, the subfield you pick affects the number of job openings you’ll find in industry. If you can’t be happy unless you’re in a niche subfield that industry doesn’t value yet, academia might be your only option.
Personally, my research interests aren’t perfectly aligned with my day-to-day work, but it’s aligned enough that I’m willing to bend in favor of the trade-offs it comes with. The good part of robot learning is that getting things to work in the real world makes you directly hit hard, interesting problems that have to be solved for ML research to be useful. The bad part is that you have to deal with the real world.
I’d probably have done more theory if I had gone to a PhD program, but it’s hard to say whether that would have continued long-term, or if it would be a summer fling before going back to more practical work. Most likely, I’d be working on the same problems I am now, with a different perspective on how to attack them.
Day-to-Day Work
When I talk to people considering skipping a PhD, a common worry they have is that if they join an industry research lab, they’ll be expected to do more software engineering work and less research.
The first piece of advice I’d give is that even if you get a PhD, you’ll probably do grunt SWE work. Research tools will always feel deficient, because your research will uncover new problems, and it’s unlikely the perfect tool exists for a problem no one but you has seen before. These tools will therefore almost always have sharp edges that cut you a few times. Doing a PhD will not save you - you will be debugging garbage your entire life.

(from xkcd)
The second piece of advice is that I think getting boxed into non-research work is a real, valid concern. Unfortunately, every industry lab is different, so I can’t recommend much besides asking friends who work in those labs, if you know any. In my experience, if you like a project, you won’t mind the grunt work as much, so I’d optimize for that first.
Coming in through the AI residency program meant I did research from day 1, and by the end of that year I had convinced enough people to get research roles in future projects. However, I’ve also done a lot of SWE work for that research, because those projects often used large distributed systems that were tricky to understand, build, and debug. I think my day-to-day work would’ve been similar in academia, I’d just be debugging different sorts of distributed systems. Such is the fate of using deep learning.
Non-Research Skills Learned
There are many skills outside of direct research that will help you with your research.
For example, software engineering. Industry will teach you how to write better code. If you don’t do code reviews or write unit tests, your code isn’t getting checked into the repository. Even if no one teaches you good code habits, you’re embedded in a company with non-researcher SWEs and will naturally acquire good habits through osmosis.
Better coding will make you a better researcher. Most PhD programs don’t teach software engineering or best practices. I understand why, you’re supposed to learn it in undergrad, but…okay, I’m going to rant for a bit. Pardon the side track.
Research code is, as a rule, not very good. I used to think this was fine and even desirable. I no longer think this is true.
There is this longstanding idea that research code is bad because researchers don’t know if their ideas will work. If the idea doesn’t work out, then time spent cleaning up the implementation is wasted, compared to spending time on new ideas. I 100% agree with this. All the very good researchers I know try lots of ideas. (Pure volume isn’t enough, they try their ideas with purpose, but they try a lot of ideas with purpose.)
My issue is that people take this too far. Look, writing beautiful code takes time. Writing legible code does not. Real variable names and useful comments reduce the complexity of the mental model of your code, which makes it easier to catch bugs. This is especially important in machine learning, since bugs don’t surface as compiler errors, they surface as mysterious 20% drops in performance in a pipeline that mostly works.

(Learning curve of OpenAI Five, before and after fixing a bug where the agent was heavily penalized for reaching level 25. Learns anyways because machine learning finds a way.)
Since performance drops could come from bugs, or bad data, or a bad model, you want to make sure bugs are easy to quickly prove or disprove, since they can be fixed the fastest. Doing some code cleanup will save time in the long run, even if you’re the only one who looks at your research code. Your collaborators will thank you. This is especially true if your “collaborator” is future-you trying to run an experiment for a reviewer rebuttal 2 months after you’ve thought about any of the relevant code.
Now, do you need to go full code review to write good code? No, I don’t think so. Another set of eyes helps, but PhD students have good technical skills and are perfectly capable of reviewing their own code. Just, actually do it. Please.
(end rant)
A PhD program may not teach you coding, but on the flip side, an industry job likely won’t let you teach a course. You may have some chances depending on the company, but you’ll have many more chances in academia. Teaching will also make you a better researcher, because it forces you to clarify ideas until newcomers can understand them, which is the exact skill you need when writing papers. Not to mention it can be rewarding by itself.

A PhD program will also provide more mentorship opportunities. In academia, the totem pole is professor > postdoc > grad student > undergrad or master’s students. Going to a PhD program means you aren’t on the bottom anymore, and you’ll get to mentor undergrads that want to try research. Whereas in industry, if you join out of undergrad, you’re entering at the bottom of the totem pole and will have fewer mentoring opportunities until interns come, which is a seasonal thing. Mentoring helps because it exposes you to a wider variety of thinking, and sometimes solving a research problem just requires the right perspective.
Personally, I believe in all of coding, teaching, and mentorship, but right now I do more coding + teaching, where teaching is defined broadly enough to cover writing blog posts and presenting in reading groups. In a PhD program, it’d likely be weighted towards teaching + mentorship instead, where teaching means TAing a class. I did like my SWE internships in undergrad though, so I could see myself getting into coding and becoming a SWE proselytizer in a PhD program. Who knows?
Social Life
I’m more of an introvert, and didn’t talk to a lot of people growing up. I’m not depressed or unhappy by any means. Through practice, I’ve developed a long, winding maze of entertainment and side projects that keep me busy if I don’t have the energy to catch up with friends. The problem is that the maze is too effective, sometimes it takes a long time to get out, and when I do I usually wish I had exited the maze sooner and socialized more.
Undergrad life shook that maze in a way that working life hasn’t. When everyone lives near campus, everyone goes to campus whenever an event’s happening, and you can serendipitously run into friends in the street, it’s just a lot easier to meet people and hang out.
Those things happen in industry too (there’s a reason water cooler chat is a thing), it just doesn’t happen to the same degree. The demographics are also different. I find it harder to relate when people talk about their kids, or buying a new house.
If you go into industry, you’ll mostly see people on your team. If you go to grad school, you’ll take fewer classes and mostly be spending time in your lab. In both cases you get fewer chances to meet new people than undergrad. I suspect the largest factor for social life is location, rather than industry vs grad school, so it’s hard to say how this would go.
So, Should You Do a PhD?
Section Verdict Research Confidence About equal Research Interest Higher from industry Research Reputation About equal Research Ability About equal, but high variance Money Much better Freedom Slightly worse (compared to top CS program) Research Direction Slightly misaligned, but not by much Day-to-day work Similar Non-research skills Less mentoring, more coding Social Life Very dependent on location, hard to say After totalling this up, I’d say I came out ahead by skipping a PhD. I don’t have any plans to go back to academia. I still can’t say I’ll never go back, but right now I feel I can achieve my goals outside that system. Formally having the degree would be nice, but I’m going to keep trying to get what the degree represents through industry research instead.
Although it worked out for me, I can easily see why someone would go back. A few different weightings on each feature would be enough to change the decision.
The common wisdom is that going from industry to PhD is straightforward after 1 year, and exponentially less likely afterwards. This is definitely true, but it’s not because your research skills decay that quickly. It’s that bandwagon effects are real. You’re going from an environment where many people are considering PhD programs, to one where most people have no plans to go back to school. You need to be a much weirder person to decide to do a PhD once you get paid and settled into a work routine. I’m not that weird of a person. Well, I mean, I am weird. Just not weird in that way.
Your research skills may not decay, but your professor’s memory of those skills might. Letters of recommendation are a big part of PhD applications, so if you’re on the fence, it’s better to apply first and defer the offers you get if you want to keep your options open. That way, if you do want to go back, your professors can always recycle their previous rec letter if they forgot what you did.
One piece of advice my friend gave me is that undergrads should mentally downweight their enthusiasm for grad school. If they’re very excited about grad school, they should only be moderately excited, and if they’re unsure about it, they probably shouldn’t go. I still agree with this, but I probably would have gotten more enthusiastic about research if I had gone to grad school. This is not normal. Even if I think doing a PhD would have worked out for me, I would never recommend using a PhD to figure out your life.
If you can get a full-time offer out of undergrad for a good industry lab, along with a reassurance you’ll get a chance to publish, it’s a compelling offer and I would take it seriously.
Despite all my grad school angst, all the knotted up emotions and trains of thought, time has made it easier to evaluate and feel at ease with the choices I made. So I think the main thing I’d tell myself (or anyone else considering these questions) is that it’s okay to be stressed out, and to take all the time you need. This too shall pass.
Thanks to the many early readers for giving feedback, including: Ethan Caballero, Victoria Dean, Chelsea Finn, Anna Goldie, Shane Gu, Alvin Jin, David Krueger, Bai Li, Maithra Raghu, Rohin Shah, Shaun Singh, Richard Song, Gokul Swamy, Patrick Xia, and Mimee Xu.
-
Reliving Flash Game History
CommentsAs someone “from the Internet”, Flash was my childhood.
No, I’m not sure you understand. Flash was my childhood. I’ve easily spent thousands of hours playing Flash games, and it’s shaped my thoughts on what games can be and what games should be. The death of Flash has been sad in ways that are hard to describe.
If you don’t have much time, Flash Game History is an excellent short article that captures the influence of Flash games on game development. If you have more time, the Flash Games Postmortem from GDC 2017 is an long, worthwhile talk that goes into why Flash became popular, with a deeper look at how games were created, distributed, and monetized.
There isn’t a short version of either of the previous links (and I heavily encourage watching them yourself), but if I had to pick one key point, it’s this: Flash thrived because it ran the same way on any platform in the world. Everyone knew Flash had problems, but they understood them, and out of that we got an incredible free library of creativity and expression.
I’m not sure the Flash era can be reproduced. The Internet was less of a walled garden at the time, and Flash guaranteed a uniform, easily shareable experience. Now the online experience is fundamentally split between desktop, mobile, and native apps, all with slightly different character, and monetization has homogenized around parasitic free-to-play transactions, rather than advertisements on a Flash game portal. It’s not that F2P is new…it’s more that it’s eating more of the world, and I don’t like the games it leads to.
With Flash officially unsupported, the best avenue for playing Flash games is BlueMaxima’s Flashpoint. It’s an archive of several thousand Flash games and animations, and I had a bunch of fun playing through some old memories.
Many Flash games have not aged well. Game design has evolved a lot, and as an adult it’s obvious how much filler many of these games had. Yet they suck me in anyways. This is why I don’t install games on my phone. It’s not that I’m too good for them, it’s that I’m too weak. All the psychological tricks to keep people playing work on me, and that’s not how I want to spend my time.
Let’s just reminisce about the good stuff. After doing a lot of research (read: replaying a ton of games), here are some I recommend.
Super Mario 63

Super Mario 63 is a 2D fangame that mashes up three of the 3D Marios: Super Mario 64, Super Mario Sunshine, and Super Mario Galaxy. On one hand, it shouldn’t be surprising that the game is fun. It’s stealing mechanics and levels from three of the best platformers of all time. On the other hand, there’s still plenty of work required to execute that roadmap properly.
There’s a lot of hidden secrets in the hub area, tied together with a fun movement system. The story is pretty fanfiction-y, but the game is more about the platforming than the story. My one complaint is that Mario is too powerful. Many platforming sections are designed to be beatable without the FLUDD, likely because it’s not guaranteed you have it, but the FLUDD comes with so much water that it’s hard to run out. That gives you an easy get-out-of-jail-free card whenever you mess up a jump. Meanwhile, the spin attack inspired by Galaxy has 0 cooldown, so if you spam the spin attack button you’re practically invincible. Still, in single player games it can be fun to be overpowered, and the overall package is fun to play with plenty of content.
Sonny + Sonny 2

Sonny and Sonny 2 are RPGs where you play as zombies who don’t want to eat people, and don’t know why they became zombies. You travel with two goals: figure out how you got turned into a zombie, and survive.
Part of Sonny’s strength is its high production value. The game has a distinctive art style, voice acting, music, well-done sound effects, and a solid overarching story (that admittedly gets very silly at times). However, I love this game because of the depth of its combat system.
A lot of RPGs have skill trees that are basically variants of “do more damage” or “attack with this element”. Most of the skills are strictly better than other ones, and the progression is about grinding EXP to learn the more powerful ones. Sonny doesn’t do this. Instead, each skill is slightly different. You’ll have a stunning attack, or an attack that applies a damage-over-time status, or a spell that dispels enemy buffs, and so on. There are very few pure damage spells in this game, and it gives the game a puzzle feel, where gameplay is more about finding what skills work together, rather than brute-force leveling. In fact, it’s possible to beat the game on the hardest difficulty without taking any optional fights - doing so is required to unlock the final bonus bosses, and figuring out how to do so really stretches the limits of your available options.
This complexity extends to the enemies as well. Their attacks also apply complicated buffs and debuffs, and the game UI (usually) spells out exactly what they do, so you have all the information needed to decide how to deal with the current battle state. Enemy AI also follows simple patterns that you’re expected to figure out and exploit to beat the game. For example, one enemy alternates between doing 3x more damage, and taking 3x more damage. So strategy in that fight is about figuring out how to survive the first phase, to let you retaliate in the second. The fights can be gimmicky, but I think they’re gimmicky in a good way, they force fights to play out differently.
I will say that once you figure out the best skill combos, it becomes hard to play the game casually. Skills in Sonny are not strictly better than other skills, but there are definitely skills that are way stronger in most scenarios. Additionally, my praise is mostly for Sonny 2. Sonny 1 has some of the same flavor, but the skill tree isn’t as varied as it is in Sonny 2. I think the second game improves on the first on every way, so you may want to start there, but Sonny 1 is a fine game as well.
My main warning is that at times, the game feels complicated for its own sake. Almost every attack has a side effect of some sort, and a bunch of my early playtime was spent just reading skill descriptions to figure out what build I wanted to make. I find that fun, but I know not everyone does. I think the complexity could have been toned down without compromising on depth, but the complexity is why I like this game…so perhaps it’s fine as is.
Mastermind: World Conqueror

It’s been over 10 years since I played this game, and I still feel the same way about it, in a good way. Mastermind: World Conqueror is a real-time strategy game, where you play a villain trying to take over the world. Recruit minions, send them on missions to earn money, then spend money on other missions that advance you through the tech tree. The more missions you do, the more attention you attract from the good guys, and the more money you’ll need to invest into your base defenses to fight them off.
A lot of the features in this game aren’t that cost-effective. I’m still not convinced any of the henchmen are worth hiring, compared to just buying more guys after they die in combat. I also don’t like that you can only plan and execute 1 mission at a time. It really limits the multitasking ceiling, and once you’re in the late game you’re mostly waiting for progress bars to finish. The overall theming is top notch though, and the core gameplay loop of steal cash -> use cash to buy upgrades and plan other missions -> repeat works for me. It’s just plain fun to play the villain.
Epic Battle Fantasy 3 + 4 + 5

Okay. Okay okay okay. First things first: the series has really juvenile humor. Basically the series was started by a horny teenage boy who liked anime, and the humor never evolved past that. And the plot is an excuse plot that revolves around the main characters being idiots.
If you can ignore those issues, then you’ll find a quality JRPG. Epic Battle Fantasy 1 and 2 are pure boss rushes, and they’re fun enough, but from the 3rd entry on you get an overworld, block pushing puzzles, treasure chests, an equipment upgrade system, the whole works.
Epic Battle Fantasy isn’t trying to do anything crazy to the JRPG genre, but I think that’s fine. The one thing it does different is its equipment system. Instead of giving flat stats, all weapons and armors grant percentage based stats. So for example, a weapon could give +30% attack and +15% defense, or +50% attack and -20% defense. Old weapons are never strictly worse, because percentages naturally scale with your stats as you level up. Your equipment choice is therefore more about what passives you want, what playstyle you prefer, and what elemental weaknesses your foes have, rather than pure stats. I appreciate this - it’s nice to not have a ton of old useless items clogging up my inventory, and it leads to a lot of flexibility.
Amorphous+

This game has one button: attack. That’s it. Despite that, it’s a surprisingly deep arcade game. Your goal is to kill Glooples with your giant sword. You attack in a wide arc in front of you, but every attack comes with a long recovery time where you can’t move and are vulnerable to attack. Different Glooples have different attack patterns, Glooples can interact with each other, and you get one life to clear all the enemies. If you die, you start over.
It’s an action game with minimal upgrades. You unlock rewards based on your achievements, but can only equip at most 2, so you reach max power pretty early and the rest of the game is solely about learning attack patterns and getting better at dodging. And if you want to get better, there’s a practice mode where you can spawn all the hard enemies you want.
I recommend treating this game as a roguelike, because, well, it basically is one, and part of the roguelike experience is learning the mechanics on your own. Then, once you’ve seen most of the monsters, you can look up a guide if you’re struggling on something. If you’re aim is 100% completion, a guide is practically mandatory. Many of the achievements require engineering pretty weird scenarios that don’t come up in normal play.
If you do go for 100%, I recommend using the glitch that lets you earn achievements in Practice Mode. I didn’t do this when I first played the game, out of a sense of honor, but this was a mistake. All my honor led to was spending many, many hours waiting for the right rare Gloople to spawn, just so I could get the “kill X copies of (super rare enemy)” achievements. There’s no honor in waiting for the right RNG roll.
Motherload

I almost didn’t include this one…but it’s iconic, and I found it weirdly captivating on a replay, so I’ll give it a shout out.
The mechanics are very simple. Drill down to pick up ore. Fly back to the surface when you run out of gas to refuel. Sell your ore to pay for refueling, and to buy upgrades that let you dig deeper for more valuable ores. Rinse and repeat. Not a lot of depth, but there’s a Zen feeling in figuring out the shortest path to each ore. The key that makes the entire game work is that you can’t drill upwards. Because of this, you can make ore inaccessible if you drill poorly, and that’s just enough thinking to stop it from being totally mindless. It’s a bit like Bejeweled in that sense, although Bejeweled didn’t have an upgrade system or resource management.
My main issue with the game is that dying has an insane penalty. If you die, all drilled holes are reset. So if you die in the late game, get ready to hold down for several minutes to get back to where you were before. This wouldn’t be so bad if gas pockets weren’t a thing. After a certain depth, dirt blocks have a random chance of having explosive gas pockets. You’re warned about them once, but the game doesn’t emphasize how destructive they are. Gas pockets are 100% undetectable, can’t be avoided, and do massive amounts of damage, to the point that they’re a one-hit kill if you don’t have enough HP and defense upgrades. So basically, gas pockets are an invisible stat check, you have no way of knowing how to pass the check ahead of time, and if you fail the stat check then you have to redrill all the way back down.
Once you know how to deal with gas pockets, the game doesn’t have many surprises. The late game ores are so lucrative that it’s pretty easy to reach the end in a practically invincible state.
Elements of Arkandia

This game should not work. The mechanics are poorly explained. Some skill descriptions are incorrect. Art assets get reused a lot - you’ll have multiple shields that look exactly the same, with wildly different stats, which is a problem when deciding what to get rid of. There are massive difficulty spikes. And most importantly, who uses Impact font this much? I’m not even kidding, the font usage in this game is awful and it makes a ton of things harder to read than they should be.
Despite all of those issues, I like this game. It’s a mashup of mechanics from two games: Puzzle Quest, a match-3 RPG, and Recettear: An Item Shop’s Tale, a game about running an item shop. And, well, it’s not as good as either individual game, but there’s a kernel of fun that carries all the weird presentation.
You start the game with a large debt, that accumulates interest every day. To pay off the debt, you need to go on dungeon adventures to find loot. Battles are done through a Bejeweled board. Matching gems of the same color gives mana, gold, treasure, or rage, and forming a group of 4 or 5 gives an extra turn. Mana can be used to cast spells that affect the board or do damage. For example, there’s a spell that changes all gold gems to treasure gems, which you might want to cast if it would form a group of 4 to get an extra turn. Rage can be spent to attack with your weapon, which is usually your main damage source.
Once you find loot, you need to stock it in your shop. You can then spend a day running your shop to sell items. Unlike Recettear, there’s no haggling, but you can pick crests that increase the odds of selling certain items, and depending on market conditions customers may like some items more than other ones.
Everything in Elements of Arkandia revolves around money. You need to balance paying off your debt, upgrading your store, and buying battle upgrades that enable clearing harder dungeons. Then battles themselves are about figuring out what types of mana are easy or hard to achieve, and using that to decide what kind of spells you’re going to aim for. The game can get a bit grindy, so your enjoyment will depend on whether the match-3 combat works for you.
Two bits of advice. One: you can choose to play without debt, but you should play with debt. If you play without debt, you remove all the interesting trade-offs on how to spend your money, making the gameplay really boring. Two: if you want, you can try to min-max every move, since there are no turn timers. I don’t think you should do this. Battles are long enough that trying to min-max every board will just drive you insane. Just aim for an acceptable move and keep going.
Portal: The Flash Version

There’s an interesting story behind this game. The creators of the game watched the trailers for Portal 1, and were SUPER PSYCHED. They were so excited that they implemented Portal’s mechanics in Flash, creating puzzles based on all pre-release content they could find. After fleshing it out more, they got good feedback from friends and family, so they released it publicly 1 day before the official game came out.
The end result is missing Portal’s sharp writing, but the puzzles are uncannily accurate. The mechanics they added themselves also work quite well. The main problem the game has is that sometimes you know exactly what you need to do, but then you mistime the portal shot and have to start all over. The timings are tighter than Portal proper, so adjust your expectations going in. Objects will sometimes get bumped through walls as well, but I never experienced a game breaking bug.
SHIFT series

There are four games in the series, and they all try to ride the wave of Portal’s popularity: a puzzle game with jokey, vaguely antagonistic writing from whoever’s making you solve these puzzles. SHIFT does so with fourth-wall breaking commentary, surrounding the core puzzles.
In retrospect, the puzzle gameplay isn’t that interesting. A lot of the levels have a problem where there’s one clear move at the start, then after you do that there’s another clear move, and another one after that, and then you reach the exit just by going through the motions. But this is kind of a universal puzzle game problem - very few successfully avoid this trap, and the ones that do usually end up being bigger experiences than what you’d expect from a Flash game. I don’t have a problem with it. Later games in the SHIFT series get better about this, by including more branching paths that make trial-and-error more time consuming.
Cursor*10

A game about collaborating with yourself. Best played blind! It’s short, you’ll see how it works.
Ghost Hacker

Ghost Hacker is a tower defense game, and I’ll be honest, it shouldn’t be listed over classics like Bloons Tower Defense or Kingdom Rush. But I like how it’s designed, and fewer people have heard of it.
In Ghost Hacker, your main resource is memory. Placing a tower costs memory, killing enemies gives memory, and you can spend memory on new towers or tower upgrades. The way Ghost Hacker differs is that towers are upgraded through modifiers. For example, in a standard tower defense game, you might have one tower that slows down enemies. In Ghost Hacker, there’s a slow-enemy modifier, which can be applied to any tower. Then it’s up to the player to (for example) realize that you get more utility from your slow-enemy modifier if you attach it to a tower that does splash damage, since it makes the slow apply to everything in splash range.
The other key part of Ghost Hacker’s design is that you can never, ever lose memory. Often, tower defense games will only refund part of the cost if you sell a tower. This can feel really punishing - misplace a tower early, and you either have to settle for the suboptimal placement, or pay a penalty to sell and rebuild the tower where it needs to be. In Ghost Hacker, selling a tower always gives back the full price…eventually. Any time you earn memory, instead of receiving it instantly, you get some of it every tick. In principle, that means you can completely change up and rearrange your towers between waves, as long as you have time to get back your memory and re-spend it. Pretty simple mechanic, but it goes a long way to making the game feel less punishing if you make a bad decision early on.
Fancy Pants Adventure

This is another well-polished platforming game. You can slide, you can wall jump, the levels are really open-ended and filled with collectibles, and at the same time you can beat the game very quickly if you just want to get to the end as fast as possible. And the animation for everything is super smooth. The entire series is worth playing, but I’d say it really hits its stride starting from World 2.
Level Up!

(There’s more than one game named Level Up!, you want the one by Nifty Hat.)
It’s a little hard to categorize this game, but the closest approximation is “platformer collect-a-thon”. As the name suggests, the game is about leveling up, and it does so with a pretty unique system - the more you do something, the better you get at it. If you jump a lot, you learn to jump higher. Run more, and you learn to run faster. Get hit a lot, and you learn to take less damage. Stand in place for a while, and you learn new ways to waste time (unlock new idle animations). It all feels very realistic to real-life learning.
I think the fun of this game is in the discovery, so I’m not going to say much more - just play it.
The sequel teased in the game’s 100% ending was never completed, so don’t go looking for it.
“Meta” Games


A scattering of games that play with game mechanics and tickle my self-referential soft spots.
In no particular order: Upgrade Complete (upgrade all the things!), Achievement Unlocked (unlock all the achievements!), This is the Only Level (finish the same level over and over!), and You Only Live Once (you only live once!). Parts of Achievement Unlocked 2 may not work well with the Flashpoint archive. It would be a spoiler to say what part, but you’ll know what it is once you see it. I didn’t figure out a workaround.
jmtb02 Games


jmtb02 is the dev handle of John Cooney, a prolific Flash game developer who made a lot of games I liked. In retrospect, the reason I like his games is that they usually avoid filler or grinding. It felt like he understood the niche of Flash gaming and made many well-polished short experiences that didn’t try to overstay their welcome.
Achievement Unlocked and This is the Only Level were both by him, and in no particular order I would also recommend Hedgehog Launch, Elephant Quest, Sixty, Exit Path, Soviet Rocket Giraffe, Epic Combo, and Elephant Rave HD.
Don’t Look Back

A game by Terry Cavanagh, who later became well known for VVVVVV, Super Hexagon, and Dicey Dungeons.
Don’t Look Back is a game that tries to express a narrative through gameplay. The controls aren’t that tight, and the difficulty that leads to can be frustrating, but it’s pretty cool when you figure out the story.
Fisher Diver

Fisher Diver is a game by 2DArray, most famous for The Company of Myself. I find it hard to recommend Company of Myself these days - it has one very cool moment, but the rest of the narration doesn’t land for me the same way it did before. However, Fisher Diver does land the same way.
It’s a game about fishing, but I see it more as a commentary about the morality of fishing. You earn money by catching fish. Every time you attack a fish, it costs oxygen and breaks the fish apart. You earn more money if the fish stays intact. The natural conclusion? You should attack just enough to deal a lethal wound, then wait next to the fish and watch it bleed to death. It’s a cold-hearted callousness that’s really different from how a fishing game normally works. At the same time, the game is more true to real-life fishing, so if you feel scummy watching fish die in game…well, food for thought.
The description of a shop upgrade puts it best: “it wouldn’t be hunting if they stood a chance”.
Winnie the Pooh’s Home Run Derby

Okay, I’ll be honest, I haven’t played much of this game. I played enough to confirm the memes about its difficulty, then decided I didn’t want to finish it. This game is horseshit in a way that doesn’t feel fair. I can’t recommend anyone play it for fun, but the memes are excellent. Supposedly the Japanese version is harder - play that one for the full experience!
-
MIT Mystery Hunt 2021
CommentsThis has spoilers for MIT Mystery Hunt 2021, up through the endgame.
I had two reactions at the end of Hunt this year.
- Wow, that hunt was amazing.
- Wow, that hunt was enormous.
The puzzles were all pretty clean. The round structures were inventive. I didn’t find myself drawn into the story very much - I think because it felt like the motivations of the characters changed, but those changes didn’t affect the narrative goals of the solvers. The standout from this year, however, was the overarching Projection Device. It is completely insane that ✈️✈️✈️Galactic Trendsetters✈️✈️✈️ managed to pull off an MMO, and that leads into the 2nd bullet point.
Game development has the worst ratio for time-spent-creating to time-spent-experiencing. Okay, maybe stop motion animation is more time consuming, but game dev is up there. It’s an unholy mixture of animation, programming, environment design, and level design. To make a game world feel immersive, it needs a certain level of detail, which requires creating lots of assets and interactions to fill up the space. Easter eggs like MITHenge didn’t have to be in the game, but on the other hand they kind of did, because it’s those Easter eggs that make players feel rewarded for exploration, outside of just unlocking puzzles. Adding those details take time. Throwing multiplayer into the mix just makes it worse. For Teammate Hunt, we were already sweating at making 8 Playmate games work, and those were limited to 6-player instances. MIT Mystery Hunt was 3x more participants with way more features and a much larger world.

Now, on top of this, Galactic had to…ah, yes, write a record-setting number of puzzles. I mean, I liked a bunch of them. They hit several cultural niches I liked. But last year, I already said I didn’t think the scale of Hunt was sustainable, and now I feel it definitely isn’t sustainable. I realize it’s weird to say this when Galactic just proved they could make it work, but ✈️✈️✈️Galactic Trendsetters✈️✈️✈️ is a team that’s consistently proven they’re willing to bend over backwards and go to insane lengths to make the puzzlehunt they want to make, even if they have to write a conlang or go nuts on interactive content.
I also know that most people on GT don’t have kids, and some were between jobs when they won Mystery Hunt. Those people essentially put their job searches on hold for a year to work full-time on Mystery Hunt, which is great for us, but not something we should treat as normal. I’m not sure what Palindrome’s time looks like, but I suspect Galactic had an abnormally large amount of time to dedicate to Hunt, due to external circumstances. And so when I imagine a Hunt that tops this one…I’m not sure that’s doable, year after year.
MIT Mystery Hunt has grown before - it’s not like it’s always been this big. So let’s play devil’s advocate. Why shouldn’t we just make Hunt bigger? I’d argue that people don’t want to make their teams much bigger. Here’s the team size graph from this year.

Generally, the large teams don’t go far above 100 members. I think this is partly because constructing teams have warned that Hunt may be less fun above 80 people, and partly because logistics and team culture get harder to cultivate after that size. It’s basically Dunbar’s number. Not everyone likes hunting in a large team, and there’s not much room for the large teams to grow. teammate uses a “invite your friends” system, and through friend-of-friend-of-friends we end up with a sizable Mystery Hunt crew. I think this is the first year where we advised people to slow down their invites, because of concerns we were growing too big.
Now, on the other hand, it’s easy to say Hunt should be shorter when you aren’t writing it, but Palindrome has been aiming to win for a long time, is a fairly large team, and therefore probably has a lot of ideas for the Hunt they want to write. It’s up to them. I will say that I don’t think there’s any shame in shooting for a smaller scope than this Hunt.
Pre-Hunt
My pre-Hunt week is normally spent flying into Boston, ruining my productivity for work, and eating at some Cambridge restaurant I only see once a year. None of that was happening this year, so I got a lot more work done - the main challenge was adjusting to a 9 AM start.
This year, since everyone was remote, we spent more time on our remote solver tooling, moving from a heavily scripted master Google Sheet to a mini webapp with Discord integration. There were some rough edges, but it helped a lot. The killer app was that when we unlocked a puzzle, the bot would auto-create text and voice channels, and when we solved a puzzle it would auto-close those channels.
A bunch of teammates got into NERTS! Online before Hunt. It’s fun, and it’s free! You need at least 3 people to make it worthwhile. The game rewards fast, precise mouse movement, so it might not be for you, but if this xkcd speaks to you,
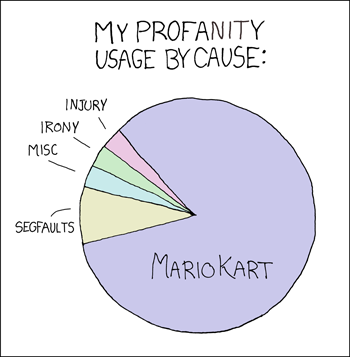
then consider adding Nerts as a new source of good-natured profanity where you scream “NO I NEEDED THAT”.
I was dismayed at the lack of #ambiguous-shitposting this year, so I made a Conspiracies puzzle. I claimed this was to test our new tooling, but no, it was mostly for the conspiracies. We were considering Baba Is You and Doctor Who for the theme. Baba is You was because of Barbara Yew, and Doctor Who was because of the space theme and mention of different dimensions on the Yew Labs website. We also knew people from Galactic had gotten NYT crosswords published for 6/28 (Tau day) and 9/9 (…Cirno day?). Our conspiracies were all garbage. I expected them to be garbage. All is right with the world.
Once the Hunt site opened, we learned automated answer checkers were back, with a rate limit of 3 per 5 minutes across the entire round. Last year, teammate had a much-memed 10% confidence threshold for guessing, and we didn’t think that would work with the new rate-limit. We had some time to hash out our strategy, and decided that any coordination would spend more time than figuring out the throttling if and only if we needed to. So we mostly used a similar system - anyone guess anything you want, and if you’re rate-limited, let the team know and we’ll coordinate it then. This year we suggested a 30% confidence threshold, and that seemed to work fine - we were sometimes rate-limited, but never in an important way.

In practice, there was usually only 1 puzzle per round where people wanted to spam guesses, so the per-round limit was essentially a per-puzzle limit. Looking at guess stats, we made plenty of wrong guesses, but were dethroned from our dubious distinction of most guesses by Cardinality and NES.
While waiting for puzzle release, I decided to poke around the source code. For the record, this was before the warning to never reverse-engineer the Projection Device. I found a solve-sounds.js file, which loaded solve sounds with this code snippet:
const s = round.toLowerCase(); const a = s.charCodeAt(1); const b = s.charCodeAt(2); var h = (a+2*b) % 24; if (ismeta && link[8] == 'e' && h == 14) { h--; } const filename = '/static/audio/' + h + '.mp3';Notably this meant the asset filename was always from 0.mp3 to 23.mp3…and there was no auth layer blocking access to those files, so we could browse all the solve sounds before the puzzles unlocked. Not all the numbers are defined, I’ve left out the dead links in the table below.
1.mp3 2.mp3 3.mp3 4.mp3 5.mp3 6.mp3 7.mp3 8.mp3 9.mp3 10.mp3 11.mp3 12.mp3 13.mp3 14.mp3 22.mp3 The first one I checked was 1.mp3, so you can imagine my surprise when I started hearing Megalovania. The EC residents on our team were more surprised that 13.mp3 was the EC Fire Alarm Remix. We tried to pair solve sounds to round themes, since we had time to burn, and our guesses were kind of right, but mostly wrong.

The solve sounds were all just oblique enough that I didn’t get spoiled on any of the round themes. I also suspect some are either debug sounds, or deliberate red herrings. Of the unused ones, 5.mp3 is You Are a Pirate from Lazy Town, which could map to the Charles River events. 8.mp3 is Super Mario 64 Endless Stairs, which definitely feels like an Infinite Corridor placeholder. 11.mp3 is from Super Mario Galaxy, which is why we were guessing a Mario round, but maybe it was just a space themed placeholder for Giga/Kilo/Milli solves. My pet theory is that it was going to play just for solving Rule of Three, because that meta auto-solved with GALAXY, and a custom solve sound would mark it as important to check out.
I guess this is also a reminder for hunt writers that I’m the kind of person who clicks View Page Source on every hunt website, unless I’m told not to, so let me know early if I shouldn’t. I don’t think the solve sounds leaked much, but from the code we likely could have inferred that East Campus would be a metapuzzle of a future round, if we didn’t get distracted by puzzle release.
Yew Labs
Don’t Let Me Down - I got directed to this puzzle because “OMG, Alex this puzzle has Twilight Sparkle in it!” I checked, and it was much less pony than advertised, but I went “Oh this is the scene where she’s holding on to Tempest Shadow. Oh, that fits the title and the blanks. Alright let’s do this.” It was pretty fast from there.
✏️✉️➡️3️⃣5️⃣1️⃣➖6️⃣6️⃣6️⃣➖6️⃣6️⃣5️⃣5️⃣ - This was a ton of fun. The rate limiting on the text replies got pretty bad, and the optimal strategy would have been for me to move to another puzzle, since each minipuzzle was pretty easy and we only needed like 1-2 texters, but I was having too much fun and needed to see how the emojis were going to end.
By the time we finished that puzzle, we had made good progress on the round, and I was surprised we didn’t have the meta yet. Going into hunt, I wasn’t sure how much Galactic would gate their metas. The intro round made me worried that we’d be hard gated well after we could have figured out the meta if it were open from the start of the round, since we had the mechanic early and just needed the keyboard image to resolve the last bit of uncertainty. This never ended up being an issue for us - at the time of meta unlock, we usually still needed more feeders to solve them. (Aside from Giga/Kilo/Milli, but I’ll get to that later.)
Unmasked - Hey, a Worm puzzle! I saw it was tagged as “worm, parahumans ID”, and was all excited to do IDing, but by the time I got there it was already done. My contribution was reading the flavortext and pointing out we should track the survivors of the Leviathan fight.
A fun bit of Worm trivia: in the debrief meeting before the Leviathan fight, Legend says that statistically, they expect 1 in 4 capes to die. This was real - the author rolled dice for every character, including the protagonist, and wrote the fight around the deaths. No one was safe. If Taylor died, the new protagonist would have been someone in the Wards. If you were ever curious why no one in that fight had plot armor, now you know.
Infinite Corridor
This was my favorite round of the Hunt. It was just so weird. The round technically has 100,000 puzzles, but really those 100,000 puzzles are variations of 5 different types of puzzles. I had a lot of fun cataloguing the differences between different instances of the same puzzle family. I’m also glad I jumped on this round early, because the later in the round we got, the more incomprehensible our discussions were to newcomers.
This round also broke our new puzzle bot. Our Discord server grouped all puzzles for a round into a single category. Each category is limited to 50 channels, but it’s not like we’re going to have a round with over 50 puzzles in it, right?
Cafe Five - There was something vaguely meditative about solving Cafe Five. Nothing complicated, just serve the customers, and do it fast. It is admittedly similar to Race for the Galaxy from GPH 2019, but having comps and less punishing penalties on failure helped make it more fun. We successfully served L. Rafael Reif once, and comped him every other time.
Library of Images - I’m still not sure how we got the right ideas for this puzzle. We were also pretty confused our single letter answer was correct. I understand why after the fact, but good thing we had someone willing to submit H as an answer.
Unchained - We never figured out this puzzle, even when we tried to forward solve it knowing the answer. In retrospect, our main issue was that we weren’t counting the right things, and maybe should have listened to the songs more, rather than just looking at their lyrics.
Make Your Own Word Search - Annoyingly, the Bingo teammate used this year had “Make your own logic puzzle” as a Bingo square, but a word search isn’t a logic puzzle. Our strategy was to unlock 5 different Make Your Own Word Search instances, check all their rules, then solve just the one that seemed easiest. We ended up going for Puzzle 27. (Everyone loves 27. It’s truly the best number, only surpassed by 26.) By aggressively sharing letters between words, we were able to build it with a lot of unused space that was easy to fill, unlocking…
Infinite Corridor Simulator - We started by doing a ton of frequency analysis, which helped us backsolve one of the Unchained instances. I joined the group that tried to reconstruct the Unchained solve, while the other group tried to extract ICS. The Unchained group got stuck and I drifted back to the ICS puzzle, which had figured out 4 of the 5 extractions and was close on the 5th. Our first theory was that we would extract from the digits of pi that Library of Images corresponded to (i.e. first 7 means the answer in the first 7 of pi’s digits), but after figuring out the Library of Images extraction we tried the more obvious thing.
Infinite Corridor - I feel we split up work pretty well on this puzzle. One person wrote a scraper to programmatically build a list of Infinite Corridor puzzles. Around three of us strategized which instances of Library of Images / Cafe Five / etc. to solve. The last group manned the Cafe, since we knew we needed more tokens. Our strategy was to find the 3rd letter of FIRST / SECOND / THIRD / FOURTH / FIFTH, since that uniquely identifies between the five. Then, the 3rd letter of ZERO / ONE / TWO / THREE / SIX / SEVEN / EIGHT / NINE identifies the digit uniquely in 6/10 cases, and only needs one more letter check to clear up the last 4/10 cases.
Unchained was stuck, and we thought solving more Word Searches would take time, so our aim was to get the other 3 digits exactly, narrow the target down to 100 rooms, move to all the rooms in parallel to unlock them, then solve all ICS puzzles in that set of 100. We ended up solving a second strategic Make Your Own Word Search, which narrowed the room set to 40 options, or 8 ICS puzzles in expectation. We found the meta answer on the 3rd one. Unfortunately, since we were solving ICS by script, none of us noticed that room 73178 was an exact replica of the real Infinite Corridor, until Galactic heavily hinted this was true during the final runaround.
I like this round the most because it had this perpetual sense of mystery. How are we going to have several versions of the same puzzle? How would a 100,000 puzzle meta even work? It was neat that the answer got answered recursively, in a way that still left the “true” meta of how to repeat the extraction without solving 100,000 puzzles.
One of the cool things about MIT Mystery Hunt is that you’re continually evaluating what rounds are important / not important to funnel work towards. It was neat that Infinite Corridor was a small version of that kind of planning, embedded within a single round of the Hunt.
We didn’t get the low% clear for fewest solves before Infinite Corridor meta. Puzzkill got there with 1 fewer solve 😞. We did get the first main round meta solve though, and I’m proud of that.
Green Building
Dolphin - A fun puzzle about Gamecube trivia. I helped on the first subpuzzle after we got the a-ha, then set up formulas for the final extraction. We got stuck a bit by assuming we wanted the face that touched the Gamecube, rather than the number that was face-up, but we got there eventually.
Green Building - We got the Tetris a-ha pretty quickly, without the 5-bit binary hint. I think LJUBLJANA was the one that confirmed our suspicions. After doing a few grids, we went down an enormous rabbit hole, where we assumed we would find the number of lines we would attack with if we were following standard Tetrix Battle rules. That number would then become an index. This actually gave okay letters, our partial started AMAR???T????. The Green Building round page was arranged with Switch #1 on the bottom, so we thought we might read 13 to 1 which could give a phrase ending in DRAMA. Indexing by attack into LJUBLJANA gave a J, but the Tetris solution for LJUBLJANA was especially weird, so we thought the answer might go to a switch we didn’t have yet. We were stuck there for hours, and then someone said “hey, have you noticed the first letters of the answers spell CLEAR ALL V”?
We were scheduled for the Green Building interaction right away, and I’m pretty sure I started the Zoom call by saying “I’m so angry”, so if anyone from Galactic is reading this - I wasn’t angry at you! Your meta was fine! I was just salty we overcomplicated it.
Stata Center
Extensive - This was the only puzzle I did in this round. It played well with my skill sets (willingness to try a lot of garbage ideas on technical data). After working at it, we got all the letters except for the MIDI file and DOC file. The DOC file was partially done, and we were half-convinced it didn’t have a 3rd letter, which made our Nutrimatic attempts a lot worse.

I’m thankful that the computational geometry class I took was mildly useful - not because we needed to do any computational geometry, but because it taught me how to read and edit PLY files by hand.
We did have some tech issues around opening the DOC file. I think it was especially pronounced for us because this was a tech puzzle, so the people who self-selected for it were more likely to have Linux. OpenOffice worked for some people and didn’t work for others.
⊥IW.giga/kilo/milli
This round was another one with strange stucture. At each level, the metapuzzle was autosolved on unlock. One puzzle in the round was unsolvable forward, and you need to reconstruct the meta mechanic from the known answer to backsolve that puzzle. That backsolved puzzle then became the presolved metapuzzle for the next level down. The metas were Rule of Three, Twins, Level One, and ⊥IW.nano.
teammate had an unusually easy time with this round. It’s odd to say “unusually easy” when it took our team 12 hours to break through the first level of 8 puzzles, but this was still faster than other teams. This write-up follows the linking used in the solution page - a link to Twins means a discussion about backsolving Twins from Rule of Three.
Twins - I didn’t look at this round until people were trying to backsolve. We had solved every puzzle except Twins and A Routine Matter. Based on Rule of Three auto-solving on unlock, we correctly inferred that Twins needed to be backsolved. Or more specifically, every other puzzle looked forward solvable, and Twins did not. (This did not stop people from trying, but the image was just too small, didn’t have clear steganography inroads, and we were making progress on everything else.)
In my opinion, our solve was very lucky. Based on searching a few of the dates, the team had figured out planetary syzygies, and due to general flavor we suspected the backsolved answer would correspond to Earth. If you read the solution, every syzygy uses either Twins or A Routine Matter…which were exactly the two puzzles we didn’t have. We did, however, have TWIX, and saw it was the center planet for the X in GALAXY. Here is the first stroke of luck - we had errors in our other syzygies, but they weren’t on the X that sparked the later ideas.
Rule of Three didn’t have the image during our solve, so we were flying blind on what to do next. A teammate proposed the “common letters give index” extraction, but wasn’t sure about it. However, someone else noted that if assumed the 2nd letter of A Routine matter was O, then it would extract both the L and A of GALAXY. We pursued it a bit, and got letter constraints G???E* on Twins, at which point someone YOLO-guessed GLOBE and got it.
Maybe that solve doesn’t sound too crazy, but each step taken was an unsteady leap made off another unsteady leap. These leaps are the way to solve puzzles quickly, but they’re also the exact way you jump into the wrong rabbit hole. It was important that we had the answer TWIX, that we didn’t have errors in our data for that syzygy, that we took the proposed extraction mechanism seriously even as the person proposing it later admitted they didn’t think it would work, and that we had someone willing to try low confidence guesses. It’s a very weird situation - normally, at least one person in a solve has conviction in all the mechanics. In our case, it was more like three camps with 1/3rd of the conviction, pooling it together because we didn’t have better ideas.
Button Press - Technically part of the Athletics round, but aside from Building Hacks, this was the only field goal I did during Hunt. I was excited to do more with the Projection Device, but because of how it worked, you had to be first person exploring an area to get the new puzzle unlocks, find new field goals to achieve, etc. I let Infinite Corridor take me and by the time I emerged people had found all the Students we had access to.
How to Run a Puzzlehunt - I think this was a puzzle where I knew too much. I had looked at a ton of gph-site code when writing Teammate Hunt, and somehow argued that the GPH repo wouldn’t have puzzle data, since I didn’t see any new commits and hadn’t noticed anything suspicious in the older ones. We ended up backsolving this one.
Level One - A few of us mentioned sister cities right when we unlocked Twins, but didn’t try it for a while. In particular, I thought sister cities and twin cities were the same thing, but when I learned they were different, I tried twin cities and dropped the thread since I couldn’t get them to work. We tried some crazier extraction ideas, but eventually someone tried sister cities more seriously and it clicked into place. It took writing this post to learn that sister cities are also called twin towns - now I finally get the title! We probably could have solved this from 1 feeder, because once we got sister cities to work for 1 answer we jumped straight to backsolving. We assumed the backsolve city would be Boston or Cambridge so that we could zoom into the MIT.nano building, and only one sister city of the two matches the (3 5) enumeration.
Nutraumatic - I don’t know if there’s a name for this kind of puzzle. I’ve started calling them “figure out the black box” puzzles. They’re usually a good time, they allow for a wide variety of solutions and make it easy for the solver to take ownership of their solve path. Whereas in other puzzle types, your solve path is more pre-ordained, and can be less interesting when you foresee more of it. I think it’s pretty funny that both Mystery Hunt and Teammate Hunt had a puzzle that referenced nutrimatic. To be honest, it’s an absurdly busted tool once you get comfortable with it.
⊥IW.nano - We looked at Level One early, in case it was a puzzle we could get early, like Twins. This was a round where having recent MIT students really helped. We found One.MIT quite early, just based on the title. Then with some metaknowledge, I got the MIT alums. (My thought process was, if we need to backsolve a puzzle, then 1 letter is not sufficient. Therefore, we need semantic information. That semantic information is probably related to MIT - let me see if I can find connections between MIT and BuzzFeed…)
Like other teams, we were quite confused about the enormously long arrow, because it didn’t seem like there was content outside the orange circle. One teammate declared “if they aren’t from the centers, then they’re offsets”, which just did not parse to me, but then they made this image for Paul Krugman:

and I was convinced. Since the backsolve was intended, we assumed the arrow pointing to the Y would come from a famous MIT graduate. Otherwise, the backsolve would be really painful, because it would combine name ambiguity from imprecise arrows, with the semantic ambiguity of finding an answer that fit the flavortext and started with T. That seemed like too many degrees of freedom, so we were pretty confident that if we took our 4 remaining arrows, and checked them in parallel, we’d spot something. We found Feynman, finished the round, and abandoned the remaining puzzles due to the previous argument that the “unintended” backsolves would be too hard. That being said….we definitely should have backsolved Questionable Answers.
Clusters
Somehow, the two puzzles I worked on in this round were the two we got super stuck on. Pain. Too bad I missed Game Ditty Quiz.
Altered Beasts - Okay, this one was my fault. I saw it was Transformers, and mentioned there’s a Transformers: Beast Wars series. Every Transformer in that series has a Beast Mode, and Altered Beasts sure sounded like we should transform the beast mode the same way we transformed the Transformer clues. We had trouble finding unambiguous sources for some of them, which should have tipped us off that this was a red herring, but I thought it was a Powerful Metamorphers scenario, where it was only ambiguous due to unfamiliarity with the source material. Despite proposing the idea, I only knew about Beast Wars because of Hasbro knowledge leaking through MTG and MLP, so I wasn’t much help there. It took us a long, long time to decide the beast modes were fake. On the upside, my red herring managed to pollute two teammates’ recommendation profiles.

Balancing Act - This one, we were just totally stuck on how to be chemists. After spending a hint to get started, it wasn’t too bad.
Clusters - Like some other teams, we thought the grid on the round page would be important, but we couldn’t figure out a principled way to fill in the converted words. To the surprise of no one, it’s hard to solve a puzzle when your extraction is fake. The puzzle titles clearly seemed important, and ordering by those looked okay, but we didn’t know why there was one C and two Ds. A teammate went to take a shower, came back, and said “GUYS THE GREEK ALPHABET GOES ABGDE”, and that fixed everything. Showers: the undefeated champions of inspiration.
Students
I didn’t do this round at all, except for…
Student Center - Our first theory was that this would be about playing cards. There were 54 students, which could map to a deck of 52 cards plus 2 jokers. There were 13 unique clubs. On the round page, the meta order was Dorm Row, Simmons Hall, EAsT camPUS, Random Hall. This order didn’t seem obviously unimportant, and the first letters of their answers spelled CARD.
By that point we were hooked. Groups of 4 could mean a trick taking game! “How can we connect?” could mean a pun on bridge! It all seemed very plausible, especially because we hadn’t connected the four dorm answers to the four Greek elements. We only got to elements after staring at “strangely shaped table” for a while - after all, card game tables use normal shapes.
I didn’t solve it, but one more story about Dorm Row: we solved it without noticing the Game of Thrones connection. With some answer shuffling, one person found that Roar → RICHARDTHEFIRST, Family → RAINBOW, and Winter → WHITEFANG gave letters that looked like DRAGONS. They “just really want dragons to happen, man 🐉”, fixed those 3 answers, and successfully nutrimatic-ed out the answer from the potential assignments of the remaining answers. Thus continues a teammate tradition - every year, there is at least one puzzle we solve without understanding how to solve it.
Tunnels
I was waiting the entire Hunt for Megalovania to show up, and it finally happened! Hooray! This was the round I used the Projection Device for the most, contributing up a map of ghost mechanics for each passageway.
🤔 - Like the solution says, this grid is such garbage, but it’s also beautiful. It’s the simultaneous horror and admiration you get from a Neil Cicierega mashup. All I did was ID the Steamed Hams Puflantu clip, but 10/10 concept.
Bingo - Here’s my reaction when we unlocked this puzzle.

For a while, I had a vague plan to use my Bingo page the next time I got to write for MIT Mystery Hunt. So, finding out I got scooped was incredibly shocking, especially because my Bingo site says it’s not a puzzle. Astute readers will note that my site isn’t a puzzle, but that doesn’t mean the Perpendicular Institute’s Bingo can’t be a puzzle! Fine. FINE. I got trolled, well played. And really, I’m honored my dumb Bingo generator got referenced in a Mystery Hunt.
We usually do science on our team log after Hunt, but it was interesting to do so during Hunt to resolve Bingo statements. At the time we unlocked Bingo, we had already shitposted many, many terrible backsolve attempts for Voltage-Controlled. Seeing “Made more than 27 guesses on a single puzzle.” made us double check how many guesses we’d made on that puzzle. The answer was 28. Hmmmmm.
The QR code extraction evolved naturally for us, but we had trouble getting it to scan. Our eventual solve was done by splitting questions into three tiers: statements that had to be TRUE/FALSE to fit QR code structure, statements that were TRUE/FALSE due to concrete examples, and statements that we believed were TRUE/FALSE, but hadn’t exhaustively verified. Then we split up and randomly toggled statements from the 3rd tier in parallel, until the code scanned. I got the eventual solve, which made me happy. My one complaint is that we had “Puzzle about Among Us” marked as TRUE, because IDing it was one question in Cafe Five, but it needed to be FALSE. It was in the 1st tier, so it wasn’t too big an issue, but I think it subconsciously made me ignore Cafe Five when considering the other statements.
It’s Tricky - There was a call for people who knew how the Tunnels ghosts worked. I joined, noticed a few matches right away, and recruited help from other Tunnels navigators. We then kinda commandeered the puzzle and stole ownership until it finished. The first two letters I got were K and Z, so I really wasn’t sure we were doing the right thing - luckily the next letters we got looked much better.
Also psssst go watch the TikTok we submitted, it’s so good.
Foundation’s Collection - All I did for this puzzle was link the GOOD SMILE company webpage with a comment that “this looks weeb as f***”, then I dipped to work on something else, because I swear I’m not a weeb. (No, seriously, I haven’t watched anime in 3 years, and the ones I have watched are pretty basic. The only one that isn’t is Bokurano, which is a MESSED UP anime, just incredibly unsettling, but it has some interesting thoughts on morality and mortality and…look, I hit peak anime watching in high school and then stopped afterwards, okay?)
Tunnels - I encouraged a lot of Undertale tinfoil hatting on this meta. We had the answer FLOWER GIRL, so I was definitely looking into some Flowey stuff, checking the number of Undertale endings, wondering if it was RGB due to red stop signs / green circles / blue eyes from Sans, etc. All garbage!
Interactions
Every time we finished a main round, we got an interaction with Hunt staff. I expect these to show up on the Hunt site later, but here are some quick notes for the ones I went to.
Students - I joined this one partway through, so not sure of the details, but I believe we needed to solve each dorm’s problem using the element it was associated to. All I know is that I joined the Zoom call and someone was arguing that using Firefox to search for wood was a good way to help EC’s troubles with their RANDOM LUMBER GENERATOR.
Green Building - To clear all the vines, we needed to play a game of Tetris, where team members posed as the piece we wanted to spawn. I for one was very excited to T-pose our way to victory.
Infinite Corridor - To hire a contractor, we needed to look them up in a phone book with a rather weird sorting mechanism. This took us a lot longer than we expected, and at some point it became a meme that we should hire a contractor whenever we got stuck in a future interaction. After all, we can hire a contractor to do anything!
Athletics - This was a game of Just One, flavored as one person catching the ball and everyone else throwing. The email recommended 10 people. We had 40. Playing Just One in a group of 40 people was a complete disaster and totally worth it.
⊥IW.nano - We played a real-life text adventure, similar to getting Ryan North out of the hole, in order to pass objects from ⊥IW.giga down to ⊥IW.nano. I really wanted to crack a joke about the portals DMK key puzzle in Problem Sleuth, because it was basically that, but IDK how many people would get it.
Stata Center - To iron out the inks, we needed to bring out our irons. We had some real irons, then it devolved into forks that are definitely made of iron, pieces of paper that said Fe on them, etc. I own a life size Iron Sword from Minecraft (won it from a hackathon), so my contribution was wildly waving a sword that was definitely made of iron, not foam.
Clusters - In this one, the Athena and Minerva clusters each spoke different “languages”, and didn’t like each other’s names. We first needed to figure out their languages, which were similar to Pig Latin, except parsing a spoken Pig Latin variant is harder than it sounds. Once we figured out the language, we needed to ask them questions in their language, to figure out why they didn’t like each other’s name, and come up with a name both of them liked. That ended up being Kerberos, a punny answer on many levels.
Tunnels - This was a game of Keep Puzzling and The Tunnels Will be Fixed. The participants were split into two separate Zoom rooms. One group got the puzzle data, and the other group got the puzzle solution, without the data. Periodically, the group with the solution was allowed to send a small number of characters to describe the solution, which the other group needed to parse to figure out how to extract. The communication started at 5 characters, then got bigger if your team needed it.
Closing Thoughts
Not only did we solve the Bingo puzzle, we got a triple Bingo on our real Bingo board! The third Bingo relied on “Metapuzzle solved with fewer than half the answers”, which I violently argued was true for Infinite Corridor, given that we used < 50000 answers. Then we got it for real in Nano, so it wasn’t up for debate.
Funnily enough, I felt I got more out of the MIT part of MIT Mystery Hunt this year, despite the Hunt running remotely. teammate normally has plenty of MIT affiliation, so I usually defer on-campus puzzles to people who actually know MIT campus. In this Hunt, it still helped to know the MIT layout…but there was also a minimap. Seriously, the minimap probably 3x-ed my enjoyment of the Projection Device, I would have been so lost without it, and referring to it so often meant I learned the real MIT campus layout a bit better. Why can’t real life have fast travel, and maps that work well when your phone is indoors :(
I had a great time, and hopefully next year the world will be in a good enough place to run Hunt in person. It’s hard to say for sure…but I think it should be. Until next time.


Oh, one last thing…

TAME MEAT LIVES!!!!!